Général
Pourquoi se contenter de GitHub Copilot quand on peut créer son propre assistant de code IA à la maison ?
Les assistants de code alimentés par l’IA suscitent un intérêt croissant, notamment avec le lancement de GitHub Copilot de Microsoft. Si vous n’êtes pas fan de l’idée de confier votre code à Microsoft ou de payer un abonnement, pourquoi ne pas créer votre propre assistant ? Continue, un assistant de code open source, s’intègre facilement dans des IDE populaires comme JetBrains ou Visual Studio Code. Avec des fonctionnalités telles que la génération de code, l’optimisation et même un chatbot intégré, Continue transforme votre manière de coder. Prêt à explorer ?
Prise en main Les assistants de code ont suscité un intérêt considérable en tant qu’application précoce de l’IA générative, surtout après le lancement de GitHub Copilot par Microsoft. Cependant, si l’idée de confier votre code à Microsoft ne vous enchante pas ou si vous préférez éviter de payer 10 $ par mois, vous avez toujours la possibilité de créer votre propre assistant.
Bien que Microsoft ait été l’un des premiers à commercialiser un assistant de code basé sur l’IA et à l’intégrer dans un environnement de développement intégré (IDE), ce n’est pas la seule option disponible. En réalité, il existe de nombreux modèles de langage de grande taille (LLMs) spécifiquement entraînés pour la génération de code.
De plus, il est fort probable que l’ordinateur sur lequel vous travaillez actuellement soit capable d’exécuter ces modèles. L’enjeu réside dans leur intégration dans un IDE de manière réellement utile.
C’est ici qu’interviennent des applications comme Continue. Cet assistant de code open source est conçu pour s’intégrer dans des IDE populaires tels que JetBrains ou Visual Studio Code et se connecter à des exécuteurs de LLM que vous connaissez peut-être déjà, comme Ollama, Llama.cpp et LM Studio.
À l’instar d’autres assistants de code populaires, Continue prend en charge la complétion et la génération de code, ainsi que l’optimisation, les commentaires ou le refactoring de votre code pour différents cas d’utilisation. De plus, Continue dispose d’un chatbot intégré avec des fonctionnalités de RAG, ce qui vous permet d’interagir avec votre base de code.
Préparatifs nécessaires
- Un ordinateur capable d’exécuter des LLM modestes. Un système avec un processeur relativement récent fonctionnera, mais pour des performances optimales, nous recommandons un GPU Nvidia, AMD ou Intel avec au moins 6 Go de vRAM. Si vous êtes plutôt utilisateur de Mac, tout système Apple Silicon, y compris le M1 d’origine, devrait faire l’affaire, bien que nous recommandions au moins 16 Go de mémoire pour de meilleurs résultats.
- Ce guide suppose également que vous avez configuré et exécuté le modèle Ollama sur votre machine. Si ce n’est pas le cas, vous pouvez consulter notre guide ici, qui vous permettra de vous mettre en route en moins de dix minutes. Pour ceux utilisant des graphiques Intel intégrés ou Arc, un guide pour déployer Ollama avec IPEX-LLM est disponible ici.
- Un IDE compatible. Au moment de la rédaction, Continue prend en charge à la fois JetBrains et Visual Studio Code. Si vous souhaitez éviter complètement la télémétrie de Microsoft, comme nous le faisons, la version open source – VSCodium – fonctionne également très bien.
Installation de Continue
Pour ce guide, nous allons déployer Continue dans VSCodium. Pour commencer, lancez l’IDE et ouvrez le panneau des extensions. À partir de là, recherchez et installez « Continue. »
Après quelques secondes, l’assistant de configuration initiale de Continue devrait se lancer, vous demandant de choisir si vous souhaitez héberger vos modèles localement ou utiliser l’API d’un autre fournisseur.
