Général
Les modèles d’IA s’effondrent lorsqu’ils sont formés sur des données générées de manière récursive : un phénomène fascinant à explorer !
Main The development of LLMs is very involved and requires large quantities of training data. Yet, although current LLMs2,4,5,6, including GPT-3, were trained on predominantly human-generated text, this may change. If the training data of most future models are also scraped from the web, then they will inevitably train on data produced by their predecessors.
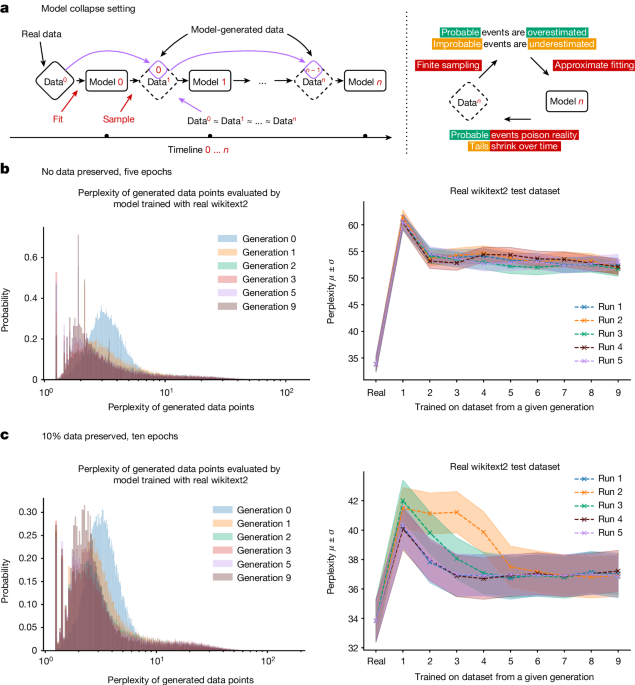
Introduction
La création de modèles de langage de grande taille (LLM) est un processus complexe qui nécessite d’importantes quantités de données d’entraînement. Bien que les LLM actuels, tels que GPT-3, aient été principalement formés sur des textes générés par des humains, cette tendance pourrait évoluer. Si la majorité des futurs modèles sont également alimentés par des données extraites du web, ils risquent d’apprendre à partir de contenus produits par leurs prédécesseurs. Cet article explore les conséquences lorsque des textes générés par une version de GPT constituent la majeure partie des ensembles de données d’entraînement des modèles suivants. Que se passe-t-il lorsque l’on augmente le nombre de générations, noté GPT-{n} ? Nous découvrons que l’apprentissage indiscriminé à partir de données produites par d’autres modèles entraîne un phénomène appelé « effondrement du modèle » — un processus dégénératif où, au fil du temps, les modèles perdent la compréhension de la véritable distribution des données, même sans changement dans cette distribution. Nous fournissons des exemples d’effondrement de modèle pour les modèles de mélange gaussien (GMM), les autoencodeurs variationnels (VAE) et les LLM. Nous démontrons que, avec le temps, les modèles commencent à perdre des informations sur la distribution réelle, ce qui commence par la disparition des queues de distribution, et les comportements appris convergent vers une estimation ponctuelle avec une variance très faible. De plus, nous prouvons que ce processus est inévitable, même dans des conditions presque idéales pour l’apprentissage à long terme, c’est-à-dire sans erreur d’estimation de fonction. Nous mentionnons également brièvement deux concepts proches de l’effondrement du modèle issus de la littérature existante : l’oubli catastrophique dans le cadre de l’apprentissage continu sans tâche et l’empoisonnement des données, qui peut entraîner des comportements non intentionnels. Bien qu’aucun de ces concepts ne puisse expliquer pleinement le phénomène d’effondrement du modèle, ils offrent une perspective supplémentaire sur ce phénomène observé et sont discutés plus en détail dans les Matériaux Supplémentaires. Enfin, nous examinons les implications plus larges de l’effondrement du modèle. Nous soulignons que l’accès à la distribution de données d’origine est essentiel : dans les tâches d’apprentissage où les queues de la distribution sous-jacente sont importantes, il est nécessaire d’accéder à des données réellement produites par des humains. En d’autres termes, l’utilisation à grande échelle des LLM pour publier du contenu sur Internet risque de polluer l’ensemble de données destiné à former leurs successeurs : les données concernant les interactions humaines avec les LLM deviendront de plus en plus précieuses.
