Général
La course aux paquets uniques : comment briser la limite des 65535 octets !
Posted on August 2, 2024 • 12 minutes • 2429 words Table of contents Introduction TL;DR Limitation of single-packet attack Fragmentation of IP packet TCP and Sequence Number First Sequence Sync Combining IP fragmentation and First Sequence Sync Limiting factors Demonstration Further Improvements Conclusion Shameless plug Introduction Hello, I’m RyotaK (@ryotkak ), a security engineer at Flatt

Présentation
Dans le domaine de la cybersécurité, une technique innovante a récemment émergé. En 2023, James Kettle de PortSwigger a publié un article marquant intitulé Smashing the state machine: the true potential of web race conditions. Dans ce document, il a introduit une méthode d’attaque novatrice, connue sous le nom d’attaque à paquet unique, capable d’exploiter une condition de course sans être affectée par les variations du réseau.
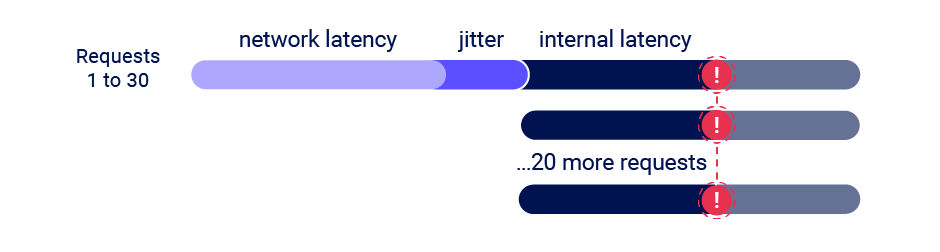
Récemment, j’ai rencontré une condition de course de type dépassement de limite nécessitant l’envoi d’environ 10 000 requêtes simultanément pour être exploitée de manière fiable. J’ai donc tenté d’appliquer l’attaque à paquet unique à cette situation. Cependant, en raison de la contrainte de cette méthode, qui limite la taille maximale des requêtes à environ 1 500 octets, je n’ai pas pu exploiter la vulnérabilité.
Face à ce défi, j’ai commencé à chercher des solutions pour contourner cette limitation. J’ai découvert une méthode permettant d’étendre la contrainte de 1 500 octets de l’attaque à paquet unique, ainsi que la limite de 65 535 octets du protocole TCP. Dans cet article, je vais expliquer comment j’ai réussi à dépasser les limites habituelles de l’attaque à paquet unique et discuter des différentes manières de l’exploiter.
Résumé
Pour surmonter la contrainte de l’attaque à paquet unique, j’ai utilisé la fragmentation IP et le réarrangement des numéros de séquence TCP.
En utilisant la fragmentation au niveau IP, un seul paquet TCP peut être divisé en plusieurs paquets IP, permettant ainsi une utilisation optimale de la taille de la fenêtre TCP. De plus, en réorganisant les numéros de séquence TCP, j’ai empêché le serveur cible de traiter l’un des paquets TCP jusqu’à ce que je…
Limites de l’attaque à paquet unique
Bien que l’attaque à paquet unique soit une technique puissante, elle présente des limites notables. La restriction de taille de 1 500 octets peut poser un problème dans des scénarios où des données plus volumineuses doivent être envoyées. Cela nécessite des approches alternatives pour contourner cette contrainte.
Fragmentation des paquets IP
La fragmentation IP est une méthode qui permet de diviser un paquet en plusieurs segments plus petits, facilitant ainsi leur transmission à travers le réseau. Cette technique est essentielle pour maximiser l’utilisation de la bande passante et contourner les limitations de taille des paquets.
TCP et Numéro de Séquence
Le protocole TCP utilise des numéros de séquence pour assurer l’ordre des paquets. En manipulant ces numéros, il est possible de contrôler la manière dont les paquets sont traités par le serveur, ce qui peut être exploité pour des attaques plus efficaces.
Synchronisation de la Première Séquence
La synchronisation des séquences est cruciale pour garantir que les paquets arrivent dans le bon ordre. Cela peut être réalisé en ajustant les numéros de séquence de manière stratégique, permettant ainsi une exploitation plus efficace des vulnérabilités.
Combinaison de la Fragmentation IP et de la Synchronisation de la Première Séquence
En combinant la fragmentation IP avec la synchronisation des numéros de séquence, il est possible de créer une méthode d’attaque robuste qui surmonte les limitations des techniques traditionnelles. Cette approche permet d’envoyer des données plus volumineuses tout en maintenant le contrôle sur l’ordre de traitement des paquets.
Facteurs Limitants
Malgré les avancées réalisées, plusieurs facteurs peuvent limiter l’efficacité de cette méthode. Des éléments tels que la latence du réseau, la configuration du serveur cible et les mesures de sécurité mises en place peuvent influencer le succès de l’attaque.
Démonstration
Pour illustrer l’efficacité de cette technique, une démonstration pratique peut être réalisée. Cela permet de mettre en évidence les avantages de la combinaison de la fragmentation IP et de la synchronisation des séquences dans un environnement contrôlé.
Améliorations Supplémentaires
Il existe plusieurs pistes d’amélioration pour optimiser cette méthode d’attaque. L’exploration de nouvelles techniques de manipulation des paquets et l’adaptation aux évolutions des protocoles de sécurité sont essentielles pour rester en avance sur les défenses mises en place.
Conclusion
l’attaque à paquet unique, bien qu’efficace, présente des limitations qui peuvent être surmontées par des techniques telles que la fragmentation IP et le réarrangement des numéros de séquence. Ces méthodes offrent de nouvelles perspectives pour exploiter les vulnérabilités des systèmes, tout en soulignant l’importance d’une vigilance constante dans le domaine de la cybersécurité.