Dans ce cas, nous allons héberger nos modèles localement via Ollama, donc nous sélectionnerons « Modèles locaux. » Cela configurera Continue pour utiliser les modèles suivants par défaut. Nous discuterons de la manière de les remplacer par d’autres modèles un peu plus tard, mais pour l’instant, ceux-ci constituent un bon point de départ :
- Llama 3 8B : Un LLM polyvalent de Meta, utilisé pour commenter, optimiser et/ou refactoriser du code. Vous pouvez en apprendre davantage sur Llama 3 dans notre couverture du jour de son lancement ici.
- Nomic-embed-text : Un modèle d’embedding utilisé pour indexer votre base de code localement, vous permettant de référencer votre code lors de l’interaction avec le chatbot intégré.
- Starcoder2:3B : Il s’agit d’un modèle de génération de code développé par BigCode qui alimente la fonctionnalité d’auto-complétion de Continue.
Si, pour une raison quelconque, Continue passe l’assistant de lancement, ne vous inquiétez pas, vous pouvez récupérer ces modèles manuellement en utilisant Ollama en exécutant les commandes suivantes dans votre terminal :
ollama pull llama3 ollama pull nomic-embed-text ollama pull starcoder2:3b
Pour plus d’informations sur la configuration et le déploiement de modèles avec Ollama, consultez notre guide de démarrage rapide ici.
Avis sur la télémétrie :
Avant de continuer, il est important de noter qu’en mode par défaut, Continue collecte des données de télémétrie anonymisées, y compris :
- Si vous acceptez ou rejetez des suggestions (sans inclure de code ou de prompt) ;
- Le nom du modèle et de la commande utilisés ;
- Le nombre de tokens générés ;
- Le nom de votre système d’exploitation et de votre IDE ;
- Les pages vues.
Vous pouvez vous désinscrire de cette collecte en modifiant le fichier .continue situé dans votre répertoire personnel ou en décochant la case « Continue : Télémétrie activée » dans les paramètres de VSCodium.
Demandez et vous recevrez. Cela fonctionnera-t-il ? C’est une autre question
Une fois l’installation terminée, nous pouvons explorer les différentes manières d’intégrer Continue dans votre flux de travail. La première méthode est sans doute la plus évidente : générer des extraits de code à partir de zéro.
Par exemple, si vous souhaitez créer une page web basique pour un projet, vous appuyez sur Ctrl-I ou Command-I sur votre clavier et entrez votre prompt dans la barre d’action.
Dans ce cas, notre prompt était « Générer une simple page d’accueil en HTML avec CSS en ligne. » Après avoir soumis notre prompt, Continue charge le modèle pertinent – cela peut prendre quelques secondes selon votre matériel – et vous présente un extrait de code à accepter ou à rejeter.
Le code généré dans Continue apparaîtra dans VSCodium sous forme de blocs verts que vous pourrez approuver ou rejeter.
Optimisation de votre code
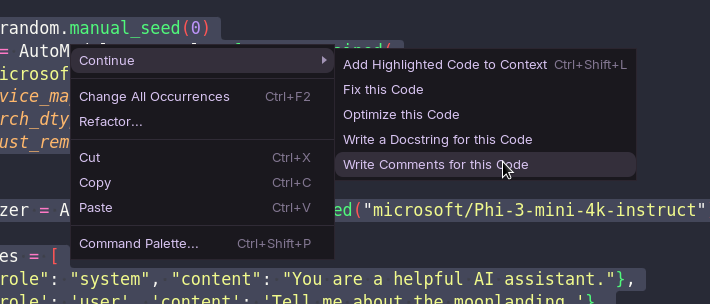
La fonctionnalité Continue peut également être utilisée pour refactoriser, commenter, optimiser ou modifier votre code existant.
Imaginons que vous ayez un script Python destiné à exécuter un modèle de langage dans PyTorch, et que vous souhaitiez le modifier pour qu’il fonctionne sur un Mac avec processeur Apple Silicon. Pour ce faire, vous commenceriez par sélectionner votre document, puis appuyer sur Ctrl-I sur votre clavier pour demander à l’assistant d’effectuer cette tâche.

Après quelques instants, Continue vous transmet les recommandations du modèle concernant les modifications à apporter, avec le nouveau code mis en évidence en vert et le code à supprimer marqué en rouge.