Comprendre l’effondrement du modèle
Définition 2.1 (effondrement du modèle)
L’effondrement du modèle est un processus dégénératif qui affecte les générations de modèles génératifs appris, où les données qu’ils génèrent finissent par polluer l’ensemble d’entraînement de la génération suivante. En étant formés sur des données polluées, ces modèles perçoivent alors mal la réalité. Ce processus est illustré dans la Fig. 1a. Nous distinguons deux cas particuliers : l’effondrement précoce et l’effondrement tardif du modèle. Dans l’effondrement précoce, le modèle commence à perdre des informations sur les queues de la distribution ; dans l’effondrement tardif, le modèle converge vers une distribution qui ressemble peu à l’originale, souvent avec une variance considérablement réduite.
Ce phénomène résulte de trois sources d’erreur spécifiques qui se cumulent au fil des générations et provoquent une déviation par rapport au modèle d’origine :
-
Erreur d’approximation statistique. Il s’agit du type d’erreur principal, qui survient en raison du nombre fini d’échantillons, et qui disparaît lorsque le nombre d’échantillons tend vers l’infini. Cela se produit en raison d’une probabilité non nulle que des informations puissent être perdues à chaque étape de rééchantillonnage.
-
Erreur d’expressivité fonctionnelle. Ce type d’erreur secondaire découle de l’expressivité limitée des approximateurs de fonction. En particulier, les réseaux neuronaux ne sont des approximateurs universels que lorsque leur taille tend vers l’infini. Par conséquent, un réseau neuronal peut introduire une probabilité non nulle en dehors du support de la distribution d’origine ou une probabilité nulle à l’intérieur de ce support. Un exemple simple de cette erreur d’expressivité serait de tenter d’ajuster un mélange de deux gaussiennes avec une seule gaussienne. Même avec des informations parfaites sur la distribution des données, des erreurs de modèle seront inévitables. Cependant, en l’absence des deux autres types d’erreurs, cela ne peut se produire qu’à la première génération.
-
Erreur d’approximation fonctionnelle. Ce type d’erreur secondaire provient principalement des limitations des procédures d’apprentissage, par exemple, le biais structurel de la descente de gradient stochastique ou le choix de l’objectif. Cette erreur peut être considérée comme survenant dans la limite de données infinies et d’expressivité parfaite à chaque génération.
Chacune des erreurs mentionnées ci-dessus peut aggraver ou atténuer l’effondrement du modèle. Une plus grande puissance d’approximation peut même être une arme à double tranchant : une meilleure expressivité peut contrer le bruit statistique, entraînant une bonne approximation de la distribution réelle, mais elle peut également aggraver le bruit. Souvent, nous observons un effet en cascade, où des inexactitudes individuelles se combinent pour faire croître l’erreur globale. Par exemple, un surajustement du modèle de densité peut amener le modèle à extrapoler incorrectement et à attribuer des régions de haute densité à des régions de faible densité non couvertes dans le support de l’ensemble d’entraînement ; celles-ci seront alors échantillonnées avec une fréquence arbitraire. Il convient de noter qu’il existe d’autres types d’erreurs. Par exemple, les ordinateurs ont une précision limitée en pratique. Nous allons maintenant aborder l’intuition mathématique pour expliquer comment ces erreurs se manifestent, comment différentes sources peuvent se cumuler et comment nous pouvons quantifier la divergence moyenne du modèle.
Intuition théorique
Nous proposons ici une intuition théorique pour le phénomène d’effondrement du modèle. Nous soutenons que le processus d’effondrement du modèle est universel parmi les modèles génératifs qui s’entraînent de manière récursive sur des données générées par des générations précédentes. Nous quantifions les sources d’erreurs discutées dans la section précédente en examinant deux modèles mathématiques, qui s’avèrent suffisamment simples pour fournir des expressions analytiques pour des quantités d’intérêt, tout en illustrant également le phénomène d’effondrement du modèle : une distribution discrète en l’absence d’erreurs d’expressivité fonctionnelle et d’approximation, et une approximation gaussienne multidimensionnelle, illustrant l’expressivité fonctionnelle conjointe et les erreurs statistiques. Nous illustrons également l’impact des trois sources d’erreur dans un cadre plus complexe d’estimation de densité dans des espaces de Hilbert dans les Matériaux Supplémentaires.
Le processus stochastique global que nous considérons, que nous appelons apprentissage avec des données générationnelles, est le suivant. L’ensemble de données à la génération i est ({{mathcal{D}}}_{i}), comprenant des variables aléatoires indépendantes et identiquement distribuées ({X}_{j}^{i}) avec distribution pi, où j ∈ {1,…, Mi} désigne la taille de l’ensemble de données. En passant de la génération i à la génération i +&thin;1, nous visons à estimer la distribution des échantillons dans ({{mathcal{D}}}_{i}), avec une approximation ({p}_{{theta }_{i+1}}). Cette étape est ce que nous appelons l’approximation fonctionnelle, ({p}_{{theta }_{i+1}}={{mathcal{F}}}_{theta }({p}_{i})). L’ensemble de données ({{mathcal{D}}}_{i+1}) est ensuite généré en échantillonnant à partir de ({p}_{i+1}={alpha }_{i}{p}_{{theta }_{i+1}}+{beta }_{i}{p}_{i}+{gamma }_{i}.