Grâce à ces méthodes, il est possible d’exploiter de manière significative une vulnérabilité mineure de dépassement de limite, ce qui peut entraîner des failles graves, telles que le contournement de l’authentification par jeton unique. Lors des tests, j’ai réussi à envoyer 10 000 requêtes en environ 166 ms.
Limitations des attaques à un seul paquet
Comme l’a souligné James dans son article sur l’attaque à un seul paquet, cette méthode limite le nombre de requêtes pouvant être synchronisées à environ 20-30 requêtes :
Le TCP a une limite douce de 1 500 octets, et je n'ai jamais exploré comment dépasser cela, car 20-30 requêtes suffisent pour la plupart des conditions de concurrence.En raison de cette contrainte, il est difficile d’exploiter des scénarios où l’on pourrait contourner la limitation de débit, par exemple, dans le cas de l’authentification par jeton unique, même si le jeton ne contient que des chiffres. En effet, il est probable que l’on ne puisse envoyer que 20-30 requêtes, même en contournant la limitation de débit.
Fragmentation des paquets IP
Pour comprendre la limite de 1 500 octets de l’attaque à un seul paquet, il est essentiel de saisir la relation entre le cadre Ethernet, le paquet IP et le paquet TCP.
Lorsqu’un paquet TCP est envoyé sur Ethernet, il est encapsulé dans un paquet IP, qui lui-même est encapsulé dans un cadre Ethernet :
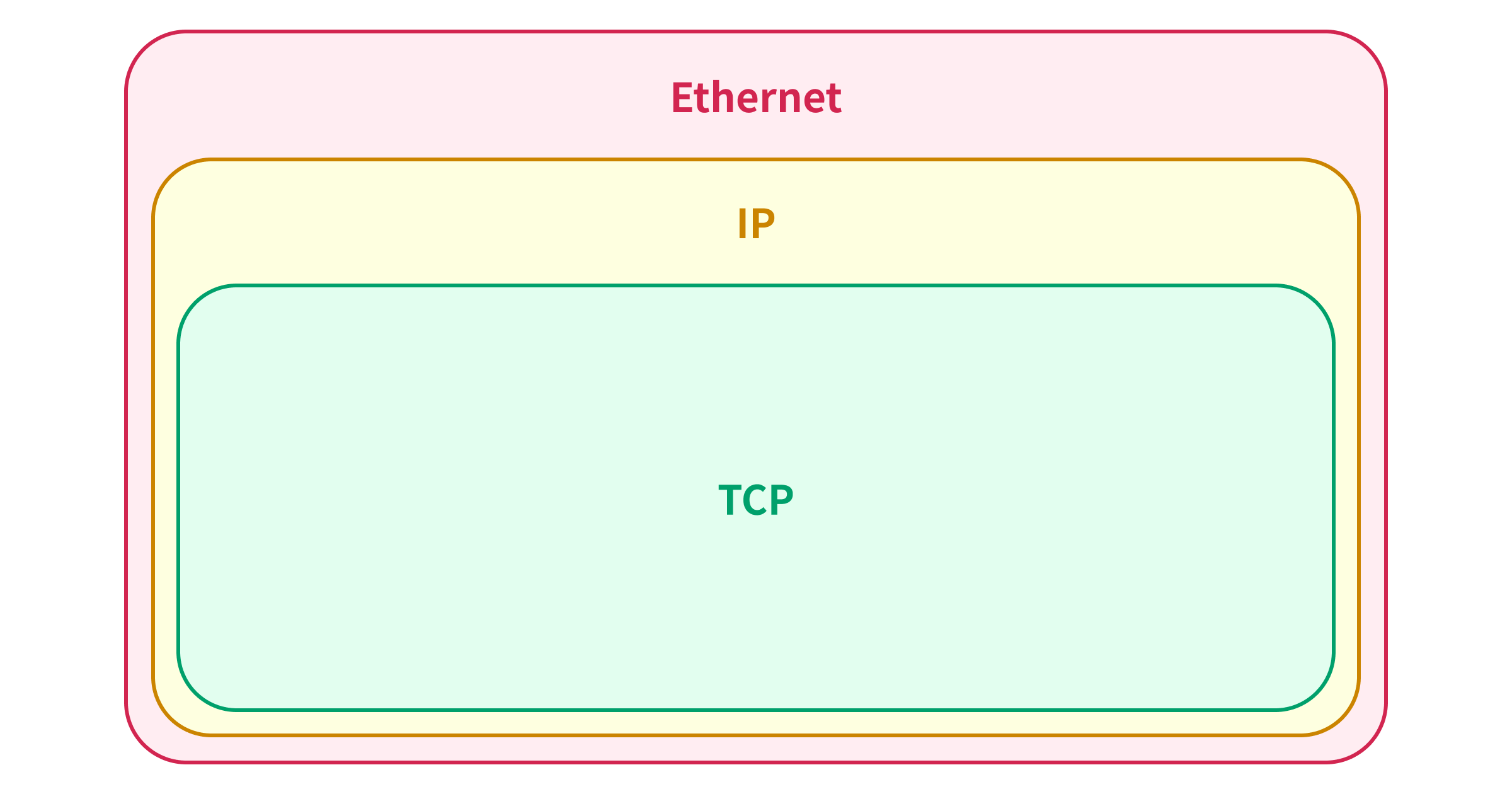
La taille maximale d’un cadre Ethernet est de 1 518 octets, incluant l’en-tête Ethernet (14 octets) et la séquence de vérification de cadre (4 octets), ce qui signifie que la taille maximale d’un paquet IP pouvant être encapsulé dans un seul cadre Ethernet est de 1 500 octets.1
C’est pourquoi James a mentionné 1 500 octets comme une limite douce pour le TCP. Mais pourquoi le TCP permet-il une taille maximale de 65 535 octets pour le paquet TCP alors que le paquet IP est limité à 1 500 octets ?