En plus de refactoriser le code existant, cette fonctionnalité peut également être utile pour générer des commentaires ou des docstrings après coup. Ces fonctions sont accessibles sous »Continue » dans le menu contextuel du clic droit.
Complétion automatique des onglets
Bien que la génération de code puisse être utile pour créer rapidement des prototypes ou refactoriser du code existant, elle peut parfois être imprécise selon le modèle utilisé.
Quiconque a déjà demandé à ChatGPT de générer un bloc de code sait que parfois, il commence à halluciner des paquets ou des fonctions. Ces hallucinations deviennent rapidement évidentes, car un code défectueux échoue souvent de manière spectaculaire. Comme nous l’avons déjà mentionné, ces paquets imaginaires peuvent représenter une menace pour la sécurité s’ils sont suggérés trop souvent.
Si confier l’écriture de votre code à un modèle d’IA vous semble trop risqué, Continue propose également une fonctionnalité de complétion de code. Cela vous permet de garder un meilleur contrôle sur les modifications apportées par le modèle.

Cette fonctionnalité fonctionne un peu comme la complétion par onglet dans le terminal. En tapant, Continue envoie automatiquement votre code à un modèle – tel que Starcoder2 ou Codestral – et propose des suggestions pour compléter une chaîne ou une fonction.
Les suggestions apparaissent en gris et sont mises à jour à chaque frappe. Si Continue devine correctement, vous pouvez accepter la suggestion en appuyant sur la touche Tab de votre clavier.
Interagir avec votre code
En plus de la génération et de la prédiction de code, Continue intègre un chatbot avec des fonctionnalités de type RAG. Pour en savoir plus sur RAG, vous pouvez consulter notre guide pratique, mais dans le cas de Continue, il utilise une combinaison de Llama 3 8B et du modèle d’embedding nomic-embed-text pour rendre votre code facilement consultable.

Continue dispose d’un chatbot intégré qui se connecte à votre LLM de choix.
Cette fonctionnalité peut sembler complexe, mais voici quelques exemples de son utilisation pour accélérer votre flux de travail :
- Tapez
@docssuivi du nom de votre application ou service – par exempleDocker– et ajoutez votre question à la fin. - Pour interroger votre répertoire de travail, tapez
@codebase suivi de votre question. - Des fichiers ou documents peuvent être ajoutés au contexte du modèle en tapant
@fileset en sélectionnant le fichier souhaité dans le menu déroulant. - Le code sélectionné dans l’éditeur peut être ajouté au chatbot en appuyant sur
Ctrl-L. - Appuyez sur
Ctrl-Shift-Rpour envoyer des erreurs du terminal de VS Code directement au chatbot pour diagnostic.
Changement de modèles
La fiabilité de Continue dépend réellement des modèles que vous utilisez, car le plug-in lui-même est davantage un cadre pour intégrer des LLM et des modèles de code dans votre IDE. Bien qu’il détermine comment vous interagissez avec ces modèles, il n’a pas de contrôle sur la qualité du code généré.
La bonne nouvelle est que Continue n’est pas lié à un modèle ou une technologie spécifique. Comme mentionné précédemment, il se connecte à divers exécuteurs de LLM et API. Si un nouveau modèle est publié et optimisé pour votre langage de programmation préféré, rien ne vous empêche – à part votre matériel, bien sûr – d’en profiter.
Étant donné que nous utilisons Ollama comme serveur de modèles, changer de modèle est généralement une tâche relativement simple. Par exemple, si vous souhaitez remplacer Llama 3 par Gemma 2 9B de Google et Starcoder2 par Codestral, vous pouvez exécuter les commandes suivantes :
ollama pull gemma2 ollama pull codestral
Remarque : Avec 22 milliards de paramètres et une fenêtre de contexte de 32 000 tokens, Codestral est un modèle assez lourd à exécuter chez soi, même lorsqu’il est quantifié à une précision de 4 bits. Si vous rencontrez des problèmes de plantage, envisagez d’utiliser quelque chose de plus léger, comme les variantes 1B ou 7B de DeepSeek Coder.