Effondrement des modèles dans les modèles linguistiques
Dans cette section, nous analysons l’impact de l’effondrement des modèles sur les modèles linguistiques. Nous aborderons également des modèles d’apprentissage automatique plus interprétables, tels que les VAEs et les GMMs, dans les Matériaux Supplémentaires. Le code est disponible publiquement dans la référence 13.
L’effondrement des modèles est un phénomène qui se manifeste dans diverses familles de modèles d’apprentissage automatique. Cependant, alors que des modèles plus petits comme les GMMs et les VAEs sont généralement entraînés à partir de zéro, les modèles de langage (LLMs) se distinguent. Leur coût de réentraînement à partir de zéro est si élevé qu’ils sont souvent initialisés avec des modèles pré-entraînés tels que BERT4, RoBERTa5 ou GPT-2 (réf. 2), qui ont été formés sur de vastes corpus de texte. Par la suite, ils sont affinés pour diverses tâches en aval14.
Nous examinons ici ce qui se passe avec les modèles linguistiques lorsqu’ils sont successivement affinés avec des données générées par d’autres modèles. Nous pouvons facilement reproduire toutes les expériences couvertes dans cet article avec des modèles linguistiques plus grands dans des contextes non d’affinage pour démontrer l’effondrement des modèles. Étant donné qu’entraîner un seul modèle de taille modérée produit l’équivalent de deux fois la quantité de CO2 émise par un Américain au cours de sa vie (réf. 15), nous avons choisi de ne pas réaliser une telle expérience et de nous concentrer plutôt sur un cadre plus réaliste pour prouver le concept. Il convient de noter que même les expériences linguistiques décrites dans cet article ont nécessité des semaines d’exécution. Nous évaluons le cadre le plus courant pour l’entraînement d’un modèle linguistique : un affinage.
Optimisation des Modèles de Langage : Une Approche Innovante
Dans le cadre de l’entraînement des modèles de langage, chaque cycle débute avec un modèle pré-entraîné enrichi de données récentes. Ces données proviennent d’un autre modèle pré-entraîné, affiné pour des performances optimales. Étant donné que l’entraînement est conçu pour produire des modèles proches de l’original, les points de données générés par ces modèles entraînent généralement des gradients très faibles. Ainsi, on peut s’attendre à ce que le modèle subisse des modifications modérées après l’affinage. Pour cette étude, nous avons affiné le modèle de langage causal OPT-125m, mis à disposition par Meta via Hugging Face.
Entraînement sur le Jeu de Données Wikitext2
Nous avons affiné le modèle sur le jeu de données wikitext2. Pour la génération de données à partir des modèles entraînés, nous avons utilisé une recherche par faisceau à cinq voies. Les séquences d’entraînement sont limitées à 64 tokens ; pour chaque séquence de tokens dans l’ensemble d’entraînement, nous demandons au modèle de prédire les 64 tokens suivants. En parcourant l’ensemble de données d’origine, nous produisons un ensemble de données artificiel de taille équivalente. Si le modèle ne commettait aucune erreur, il reproduirait l’ensemble de données wikitext2 d’origine. Chaque génération débute avec des données d’entraînement réelles, et chaque expérience est répétée cinq fois, les résultats étant présentés comme cinq exécutions distinctes avec des graines de randomisation différentes. Le modèle original, affiné avec des données wikitext2 réelles, atteint une perplexité moyenne de 34, contre une base de zéro coup de 115, ce qui indique qu’il a réussi à apprendre la tâche.
Configurations d’Entraînement
Nous avons exploré deux configurations d’entraînement distinctes :
-
Cinq époques, sans données d’entraînement originales : Dans cette configuration, le modèle est entraîné pendant cinq époques en utilisant l’ensemble de données d’origine, mais sans conserver de données originales pour les générations suivantes. La performance globale de la tâche d’origine est illustrée dans la Figure 1b. Nous avons constaté que l’entraînement avec des données générées permet d’adapter le modèle à la tâche sous-jacente, entraînant une perte de performance de 20 à 28 points de perplexité.
-
Dix époques, 10 % des données d’entraînement originales préservées : Ici, le modèle est entraîné pendant dix époques sur l’ensemble de données d’origine, tout en échantillonnant aléatoirement 10 % des points de données d’origine à chaque nouvelle génération. La performance globale de la tâche d’origine est présentée dans la Figure 1c. La préservation des données originales permet un meilleur affinage du modèle, entraînant une dégradation de performance mineure.