En réalité, le paquet IP prend en charge la fragmentation, comme défini dans le RFC 791.
La fragmentation d'un datagramme Internet est nécessaire lorsqu'il provient d'un réseau local qui autorise une grande taille de paquet et doit traverser un réseau local qui limite les paquets à une taille plus petite pour atteindre sa destination.Lorsque le paquet IP est fragmenté, le paquet IP d’origine est divisé en plusieurs paquets IP plus petits, chacun étant encapsulé dans des cadres Ethernet différents.
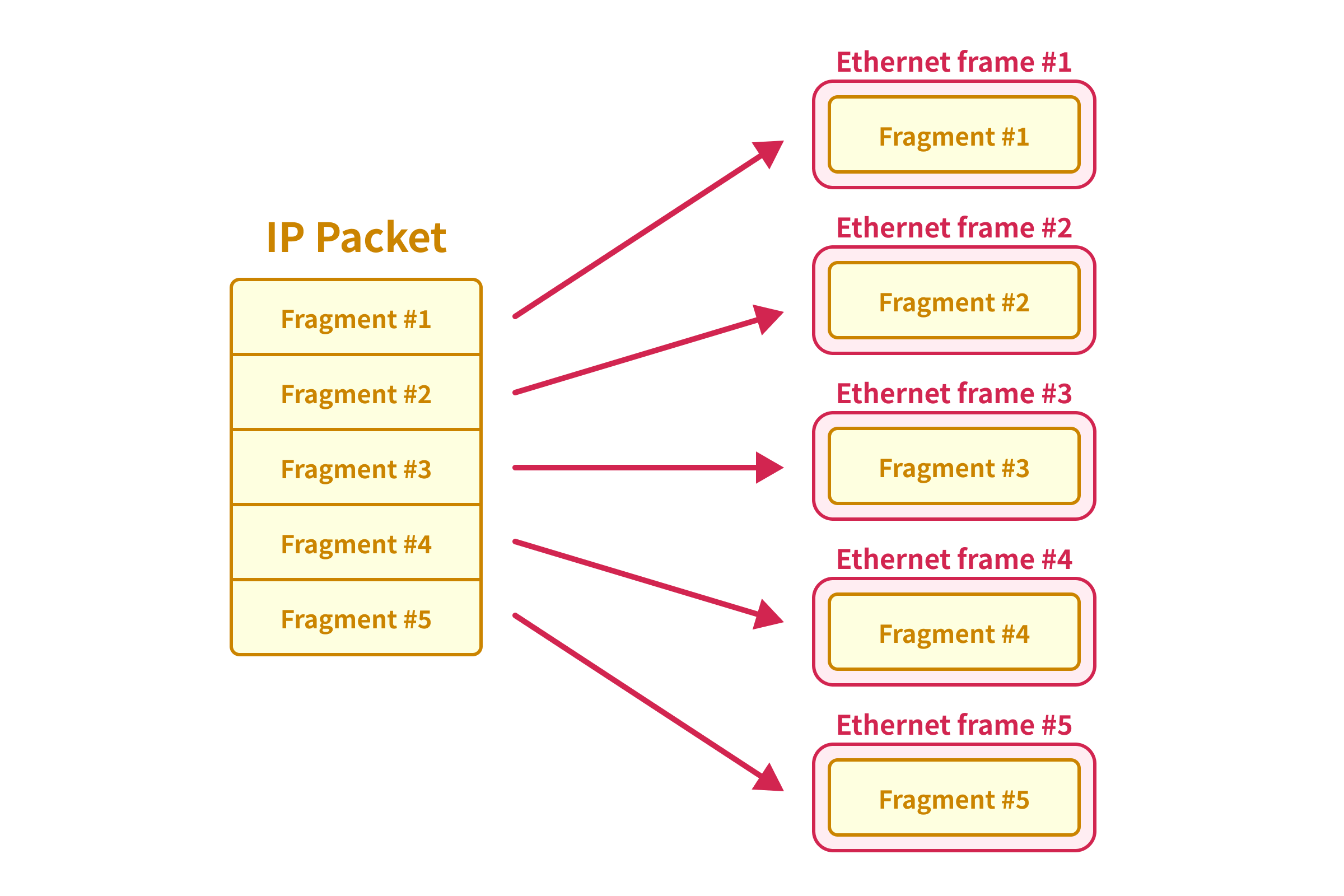
Étant donné que le paquet IP fragmenté ne sera pas transmis à la couche TCP tant que tous les fragments ne seront pas reçus, nous pouvons synchroniser un grand paquet TCP même si nous le divisons en plusieurs paquets IP.