Pour changer le modèle utilisé par le chatbot et le générateur de code, vous pouvez le sélectionner dans le menu de sélection de Continue. Alternativement, vous pouvez faire défiler les modèles téléchargés en utilisant Ctrl-'.

Changer le modèle utilisé pour la fonctionnalité de complétion automatique des onglets est un peu plus complexe et nécessite des ajustements dans le fichier de configuration du plug-in.
Pour commencer, il est nécessaire d’apporter quelques modifications au fichier de configuration de Continue.
Après avoir téléchargé le modèle de votre choix, cliquez sur l’icône d’engrenage située dans le coin inférieur droit de la barre latérale de Continue et ajustez les entrées « title » et « model » dans la section « tabAutocompleteModel ». Si vous utilisez Codestral, cette section devrait ressembler à ceci :
"tabAutocompleteModel": {
"title": "codestral",
"provider": "ollama",
"model": "codestral"
},
Ajustement d’un modèle de code personnalisé
Par défaut, Continue recueille automatiquement des données sur la manière dont vous développez votre logiciel. Ces données peuvent être utilisées pour affiner des modèles personnalisés en fonction de votre style et de vos flux de travail spécifiques.
Pour être clair, ces données sont stockées localement dans le répertoire .continue/dev_data de votre dossier personnel et, d’après nos informations, ne sont pas incluses dans les données de télémétrie que Continue collecte par défaut. Cependant, si cela vous préoccupe, nous vous conseillons de désactiver cette option.
Les détails concernant l’ajustement des grands modèles de langage dépassent le cadre de cet article, mais vous pouvez en apprendre davantage sur le type de données collectées par l’application et leur utilisation dans cet article de blog.
Nous espérons explorer l’ajustement plus en profondeur dans un futur article pratique, alors n’hésitez pas à partager vos réflexions sur les outils d’IA locaux comme Continue, ainsi que vos suggestions sur ce que vous aimeriez que nous essayions ensuite dans la section des commentaires.






Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Business
Une formidable nouvelle pour les conducteurs de voitures électriques !
Excellente nouvelle pour les conducteurs de véhicules électriques ! La recharge gratuite sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Annoncée par le ministère de l’Économie, cette mesure incitative, en place depuis 2020, s’inscrit dans une dynamique de croissance impressionnante avec une progression annuelle moyenne de 35%. Les entreprises peuvent ainsi offrir des bornes de recharge sans impact fiscal, stimulant la transition écologique. Reste à savoir si cela suffira à convaincre les entreprises hésitantes et à propulser l’électrification des flottes professionnelles vers un avenir durable.

Technologie
Recharge Électrique au Bureau : Une Exonération Fiscale Renouvelée
Les détenteurs de véhicules électriques et leurs employeurs peuvent se réjouir : la possibilité d’effectuer des recharges gratuites sur le lieu de travail sera exonérée d’impôts jusqu’en 2025. Cette décision, annoncée par le ministère des Finances, prolonge une initiative lancée en 2020 pour encourager l’adoption des véhicules électriques dans les entreprises.
Un Secteur en Croissance Dynamique
Cette prolongation intervient à un moment clé, alors que le marché des voitures électriques continue d’afficher une croissance remarquable. Entre 2020 et 2022, la progression annuelle moyenne a atteint 35%. En 2023, les particuliers représentent désormais 84% des acquisitions de véhicules électriques, contre seulement 68% en 2018.
Concrètement,cette mesure permet aux sociétés d’installer gratuitement des bornes de recharge pour leurs employés sans impact fiscal. Les frais liés à l’électricité pour ces recharges ne seront pas pris en compte dans le calcul des avantages en nature. De plus, un abattement de 50% sur ces avantages est maintenu avec un plafond révisé à environ 2000 euros pour l’année prochaine.