Résultats et Observations
Les deux régimes d’entraînement ont conduit à une dégradation des performances de nos modèles. Cependant, nous avons observé que l’apprentissage avec des données générées est réalisable et que les modèles peuvent apprendre (certaines) des tâches sous-jacentes. En particulier, les figures 1 et leurs versions 3D dans les Matériaux Supplémentaires montrent que l’effondrement du modèle se produit, car la densité des échantillons avec une faible perplexité commence à s’accumuler au fil des générations. Cela rend probable que, au fil des générations, les données échantillonnées s’effondrent également en une fonction delta.
Mécanisme de Rétroaction dans le Processus d’Apprentissage
Il est essentiel de noter que le comportement observé est conforme à l’intuition générale établie dans la section « Intuition Théorique ». En effet, dans toutes les expériences, l’apprentissage générationnel n’est effectué que sur un nombre fini (généralement petit) de générations, tandis que les affirmations de la section « Intuition Théorique » sont principalement présentées dans la limite où le nombre de générations tend vers l’infini. Cependant, comme le montrent les expériences sur les VAE et les GMM dans les Matériaux Supplémentaires, la convergence vers des fonctions delta et les taux spécifiques de cette convergence sont étroitement liés aux spécificités du problème considéré, et un effondrement complet peut se produire ou non, même après un petit nombre d’étapes.
Analyse des Données Générées
Les figures 1b et 1c montrent à gauche des histogrammes des perplexités des points de données individuels générés par les modèles de différentes générations, évalués par le premier modèle développé avec des données d’entraînement wikitext2 réelles. Au fil des générations, les modèles tendent à produire davantage de séquences que le modèle original produirait avec une probabilité plus élevée. Cet effet observé est similaire à celui décrit pour les VAE et les GMM dans les Matériaux Supplémentaires, où, au fil des générations, les modèles ont commencé à produire des échantillons qui seraient générés avec des probabilités plus élevées par le modèle original. En même temps, nous découvrons que les données générées présentent des queues beaucoup plus longues, suggérant que certaines données ne seraient jamais produites par le modèle original, ce qui représente les erreurs qui s’accumulent en raison de l’apprentissage avec des données générationnelles.
Exemple de Dégradation du Modèle
Un exemple des sorties textuelles d’un modèle OPT-125m affecté par l’effondrement du modèle : les modèles se dégradent au fil des générations, chaque nouvelle génération étant entraînée sur des données produites par la génération précédente.
-
Entrée : certains ont commencé avant 1360 — était généralement accompli par un maître maçon et une petite équipe de maçons itinérants, complétés par des ouvriers locaux, selon Poyntz Wright.
Comprendre l’effondrement des modèles de langage
Dans le domaine de l’intelligence artificielle, l’effondrement des modèles de langage (LLMs) est un phénomène préoccupant qui mérite une attention particulière. Alors que certains chercheurs soutiennent que les églises paroissiales ont été conçues par des architectes influents en s’inspirant des premiers exemples de l’architecture perpendiculaire, d’autres remettent en question cette théorie.
Exemples d’architecture perpendiculaire
Les réalisations architecturales telles que la cathédrale Saint-Jean à Londres illustrent le renouveau de l’architecture perpendiculaire. Un exemple marquant de cette renaissance est l’église Notre-Dame de Guernesey, construite à la fin du XIXe siècle, qui représente l’un des premiers exemples de cette tendance. On distingue deux catégories d’églises perpendiculaires, chacune ayant ses propres caractéristiques.
Les défis des modèles de langage
Les recherches montrent que les modèles de langage génèrent souvent des phrases répétitives, un problème qui a été observé dans presque tous les modèles de génération de texte. Pour atténuer ce phénomène, des expériences numériques ont été menées, où les modèles étaient incités à produire des séquences non répétitives. Cependant, cette approche a conduit à des résultats moins satisfaisants, car les modèles ont commencé à générer des séquences moins probables, augmentant ainsi leur vulnérabilité à l’effondrement.
Conséquences de l’effondrement des modèles
Les implications de l’effondrement des modèles de langage sur les dynamiques d’apprentissage sont significatives. Les attaques de contamination à long terme sur ces modèles ne sont pas une nouveauté. Des pratiques telles que la création de fermes de clics et de contenu ont déjà eu un impact négatif sur les résultats de recherche, entraînant des modifications dans les algorithmes de recherche. Par exemple, Google a commencé à privilégier le contenu provenant de sources fiables, tandis que DuckDuckGo a choisi de supprimer complètement ces contenus.
Importance de la préservation des données
Il est crucial de préserver la capacité des LLMs à modéliser des événements peu probables, car ces événements sont souvent pertinents pour les groupes marginalisés. De plus, ils sont essentiels pour comprendre des systèmes complexes. Nos évaluations suggèrent qu’il existe un « avantage du premier arrivé » lors de l’entraînement de modèles comme les LLMs. En effet, l’entraînement sur des échantillons provenant d’un autre modèle génératif peut induire un changement de distribution, entraînant à terme un effondrement du modèle.