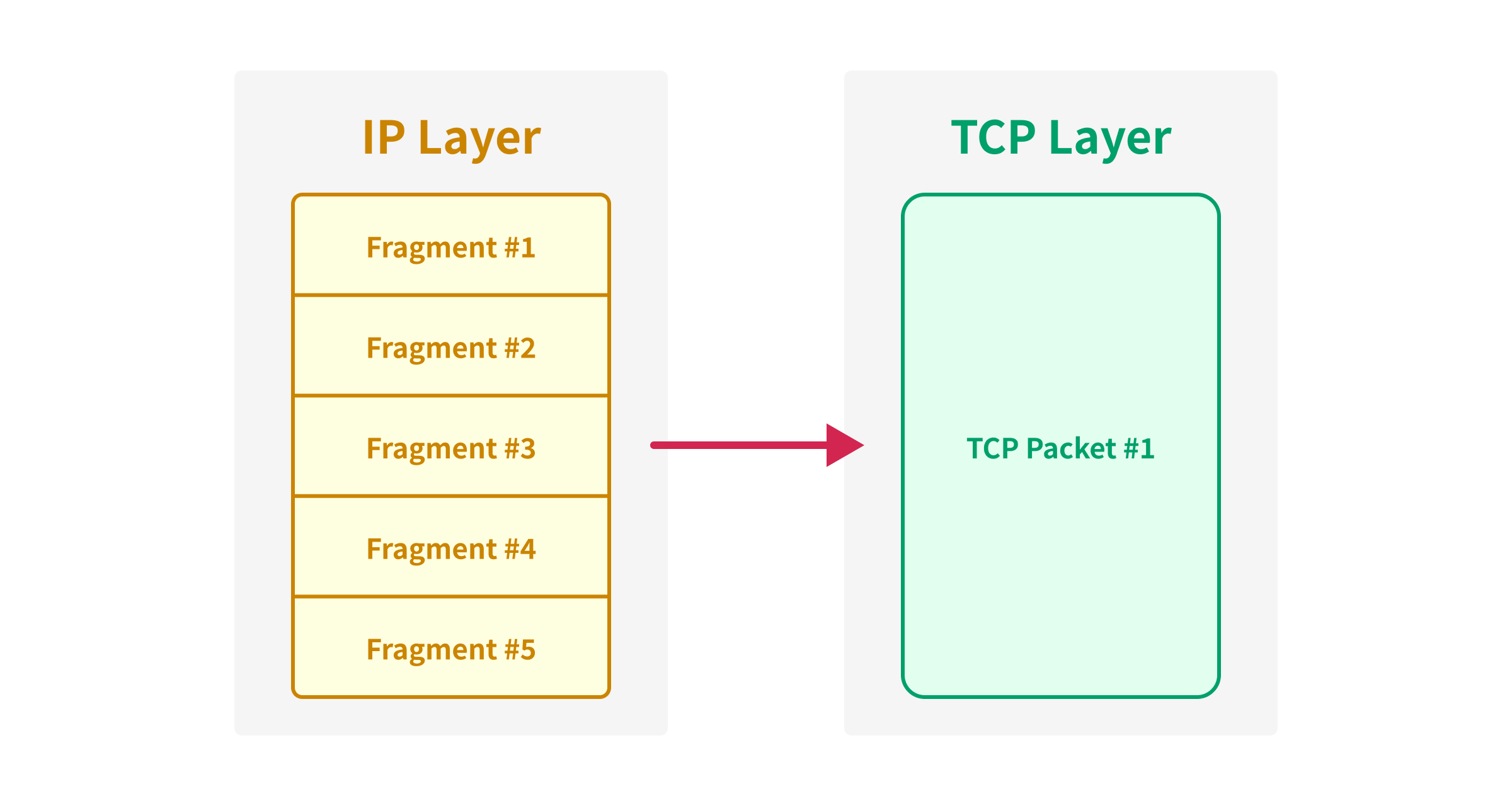
TCP et Numéro de Séquence
Nous pouvons maintenant envoyer un paquet TCP allant jusqu’à 65 535 octets2 en utilisant la fragmentation IP, mais cela reste insuffisant lorsque nous souhaitons envoyer un grand nombre de requêtes simultanément.
Étant donné que nous utilisons désormais pleinement la taille de la fenêtre TCP, nous ne pouvons pas étendre la limite davantage avec un seul paquet TCP, il nous faut donc trouver comment synchroniser plusieurs paquets TCP.
Heureusement, le TCP garantit l’ordre des paquets grâce au numéro de séquence. Lorsque le serveur cible reçoit le paquet TCP, il vérifie le numéro de séquence et réorganise les paquets en fonction de ce numéro.
