Technologie
Plongée dans l’Extension FTS5 de SQLite : Optimisez vos Recherches !
1. Overview of FTS5 FTS5 is an SQLite virtual table module that provides full-text search functionality to database applications. In their most elementary form, full-text search engines allow the user to efficiently search a large collection of documents for the subset that contain one or more instances of a search term. The search functionality provided
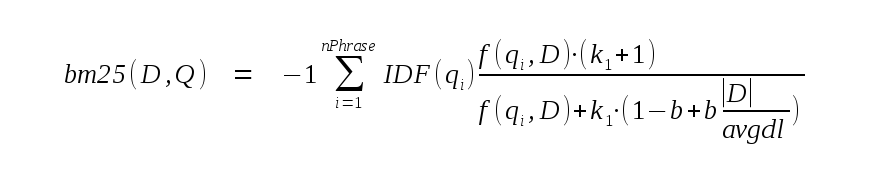
1. Introduction à FTS5
FTS5 est un module de table virtuelle d’SQLite qui offre des fonctionnalités de recherche en texte intégral pour les applications de base de données. À un niveau fondamental, les moteurs de recherche en texte intégral permettent aux utilisateurs de rechercher efficacement dans un vaste ensemble de documents pour identifier ceux qui contiennent un ou plusieurs termes de recherche. Par exemple, le moteur de recherche de Google, qui permet aux utilisateurs de trouver tous les documents sur le web contenant le terme « fts5 », illustre bien cette fonctionnalité.
Pour tirer parti de FTS5, l’utilisateur doit créer une table virtuelle FTS5 avec une ou plusieurs colonnes. Voici un exemple :
CREATE VIRTUAL TABLE email USING fts5(expéditeur, titre, corps);
Il est important de noter qu’il est incorrect d’ajouter des types, des contraintes ou des déclarations de clé primaire lors de la création d’une table FTS5. Une fois la table créée, elle peut être remplie à l’aide des instructions INSERT, UPDATE ou DELETE, tout comme n’importe quelle autre table. De plus, une table FTS5 sans déclaration de clé primaire possède un champ implicite INTEGER PRIMARY KEY nommé rowid.
En plus de la structure de base, il existe diverses options qui peuvent être spécifiées dans l’instruction CREATE VIRTUAL TABLE pour configurer différents aspects de la nouvelle table. Ces options peuvent modifier la manière dont la table FTS5 extrait les termes des documents et des requêtes, créer des index supplémentaires sur disque pour accélérer les requêtes par préfixe, ou établir une table FTS5 qui sert d’index pour un contenu stocké ailleurs.
Une fois la table peuplée, il existe trois méthodes pour exécuter une requête en texte intégral sur le contenu d’une table FTS5 :
- En utilisant un opérateur MATCH dans la clause WHERE d’une instruction SELECT, ou
- En utilisant un opérateur égal (« = ») dans la clause WHERE d’une instruction SELECT, ou
- En utilisant la syntaxe de fonction de table.
Lorsque l’on utilise les opérateurs MATCH ou « = », l’expression à gauche de l’opérateur MATCH est généralement le nom de la table FTS5 (sauf lorsqu’un filtre de colonne est spécifié). L’expression à droite doit être une valeur textuelle indiquant le terme à rechercher. Pour la syntaxe de fonction de table, le terme à rechercher est spécifié comme le premier argument de la table. Par exemple :
-- Requête pour toutes les lignes contenant au moins une instance du terme
-- "fts5" (dans n'importe quelle colonne). Les trois requêtes suivantes sont équivalentes.
SELECT * FROM email WHERE email MATCH 'fts5';
SELECT * FROM email WHERE email='fts5';
SELECT * FROM email('fts5');
Par défaut, les recherches en texte intégral FTS5 ne tiennent pas compte de la casse. Comme pour toute autre requête SQL sans clause ORDER BY, l’exemple ci-dessus renvoie des résultats dans un ordre arbitraire. Pour trier les résultats par pertinence (du plus pertinent au moins pertinent), une clause ORDER BY peut être ajoutée à une requête en texte intégral comme suit :
-- Requête pour toutes les lignes contenant au moins une instance du terme -- "fts5" (dans n'importe quelle colonne). Retourner les résultats par ordre de pertinence. SELECT * FROM email WHERE email MATCH 'fts5' ORDER BY rank;
En plus des valeurs de colonne et du rowid d’une ligne correspondante, une application peut utiliser des fonctions auxiliaires FTS5 pour récupérer des informations supplémentaires concernant la ligne correspondante. Par exemple, une fonction auxiliaire peut être utilisée pour obtenir une copie d’une valeur de colonne pour une ligne correspondante, avec toutes les instances du terme correspondant entourées de balises HTML . Les fonctions auxiliaires sont invoquées de la même manière que les fonctions scalaires SQLite, sauf que le nom de la table FTS5 est spécifié comme premier argument. Par exemple :
-- Requête pour les lignes qui correspondent à "fts5". Retourner une copie de la colonne "corps"
-- de chaque ligne avec les correspondances entourées de balises .