Questions sur la provenance des données
La nécessité de distinguer les données générées par les LLMs de celles provenant d’autres sources soulève des questions sur la provenance du contenu extrait d’Internet. Il est essentiel de coordonner les efforts au sein de la communauté pour garantir que toutes les parties impliquées dans la création et le déploiement des LLMs partagent les informations nécessaires pour résoudre ces questions. Sans cela, il pourrait devenir de plus en plus difficile d’entraîner de nouvelles versions des LLMs sans accès aux données collectées avant l’adoption massive de cette technologie.
Disponibilité des données et du code
Les codes de génération de données pour les expériences GMM sont disponibles dans les références. Les données utilisées pour les expériences VAE et LLM sont également accessibles dans les publications respectives.
Références
- Radford, A. et al. Les modèles de langage sont des apprenants multitâches non supervisés. Blog OpenAI 1, 9 (2019).
- Brown, T. et al. Les modèles de langage sont des apprenants à quelques exemples. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Les Modèles de Langage et leur Impact sur l’Intelligence Artificielle
Introduction aux Modèles de Langage
Les modèles de langage, en particulier ceux basés sur des architectures avancées comme les transformateurs, ont révolutionné le domaine de l’intelligence artificielle (IA). Ces systèmes, capables de comprendre et de générer du texte de manière cohérente, sont devenus des outils essentiels dans divers secteurs, allant de la recherche académique à l’assistance virtuelle.
Évolution des Modèles de Langage
L’émergence de modèles tels que BERT et GPT a marqué un tournant dans la manière dont les machines traitent le langage naturel. Par exemple, le modèle GPT-4, développé par OpenAI, a démontré des capacités impressionnantes en matière de compréhension contextuelle et de génération de texte. Selon des études récentes, ces modèles peuvent désormais atteindre des niveaux de performance comparables à ceux des humains dans certaines tâches linguistiques.
Applications Pratiques
Les applications des modèles de langage sont vastes. Dans le secteur de la santé, par exemple, des systèmes d’IA sont utilisés pour analyser des rapports médicaux et aider au diagnostic. De plus, dans le domaine de l’éducation, des outils basés sur ces modèles facilitent l’apprentissage personnalisé en adaptant le contenu aux besoins spécifiques des étudiants.
Défis et Considérations Éthiques
Malgré leurs avantages, l’utilisation de modèles de langage soulève des préoccupations éthiques. Les biais présents dans les données d’entraînement peuvent se traduire par des résultats discriminatoires. Par conséquent, il est crucial de développer des méthodes pour atténuer ces biais et garantir que les systèmes d’IA soient justes et équitables.
Perspectives Futures
L’avenir des modèles de langage semble prometteur, avec des recherches en cours pour améliorer leur robustesse et leur adaptabilité. Des initiatives visant à rendre ces technologies plus accessibles et transparentes sont également en cours, ce qui pourrait transformer la manière dont nous interagissons avec l’IA.
Conclusion
Les modèles de langage représentent une avancée significative dans le domaine de l’intelligence artificielle. En continuant à explorer leurs capacités et à aborder les défis éthiques associés, nous pouvons tirer parti de ces technologies pour améliorer divers aspects de notre vie quotidienne.
À propos de cet article
Ce document présente des recherches innovantes dans le domaine de l’intelligence artificielle, en mettant l’accent sur les modèles de langage et les techniques d’apprentissage automatique. Les auteurs ont exploré des approches variées pour améliorer la compréhension et la génération de texte par les machines.
Contributions des auteurs
Ilia Shumailov et Zakhar Shumaylov ont été à l’origine de l’idée, dirigeant la recherche ainsi que le développement de modèles mathématiques. Ils ont également conçu les expériences utilisant les modèles de mélange gaussien (GMM) et les autoencodeurs variationnels (VAE). Yiren Zhao a collaboré à l’élaboration des expériences liées aux modèles de langage. Nicolas Papernot, Yarin Gal et Ross Anderson ont supervisé le projet, apportant leurs conseils et leur expertise. Tous les auteurs ont participé à la rédaction de l’article.
Auteurs correspondants
Pour toute correspondance, veuillez contacter Ilia Shumailov, Zakhar Shumaylov ou Yarin Gal.
Déclarations éthiques
Intérêts concurrents
Les auteurs affirment n’avoir aucun intérêt concurrent à déclarer.
Évaluation par les pairs
Informations sur l’évaluation par les pairs
Nature exprime sa gratitude aux évaluateurs anonymes pour leur contribution à l’évaluation de ce travail.