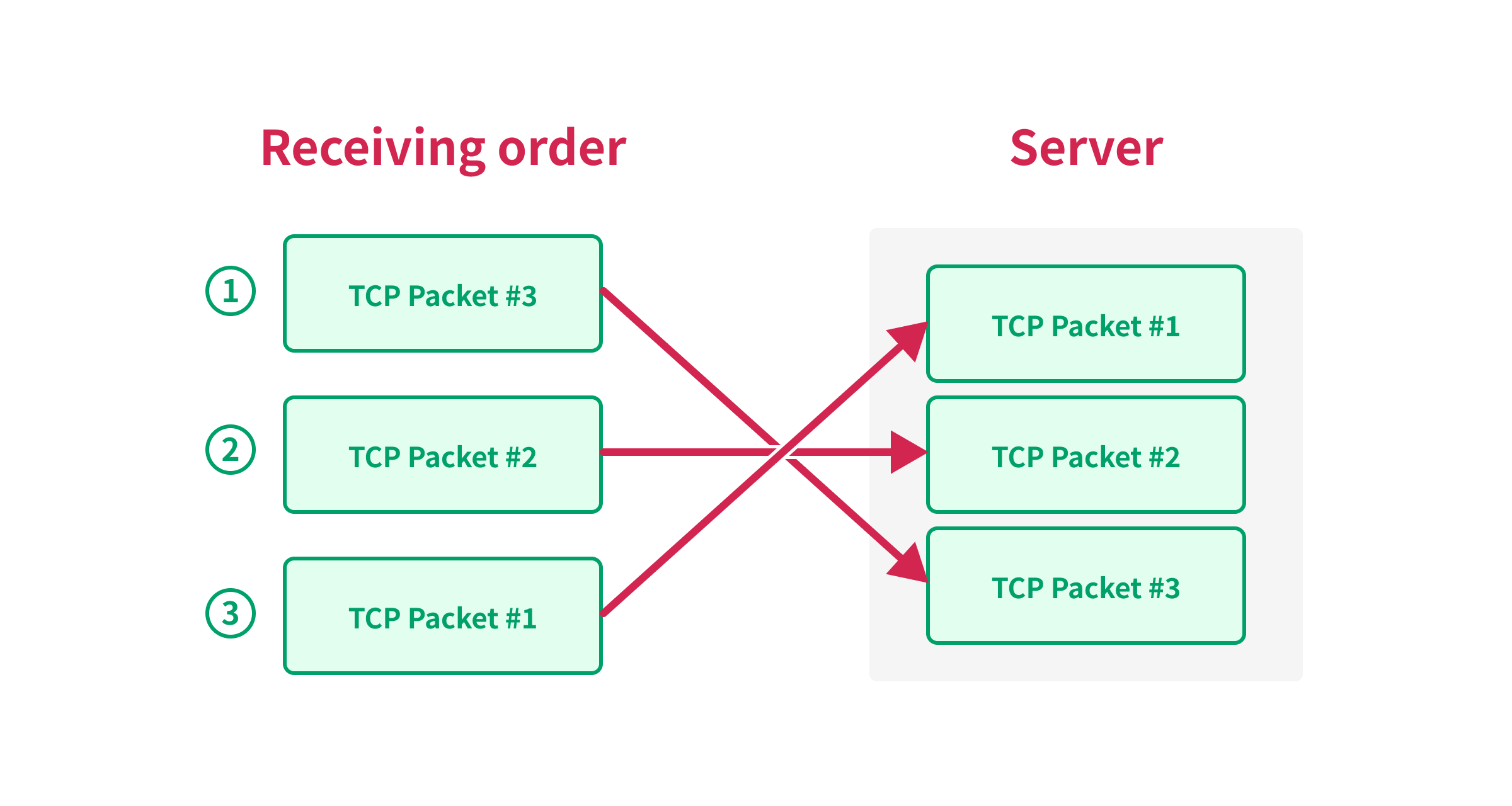
Une manière naturelle de penser au traitement des segments entrants est d'imaginer qu'ils sont d'abord testés pour leur numéro de séquence approprié (c'est-à-dire que leur contenu se situe dans la plage de la "fenêtre de réception" attendue dans l'espace des numéros de séquence) et ensuite qu'ils sont généralement mis en file d'attente et traités dans l'ordre des numéros de séquence.Synchronisation du Premier Numéro de Séquence
Étant donné que le TCP garantit l’ordre des paquets, nous pouvons utiliser le numéro de séquence pour synchroniser plusieurs paquets TCP. Par exemple, considérons les paquets TCP suivants à envoyer :
| Paquet | Numéro de Séquence |
|---|---|
| A | 1 |
| B | 2 |
| C | 3 |
Si le serveur reçoit les paquets dans l’ordre B, C et A, il ne pourra pas traiter les paquets tant qu’il n’aura pas reçu le paquet A, car le serveur doit traiter les paquets dans l’ordre des numéros de séquence.
En utilisant ce comportement, nous pouvons empêcher le serveur de traiter les paquets jusqu’à ce que nous envoyions le dernier paquet, qui contient le premier numéro de séquence. Ainsi, nous pouvons forcer le serveur à traiter les paquets simultanément en envoyant le paquet avec le premier numéro de séquence en dernier.
Combinaison de la Fragmentation IP et de la Synchronisation du Premier Numéro de Séquence
En combinant la fragmentation IP et la synchronisation du premier numéro de séquence, nous pouvons désormais envoyer de nombreuses grandes requêtes simultanément sans nous soucier de la taille des requêtes. Voici un aperçu du flux des techniques :
Tout d’abord, le client établit une connexion TCP avec le serveur et ouvre des flux HTTP/2, puis envoie les données de requête, à l’exception du dernier octet de chaque requête. À ce stade, l’application attend que le client envoie les octets restants des requêtes, de sorte que les requêtes ne sont pas encore traitées.