Accélération Vers une Mobilité Électrique
Cette initiative fait partie d’une stratégie globale visant à promouvoir l’électrification du parc automobile français. Cependant, les grandes entreprises rencontrent encore des difficultés pour atteindre leurs objectifs ; seulement 8% des nouveaux véhicules immatriculés par ces entités étaient électriques en 2023. Ces incitations fiscales pourraient néanmoins inciter davantage d’employeurs à franchir le pas.Cependant, plusieurs défis demeurent concernant les infrastructures nécessaires au chargement ainsi que sur l’autonomie des véhicules et les perceptions parmi les employés. Par ailleurs, la réduction progressive du bonus écologique pour les utilitaires et sa diminution pour les particuliers pourraient freiner cet élan vers une adoption plus large.
Avenir Prometteur Pour La Mobilité Électrique
Malgré ces obstacles potentiels, il existe un optimisme quant au futur de la mobilité électrique dans le milieu professionnel. Les avancées technologiques continues ainsi qu’un engagement croissant envers la durabilité devraient continuer à favoriser cette tendance vers une adoption accrue des véhicules écologiques.
En maintenant ces mesures fiscales avantageuses jusqu’en 2025 et au-delà, le gouvernement délivre un message fort soutenant la transition écologique dans le secteur du transport. Reste maintenant à voir si cela suffira réellement à convaincre certaines entreprises hésitantes et si cela permettra d’accélérer significativement l’électrification de leurs flottes professionnelles dans un avenir proche.
Divertissement
« À la rencontre d’un Hugo : une aventure inattendue »
Le prénom, un véritable reflet de notre identité, peut être à la fois lourd à porter et source de fierté. Dans cette chronique fascinante, le réalisateur Hugo David nous plonge dans son expérience avec un prénom très répandu. Né en 2000, il se retrouve entouré d’autres Hugo, ce qui l’amène à adopter un alias : Hugo D.. Comment ce choix a-t-il influencé son parcours ? Explorez les nuances et les histoires derrière nos prénoms et découvrez comment ils façonnent nos vies dès l’enfance jusqu’à l’âge adulte !

Les Prénoms : Un Voyage au Cœur de l’Identité
Le Rôle Crucial des Prénoms dans nos Existences
Chaque personne possède un prénom, qu’il soit courant ou singulier, et ce dernier peut engendrer à la fois fierté et embarras. Cet article explore la signification profonde et l’influence des prénoms sur notre vie quotidienne. Le réalisateur Hugo David partage son vécu avec un prénom qui a connu une forte popularité durant sa jeunesse.
une Naissance Sous le Signe de la Célébrité
Hugo David est né en 2000 à Tours, une époque où le prénom Hugo était en plein essor. Ses parents, Caroline et Rodolphe, avaient envisagé d’autres choix comme Enzo, également très en vogue à cette période. « Je pense que mes parents ont opté pour un prénom parmi les plus répandus en France plutôt qu’en hommage à Victor Hugo », confie-t-il.
Une Enfance Entourée d’Autres « Hugo »
Dès son plus jeune âge, Hugo se retrouve entouré d’autres enfants portant le même nom. Selon les statistiques de l’Insee,7 694 garçons ont été prénommés Hugo en 2000,faisant de ce prénom le quatrième plus populaire cette année-là. À l’école primaire,il côtoie plusieurs camarades appelés Thibault et autres prénoms similaires. Pour éviter toute confusion lors des appels en classe, les enseignants ajoutent souvent la première lettre du nom de famille après le prénom : ainsi devient-il rapidement « Hugo D. », un surnom auquel il s’habitue sans arduousé.
Pensées sur l’Identité Associée au Prénom
Le choix d’un prénom peut avoir un impact significatif sur notre identité personnelle tout au long de notre existence. Que ce soit pour se distinguer ou pour s’intégrer dans un groupe social spécifique, chaque individu développe une relation particulière avec son propre nom.
les prénoms ne sont pas simplement des désignations ; ils portent avec eux des récits et influencent nos interactions sociales depuis notre enfance jusqu’à l’âge adulte.
-
 Business1 an ago
Business1 an agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoLes meilleures offres du MacBook Pro ce mois-ci !