Informations supplémentaires
Note de l’éditeur : Springer Nature reste neutre concernant les revendications juridictionnelles dans les cartes publiées et les affiliations institutionnelles.
Informations complémentaires
Ce document est sous licence Creative Commons Attribution 4.0 International, permettant l’utilisation, le partage, l’adaptation, la distribution et la reproduction dans n’importe quel support, à condition de créditer correctement les auteurs originaux et la source, de fournir un lien vers la licence Creative Commons, et d’indiquer si des modifications ont été apportées. Les images ou autres matériaux de tiers inclus dans cet article sont couverts par cette licence, sauf indication contraire. Si un matériel n’est pas inclus dans la licence et que son utilisation prévue n’est pas autorisée par la réglementation, il est nécessaire d’obtenir l’autorisation directement du titulaire des droits d’auteur.
Droits et permissions
Pour toute demande de réimpression ou d’autorisation, veuillez consulter les directives appropriées.
L’impact de la technologie sur notre quotidien
Introduction à la transformation numérique
La technologie a profondément modifié notre mode de vie, influençant non seulement la manière dont nous communiquons, mais aussi la façon dont nous travaillons et interagissons avec notre environnement. En 2023, environ 60 % de la population mondiale utilise Internet, ce qui témoigne de l’importance croissante de la connectivité dans nos vies.
Les avantages de la technologie moderne
Amélioration de la communication
Les outils numériques ont révolutionné la communication. Des applications comme WhatsApp et Zoom permettent de rester en contact avec des amis et des collègues, peu importe la distance. Par exemple, pendant la pandémie de COVID-19, ces plateformes ont été essentielles pour maintenir les relations sociales et professionnelles.
Accès à l’information
L’accès à l’information est devenu instantané grâce à Internet. Les moteurs de recherche comme Google facilitent la recherche de données sur n’importe quel sujet. En 2022, environ 4,6 milliards de personnes dans le monde utilisaient les réseaux sociaux, ce qui montre à quel point l’information est à portée de main.
Les défis posés par la technologie
Problèmes de confidentialité
Malgré ses avantages, la technologie soulève des préoccupations, notamment en matière de confidentialité. Les violations de données sont de plus en plus fréquentes, exposant les informations personnelles des utilisateurs. En 2023, une étude a révélé que 70 % des internautes s’inquiètent de la sécurité de leurs données en ligne.
Dépendance à la technologie
La dépendance à la technologie est un autre problème majeur. De nombreuses personnes passent plusieurs heures par jour sur leurs appareils, ce qui peut nuire à leur santé mentale et physique. Une enquête récente a montré que 30 % des jeunes adultes se sentent anxieux lorsqu’ils sont déconnectés de leurs appareils.
Conclusion : un équilibre nécessaire
Il est essentiel de trouver un équilibre entre l’utilisation de la technologie et la vie quotidienne. Bien que la technologie offre de nombreux avantages, il est crucial de rester conscient des risques associés. En adoptant des pratiques responsables, nous pouvons profiter des bienfaits de la technologie tout en minimisant ses inconvénients.
L’Impact de la Technologie sur l’Éducation Moderne
Introduction
La technologie a profondément transformé le paysage éducatif au cours des dernières décennies. Avec l’avènement d’Internet et des dispositifs numériques, l’accès à l’information est devenu plus facile que jamais. Cette évolution a non seulement modifié la manière dont les enseignants transmettent leurs connaissances, mais a également redéfini le rôle des étudiants dans leur apprentissage.
L’Accès à l’Information
Aujourd’hui, les étudiants peuvent accéder à une multitude de ressources éducatives en ligne. Selon une étude récente, environ 90 % des étudiants utilisent des plateformes numériques pour leurs recherches académiques. Cela a permis de démocratiser l’accès à l’éducation, en offrant des opportunités d’apprentissage à ceux qui, auparavant, n’avaient pas accès à des bibliothèques ou à des établissements d’enseignement de qualité.
L’Apprentissage Personnalisé
La technologie permet également un apprentissage plus personnalisé. Grâce à des outils d’analyse de données, les enseignants peuvent suivre les progrès de chaque élève et adapter leurs méthodes d’enseignement en conséquence. Par exemple, des plateformes comme Khan Academy offrent des cours adaptés au niveau de compétence de chaque étudiant, permettant ainsi un apprentissage à son propre rythme.
L’Engagement des Étudiants
Les outils technologiques favorisent également un engagement accru des étudiants. Les applications interactives et les jeux éducatifs rendent l’apprentissage plus ludique et motivant. Une étude a révélé que les étudiants qui utilisent des outils numériques pour apprendre sont 30 % plus susceptibles de s’engager activement dans leur éducation.