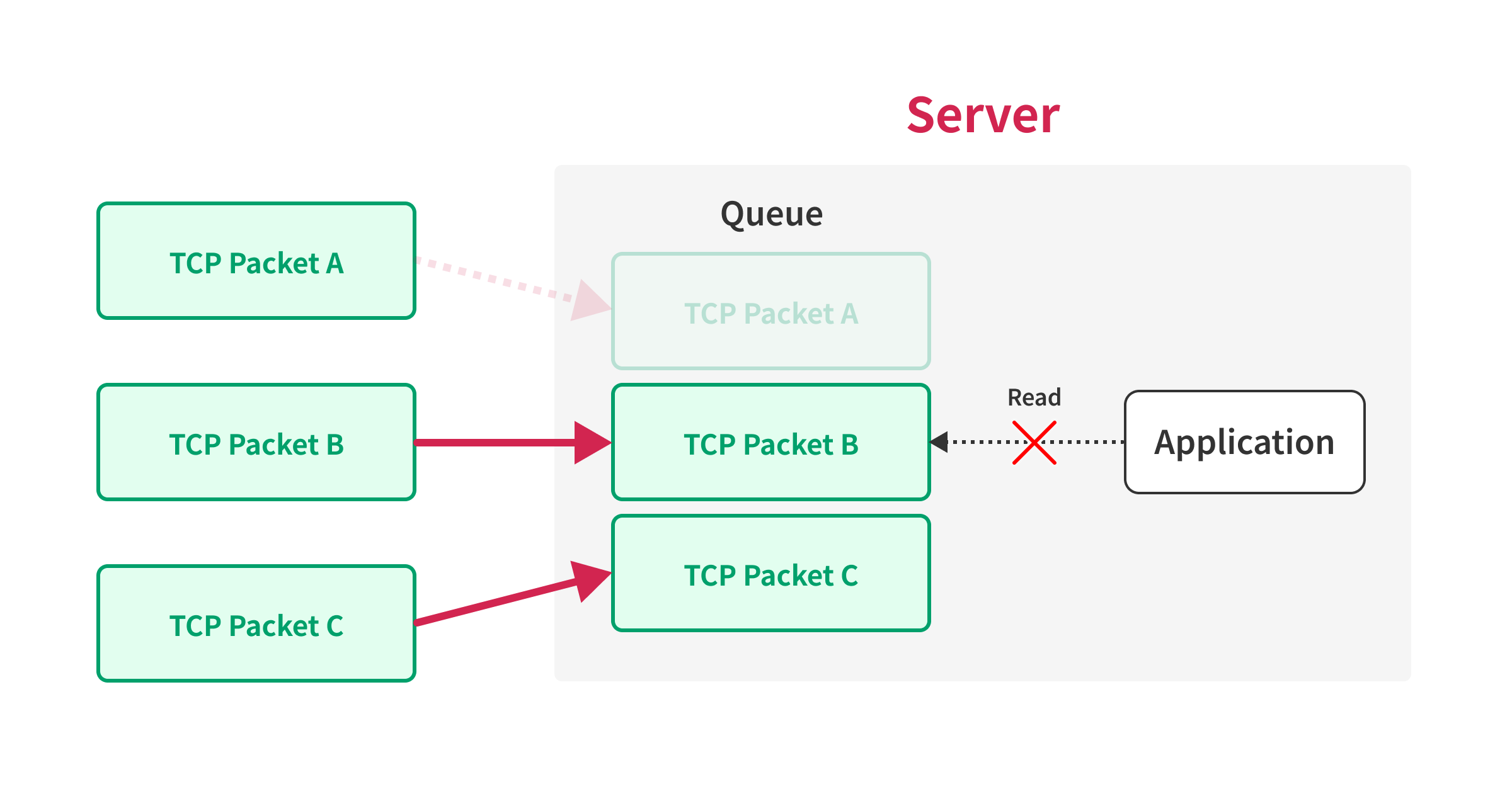
Lorsqu’un client envoie des requêtes, il commence par créer de grands paquets TCP qui contiennent plusieurs trames HTTP/2, à l’exception du dernier octet des requêtes. Ces paquets sont ensuite transmis au serveur via une fragmentation IP. Le paquet TCP contenant le premier numéro de séquence est exclu. Une fois que le serveur reçoit ces paquets dans un ordre différent, il attend la réception du dernier paquet avant de transmettre les données à l’application.
Une fois que le serveur a reçu tous les paquets mentionnés, le client envoie le paquet TCP avec le premier numéro de séquence, permettant ainsi au serveur de traiter toutes les requêtes simultanément.
Facteurs limitants
Bien que cette méthode semble efficace, plusieurs éléments peuvent influencer le nombre de requêtes pouvant être envoyées en parallèle.
Un facteur évident est la taille du tampon TCP du serveur. Étant donné que le serveur doit conserver les paquets dans le tampon jusqu’à ce qu’ils soient réassemblés, il est essentiel que ce tampon soit suffisamment grand pour gérer les paquets reçus dans le désordre.
Heureusement, la plupart des serveurs modernes disposent d’une RAM conséquente, et la plupart des systèmes d’exploitation sont configurés par défaut avec des tampons adéquats, ce qui fait que la taille du tampon n’est généralement pas un problème majeur.
Cependant, un autre facteur peut également limiter le nombre de requêtes simultanées. Dans le protocole HTTP/2, le nombre de flux pouvant être ouverts en même temps est restreint par le paramètre SETTINGS_MAX_CONCURRENT_STREAMS. Par exemple, si ce paramètre est fixé à 100, le serveur ne peut traiter que 100 requêtes simultanément sur une seule connexion TCP.
Cela pose un problème crucial lorsque nous tentons d’appliquer les techniques décrites ici, car il est nécessaire d’envoyer les requêtes dans une seule connexion TCP pour utiliser la synchronisation du premier numéro de séquence.
Malheureusement, des serveurs HTTP populaires comme Apache et Nginx imposent des limites strictes sur le paramètre SETTINGS_MAX_CONCURRENT_STREAMS :
| Implémentation | Valeur par défaut SETTINGS_MAX_CONCURRENT_STREAMS |
|---|---|
| Apache httpd | 100 |
| Nginx | 128 |
| Go | 250 |
Il est à noter que la RFC 9113 définit la valeur initiale de SETTINGS_MAX_CONCURRENT_STREAMS comme illimitée, et certaines implémentations offrent des limites généreuses :
| Implémentation | Valeur par défaut SETTINGS_MAX_CONCURRENT_STREAMS |
|---|---|
| nghttp2 | 4294967295 |
| Node.js | 4294967295 |
Ainsi, les techniques abordées dans cet article pourraient s’avérer très efficaces selon l’implémentation HTTP/2 utilisée par le serveur.
Démonstration
Dans cette section, je vais évaluer les performances de la synchronisation du premier numéro de séquence et montrer à quoi ressemble l’exploitation de la vulnérabilité de dépassement de limite.
Pour cette démonstration, j’ai utilisé l’environnement suivant :
| Serveur | Client | |
|---|---|---|
| Plateforme | AWS EC2 | AWS EC2 |
| Système d’exploitation | Amazon Linux 2023 | Amazon Linux 2023 |
| Version du noyau | 6.1.91 | 6.1.91 |
| Type d’instance | c5a.4xlarge | t2.micro |
| Région | sa-east-1 | ap-northeast-1 |
Ces serveurs sont situés presque aux antipodes l’un de l’autre, avec une latence réseau d’environ 250 ms.
J’ai configuré les iptables de la machine cliente pour empêcher l’envoi de paquets RST au serveur :
iptables -A OUTPUT -p tcp --tcp-flags RST RST -s [IP] -j DROPDans un premier temps, je vais synchroniser 10 000 requêtes en utilisant la synchronisation du premier numéro de séquence et mesurer le temps nécessaire pour envoyer ces requêtes. Le code utilisé pour cette évaluation est disponible dans le dossier rc-benchmark du dépôt.
Voici les résultats du test de performance :
| Métriques | Valeur |
|---|---|
| Temps total | 166460500ns |
| Temps moyen entre les requêtes | 16647ns |
| Temps maximum entre les requêtes | 553627ns |
| Temps médian entre les requêtes | 14221ns |
| Temps minimum entre les requêtes | 220ns |
Comme vous pouvez le constater, j’ai réussi à envoyer 10 000 requêtes en environ 166 ms. Cela correspond à 0,0166 ms par requête, ce qui est extrêmement rapide, surtout lorsque l’on considère que la latence réseau entre les serveurs est d’environ 250 ms.
Je vais maintenant illustrer l’exploitation d’une vulnérabilité de dépassement de limite dans l’authentification par jeton unique. Le code utilisé pour cette démonstration est disponible dans le dossier rc-pin-bypass du dépôt.
Bien que le logiciel du serveur cible limite le nombre maximum de tentatives d’authentification à 5, la machine cliente a pu effectuer 1 000 tentatives, contournant ainsi la limitation de débit. En comparaison, lors d’une attaque similaire avec la synchronisation du dernier octet, seulement environ 10 tentatives étaient possibles, ce qui rend cette méthode beaucoup plus fiable et efficace.
Améliorations Supplémentaires
Bien que la démonstration ait été concluante, plusieurs améliorations pourraient rendre l’attaque encore plus fiable et efficace. Voici quelques suggestions :
- Prise en charge de HTTPS : Le PoC actuel nécessite le support de HTTP/2 sur une connexion non chiffrée, ce que certaines implémentations ne permettent pas, car le navigateur ne supporte HTTP/2 que sur TLS. En intégrant le support TLS, nous pourrions appliquer ces techniques à un plus large éventail de cibles.
- Gestion des mises à jour de la fenêtre TCP par le serveur cible : L’implémentation actuelle ne prend pas en compte le cas où le serveur cible met à jour la fenêtre TCP pendant l’envoi des requêtes. Avec le PoC actuel, l’attaque échouera probablement si le serveur cible effectue cette mise à jour.
- Intégration avec des outils proxy existants : Le PoC actuel manque de flexibilité et nécessite des modifications du code pour ajouter des en-têtes ou modifier le corps de la requête. En intégrant des outils proxy comme Burp Suite ou Caido, nous pourrions facilement ajuster les requêtes et les en-têtes.
- Veuillez noter que cela pourrait ne pas être possible, car ces techniques reposent sur les couches 3 et 4 du modèle OSI, tandis que les outils proxy sont conçus pour fonctionner sur la couche 7.
Conclusion
Dans cet article, j’ai présenté une technique que j’ai nommée Synchronisation de Première Séquence pour contourner les limitations des attaques par paquet unique. Ces techniques peuvent s’avérer très puissantes selon l’implémentation de HTTP/2 utilisée par le serveur et sont particulièrement utiles pour exploiter des vulnérabilités de dépassement de limite qui sont difficiles à exploiter avec des méthodes traditionnelles.
Bien que cette technique puisse encore être perfectionnée, je la trouve déjà très précieuse pour exploiter des vulnérabilités autrement inaccessibles. En fait, j’ai réussi à exploiter la vulnérabilité mentionnée précédemment, et j’espère que vous pourrez également obtenir des résultats similaires. J’attends également avec impatience de voir de nouveaux outils intégrant ces techniques.
Promotion
Chez Flatt Security, nous nous spécialisons dans l’évaluation de la sécurité et les services de tests d’intrusion de haute qualité. Pour célébrer le lancement de nos nouvelles pages web en anglais, nous offrons actuellement une enquête d’un mois par nos ingénieurs d’élite pour seulement 40 000 $ !
Nous proposons également un outil d’évaluation de la sécurité puissant appelé Shisho Cloud, qui combine la gestion de la posture de sécurité dans le cloud (CSPM) et la gestion des droits d’accès à l’infrastructure cloud (CIEM) avec des tests de sécurité d’applications dynamiques (DAST) pour les applications web.
Si vous souhaitez en savoir plus, n’hésitez pas à nous contacter à l’adresse suivante : https://flatt.tech/en.






Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Business
Une formidable nouvelle pour les conducteurs de voitures électriques !