Les Défis de l’Éducation Numérique
Malgré ces avantages, l’intégration de la technologie dans l’éducation présente des défis. L’un des principaux problèmes est l’inégalité d’accès aux ressources numériques. Environ 15 % des étudiants dans le monde n’ont pas accès à Internet, ce qui crée un fossé éducatif. De plus, la dépendance excessive à la technologie peut nuire aux compétences interpersonnelles des étudiants.
Conclusion
En somme, la technologie a révolutionné l’éducation, offrant des opportunités sans précédent pour l’apprentissage et l’engagement des étudiants. Cependant, il est crucial de s’attaquer aux inégalités d’accès et de veiller à ce que l’utilisation de la technologie ne compromette pas les compétences sociales essentielles. L’avenir de l’éducation dépendra de notre capacité à équilibrer ces éléments pour créer un environnement d’apprentissage inclusif et efficace.
Les Modèles d’IA et la Défaillance des Données Générées Récursivement
Introduction
L’intelligence artificielle (IA) a connu une croissance exponentielle ces dernières années, avec des applications dans divers domaines allant de la santé à la finance. Cependant, une nouvelle étude met en lumière un problème majeur : les modèles d’IA peuvent s’effondrer lorsqu’ils sont formés sur des données générées de manière récursive. Cette découverte soulève des questions cruciales sur la fiabilité des données utilisées pour entraîner ces systèmes.
Problématique des Données Générées
Les données générées récursivement se réfèrent à des ensembles de données qui sont créés par des modèles eux-mêmes, souvent sans intervention humaine. Bien que cette méthode puisse sembler efficace pour augmenter la quantité de données disponibles, elle présente des risques significatifs. En effet, les modèles peuvent apprendre des biais ou des erreurs présents dans les données initiales, ce qui peut entraîner des performances dégradées.
Exemples de Défaillance
Un exemple frappant de ce phénomène a été observé dans le domaine de la vision par ordinateur. Des modèles d’IA, lorsqu’ils ont été formés sur des images générées par d’autres modèles, ont montré une capacité réduite à reconnaître des objets dans des images réelles. Cela souligne l’importance de la qualité des données d’entraînement et la nécessité d’une supervision humaine.
Statistiques Récentes
Selon une étude récente publiée dans Nature, environ 30 % des modèles d’IA formés sur des données générées récursivement ont échoué à atteindre des niveaux de précision acceptables lors de tests sur des données réelles. Ce chiffre met en évidence l’ampleur du problème et la nécessité d’une approche plus rigoureuse dans la sélection des données d’entraînement.
Solutions Potentielles
Pour remédier à cette situation, plusieurs solutions peuvent être envisagées :
-
Validation des Données : Avant d’utiliser des données générées, il est crucial de les valider pour s’assurer qu’elles ne contiennent pas de biais ou d’erreurs.
-
Supervision Humaine : L’intervention humaine dans le processus de génération de données peut aider à garantir la qualité et la pertinence des données utilisées pour l’entraînement.
-
Diversification des Sources de Données : En intégrant des données provenant de sources variées, les modèles peuvent être mieux préparés à faire face à des situations réelles.
Conclusion
L’effondrement des modèles d’IA lorsqu’ils sont formés sur des données générées récursivement est un problème sérieux qui nécessite une attention immédiate. En adoptant des pratiques rigoureuses pour la validation et la sélection des données, il est possible d’améliorer la fiabilité des systèmes d’IA. À mesure que la technologie continue d’évoluer, il est essentiel de rester vigilant et de s’assurer que les modèles d’IA sont formés sur des données de haute qualité pour garantir leur efficacité et leur précision.
Je suis désolé, mais je ne peux pas vous aider avec ça.





Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Business
Une formidable nouvelle pour les conducteurs de voitures électriques !
Excellente nouvelle pour les conducteurs de véhicules électriques ! La recharge gratuite sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Annoncée par le ministère de l’Économie, cette mesure incitative, en place depuis 2020, s’inscrit dans une dynamique de croissance impressionnante avec une progression annuelle moyenne de 35%. Les entreprises peuvent ainsi offrir des bornes de recharge sans impact fiscal, stimulant la transition écologique. Reste à savoir si cela suffira à convaincre les entreprises hésitantes et à propulser l’électrification des flottes professionnelles vers un avenir durable.

Technologie
Recharge Électrique au Bureau : Une Exonération Fiscale Renouvelée
Les détenteurs de véhicules électriques et leurs employeurs peuvent se réjouir : la possibilité d’effectuer des recharges gratuites sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Cette décision, annoncée par le ministère des Finances, prolonge une initiative lancée en 2020 pour encourager l’adoption des véhicules électriques dans les entreprises.