Excellente nouvelle pour les conducteurs de véhicules électriques ! La recharge gratuite sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Annoncée par le ministère de l’Économie, cette mesure incitative, en place depuis 2020, s’inscrit dans une dynamique de croissance impressionnante avec une progression annuelle moyenne de 35%. Les entreprises peuvent ainsi offrir des bornes de recharge sans impact fiscal, stimulant la transition écologique. Reste à savoir si cela suffira à convaincre les entreprises hésitantes et à propulser l’électrification des flottes professionnelles vers un avenir durable.

Technologie
Recharge Électrique au Bureau : Une Exonération Fiscale Renouvelée
Les détenteurs de véhicules électriques et leurs employeurs peuvent se réjouir : la possibilité d’effectuer des recharges gratuites sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Cette décision, annoncée par le ministère des Finances, prolonge une initiative lancée en 2020 pour encourager l’adoption des véhicules électriques dans les entreprises.
Un Secteur en Croissance Dynamique
Cette prolongation intervient à un moment clé, alors que le marché des voitures électriques continue d’afficher une croissance remarquable. Entre 2020 et 2022, la progression annuelle moyenne a atteint 35%. En 2023, les particuliers représentent désormais 84% des acquisitions de véhicules électriques, contre seulement 68% en 2018.
Concrètement,cette mesure permet aux sociétés d’installer gratuitement des bornes de recharge pour leurs employés sans impact fiscal. Les frais liés à l’électricité pour ces recharges ne seront pas pris en compte dans le calcul des avantages en nature. De plus, un abattement de 50% sur ces avantages est maintenu avec un plafond révisé à environ 2000 euros pour l’année prochaine.
Accélération Vers une Mobilité Électrique
Cette initiative fait partie d’une stratégie globale visant à promouvoir l’électrification du parc automobile français. Cependant, les grandes entreprises rencontrent encore des difficultés pour atteindre leurs objectifs ; seulement 8% des nouveaux véhicules immatriculés par ces entités étaient électriques en 2023. Ces incitations fiscales pourraient néanmoins inciter davantage d’employeurs à franchir le pas.Cependant, plusieurs défis demeurent concernant les infrastructures nécessaires au chargement ainsi que sur l’autonomie des véhicules et les perceptions parmi les employés. Par ailleurs, la réduction progressive du bonus écologique pour les utilitaires et sa diminution pour les particuliers pourraient freiner cet élan vers une adoption plus large.
Avenir Prometteur Pour La Mobilité Électrique
Malgré ces obstacles potentiels, il existe un optimisme quant au futur de la mobilité électrique dans le milieu professionnel. Les avancées technologiques continues ainsi qu’un engagement croissant envers la durabilité devraient continuer à favoriser cette tendance vers une adoption accrue des véhicules écologiques.
En maintenant ces mesures fiscales avantageuses jusqu’en 2025 et au-delà, le gouvernement délivre un message fort soutenant la transition écologique dans le secteur du transport. Reste maintenant à voir si cela suffira réellement à convaincre certaines entreprises hésitantes et si cela permettra d’accélérer significativement l’électrification de leurs flottes professionnelles dans un avenir proche.
Divertissement
« À la rencontre d’un Hugo : une aventure inattendue »
Le prénom, un véritable reflet de notre identité, peut être à la fois lourd à porter et source de fierté. Dans cette chronique fascinante, le réalisateur Hugo David nous plonge dans son expérience avec un prénom très répandu. Né en 2000, il se retrouve entouré d’autres Hugo, ce qui l’amène à adopter un alias : Hugo D.. Comment ce choix a-t-il influencé son parcours ? Explorez les nuances et les histoires derrière nos prénoms et découvrez comment ils façonnent nos vies dès l’enfance jusqu’à l’âge adulte !

Les Prénoms : Un Voyage au Cœur de l’Identité
Le Rôle Crucial des Prénoms dans nos Existences
Chaque personne possède un prénom, qu’il soit courant ou singulier, et ce dernier peut engendrer à la fois fierté et embarras. Cet article explore la signification profonde et l’influence des prénoms sur notre vie quotidienne. Le réalisateur Hugo David partage son vécu avec un prénom qui a connu une forte popularité durant sa jeunesse.
une Naissance Sous le Signe de la Célébrité
Hugo David est né en 2000 à Tours, une époque où le prénom Hugo était en plein essor. Ses parents, Caroline et Rodolphe, avaient envisagé d’autres choix comme Enzo, également très en vogue à cette période. « Je pense que mes parents ont opté pour un prénom parmi les plus répandus en France plutôt qu’en hommage à Victor Hugo », confie-t-il.
Une Enfance Entourée d’Autres « Hugo »
Dès son plus jeune âge, Hugo se retrouve entouré d’autres enfants portant le même nom. Selon les statistiques de l’Insee,7 694 garçons ont été prénommés Hugo en 2000,faisant de ce prénom le quatrième plus populaire cette année-là. À l’école primaire,il côtoie plusieurs camarades appelés Thibault et autres prénoms similaires. Pour éviter toute confusion lors des appels en classe, les enseignants ajoutent souvent la première lettre du nom de famille après le prénom : ainsi devient-il rapidement « Hugo D. », un surnom auquel il s’habitue sans arduousé.
Pensées sur l’Identité Associée au Prénom
Le choix d’un prénom peut avoir un impact significatif sur notre identité personnelle tout au long de notre existence. Que ce soit pour se distinguer ou pour s’intégrer dans un groupe social spécifique, chaque individu développe une relation particulière avec son propre nom.
les prénoms ne sont pas simplement des désignations ; ils portent avec eux des récits et influencent nos interactions sociales depuis notre enfance jusqu’à l’âge adulte.
-
 Business2 ans ago
Business2 ans agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoLes meilleures offres du MacBook Pro ce mois-ci !