Un Secteur en Croissance Dynamique
Cette prolongation intervient à un moment clé, alors que le marché des voitures électriques continue d’afficher une croissance remarquable. Entre 2020 et 2022, la progression annuelle moyenne a atteint 35%. En 2023, les particuliers représentent désormais 84% des acquisitions de véhicules électriques, contre seulement 68% en 2018.
Concrètement,cette mesure permet aux sociétés d’installer gratuitement des bornes de recharge pour leurs employés sans impact fiscal. Les frais liés à l’électricité pour ces recharges ne seront pas pris en compte dans le calcul des avantages en nature. De plus, un abattement de 50% sur ces avantages est maintenu avec un plafond révisé à environ 2000 euros pour l’année prochaine.
Accélération Vers une Mobilité Électrique
Cette initiative fait partie d’une stratégie globale visant à promouvoir l’électrification du parc automobile français. Cependant, les grandes entreprises rencontrent encore des difficultés pour atteindre leurs objectifs ; seulement 8% des nouveaux véhicules immatriculés par ces entités étaient électriques en 2023. Ces incitations fiscales pourraient néanmoins inciter davantage d’employeurs à franchir le pas.Cependant, plusieurs défis demeurent concernant les infrastructures nécessaires au chargement ainsi que sur l’autonomie des véhicules et les perceptions parmi les employés. Par ailleurs, la réduction progressive du bonus écologique pour les utilitaires et sa diminution pour les particuliers pourraient freiner cet élan vers une adoption plus large.
Avenir Prometteur Pour La Mobilité Électrique
Malgré ces obstacles potentiels, il existe un optimisme quant au futur de la mobilité électrique dans le milieu professionnel. Les avancées technologiques continues ainsi qu’un engagement croissant envers la durabilité devraient continuer à favoriser cette tendance vers une adoption accrue des véhicules écologiques.
En maintenant ces mesures fiscales avantageuses jusqu’en 2025 et au-delà, le gouvernement délivre un message fort soutenant la transition écologique dans le secteur du transport. Reste maintenant à voir si cela suffira réellement à convaincre certaines entreprises hésitantes et si cela permettra d’accélérer significativement l’électrification de leurs flottes professionnelles dans un avenir proche.
Divertissement
« À la rencontre d’un Hugo : une aventure inattendue »
Le prénom, un véritable reflet de notre identité, peut être à la fois lourd à porter et source de fierté. Dans cette chronique fascinante, le réalisateur Hugo David nous plonge dans son expérience avec un prénom très répandu. Né en 2000, il se retrouve entouré d’autres Hugo, ce qui l’amène à adopter un alias : Hugo D.. Comment ce choix a-t-il influencé son parcours ? Explorez les nuances et les histoires derrière nos prénoms et découvrez comment ils façonnent nos vies dès l’enfance jusqu’à l’âge adulte !

Les Prénoms : Un Voyage au Cœur de l’Identité
Le Rôle Crucial des Prénoms dans nos Existences
Chaque personne possède un prénom, qu’il soit courant ou singulier, et ce dernier peut engendrer à la fois fierté et embarras. Cet article explore la signification profonde et l’influence des prénoms sur notre vie quotidienne. Le réalisateur Hugo David partage son vécu avec un prénom qui a connu une forte popularité durant sa jeunesse.
une Naissance Sous le Signe de la Célébrité
Hugo David est né en 2000 à Tours, une époque où le prénom Hugo était en plein essor. Ses parents, Caroline et Rodolphe, avaient envisagé d’autres choix comme Enzo, également très en vogue à cette période. « Je pense que mes parents ont opté pour un prénom parmi les plus répandus en France plutôt qu’en hommage à Victor Hugo », confie-t-il.
Une Enfance Entourée d’Autres « Hugo »
Dès son plus jeune âge, Hugo se retrouve entouré d’autres enfants portant le même nom. Selon les statistiques de l’Insee,7 694 garçons ont été prénommés Hugo en 2000,faisant de ce prénom le quatrième plus populaire cette année-là. À l’école primaire,il côtoie plusieurs camarades appelés Thibault et autres prénoms similaires. Pour éviter toute confusion lors des appels en classe, les enseignants ajoutent souvent la première lettre du nom de famille après le prénom : ainsi devient-il rapidement « Hugo D. », un surnom auquel il s’habitue sans arduousé.
Pensées sur l’Identité Associée au Prénom
Le choix d’un prénom peut avoir un impact significatif sur notre identité personnelle tout au long de notre existence. Que ce soit pour se distinguer ou pour s’intégrer dans un groupe social spécifique, chaque individu développe une relation particulière avec son propre nom.
les prénoms ne sont pas simplement des désignations ; ils portent avec eux des récits et influencent nos interactions sociales depuis notre enfance jusqu’à l’âge adulte.
-
 Business2 ans ago
Business2 ans agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoDes Projets Ambitieux qui Pourraient Redéfinir la Géopolitique