SELECT highlight(email, 2, '', '') FROM email('fts5');
Une description des fonctions auxiliaires disponibles, ainsi que des détails supplémentaires concernant la configuration de la colonne spéciale « rank », sont disponibles ci-dessous. De plus, des fonctions auxiliaires personnalisées peuvent également être mises en œuvre en C et enregistrées avec FTS5, tout comme des fonctions SQL personnalisées peuvent être enregistrées avec le cœur d’SQLite.
FTS5 permet également de rechercher des lignes contenant :
- des termes commençant par un préfixe spécifié,
- des « phrases » – séquences de termes ou de termes préfixes qui doivent apparaître dans un document pour qu’il corresponde à la requête,
- des ensembles de termes, de termes préfixes ou de phrases qui apparaissent à proximité les uns des autres (appelées « requêtes NEAR »), ou
- des combinaisons booléennes de tout ce qui précède.
Ces recherches avancées sont demandées en fournissant une chaîne de requête FTS5 plus complexe comme texte à droite de l’opérateur MATCH (ou de l’opérateur « = » ou comme premier argument de la syntaxe de fonction de table). La syntaxe complète de la requête est décrite ici.
2. Compilation et Utilisation de FTS5
2.1. Introduction de FTS5 dans SQLite
Depuis la version 3.9.0 (14 octobre 2015), FTS5 est inclus dans l’amalgamation d’SQLite. Si vous utilisez l’un des deux systèmes de construction autoconf, FTS5 est activé en spécifiant l’option « –enable-fts5 » lors de l’exécution du script de configuration. (FTS5 est actuellement désactivé par défaut pour le script de configuration de l’arbre source et activé par défaut pour le script de configuration de l’amalgamation, mais ces paramètres par défaut pourraient changer à l’avenir.)
Alternativement, si sqlite3.c est compilé en utilisant un autre système de construction, il faut s’assurer que le symbole préprocesseur SQLITE_ENABLE_FTS5 soit défini.
2.2. Création d’une Extension Chargeable
FTS5 peut également être construit en tant qu’extension chargeable.
Le code source canonique de FTS5 se compose d’une série de fichiers *.c et d’autres fichiers dans le répertoire « ext/fts5 » de l’arbre source d’SQLite. Un processus de construction réduit cela à seulement deux fichiers - « fts5.c » et « fts5.h » - qui peuvent être utilisés pour créer une extension chargeable SQLite.
- Obtenez le dernier code SQLite depuis fossil.
- Créez un Makefile comme décrit dans Comment Compiler SQLite.
- Construisez la cible « fts5.c », ce qui crée également fts5.h.
$ wget -c https://www.sqlite.org/src/tarball/SQLite-trunk.tgz?uuid=trunk -O SQLite-trunk.tgz .... sortie ... $ tar -xzf SQLite-trunk.tgz $ cd SQLite-trunk $ ./configure && make fts5.c ... beaucoup de sorties ... $ ls fts5.[ch] fts5.c fts5.h
Le code dans »fts5.c » peut ensuite être compilé en une extension chargeable ou lié statiquement dans une application comme décrit ci-dessus.
Compilation des Extensions Chargeables
Deux points d’entrée sont définis, et ils accomplissent la même tâche :
sqlite3_fts_initsqlite3_fts5_init
Le fichier « fts5.h » n’est pas nécessaire pour compiler l’extension FTS5. Il est utilisé par les applications qui mettent en œuvre des tokenizers ou des fonctions auxiliaires personnalisées pour FTS5.
Syntaxe des Requêtes en Texte Intégral
Le bloc suivant résume la syntaxe des requêtes FTS sous forme BNF. Une explication détaillée suit.
phrase := string [*]
phrase := phrase + phrase
neargroup := NEAR ( phrase phrase ... [, N] )
query := [ [-] colspec :] [^] phrase
query := [ [-] colspec :] neargroup
query := [ [-] colspec :] ( query )
query := query AND query
query := query OR query
query := query NOT query
colspec := colname
colspec := { colname1 colname2 ... }Chaînes FTS5
Dans une expression FTS, une chaîne peut être spécifiée de deux manières :
-
En l’encapsulant dans des guillemets doubles (« ). Dans une chaîne, tout caractère de guillemet double intégré peut être échappé de manière SQL en ajoutant un second guillemet double.
-
En tant que mot nu FTS5 qui n’est pas « AND », « OR » ou « NOT » (sensible à la casse). Un mot nu FTS5 est une chaîne composée d’un ou plusieurs caractères consécutifs qui sont tous soit :
- Des caractères non-ASCII (c’est-à-dire des points de code Unicode supérieurs à 127), ou
- L’un des 52 caractères ASCII en majuscules et minuscules, ou
- L’un des 10 chiffres décimaux ASCII, ou
- Le caractère de soulignement (point de code Unicode 96).
- Le caractère de substitution (point de code Unicode 26).
Les chaînes contenant d’autres caractères doivent être citées. Les caractères qui ne sont pas actuellement autorisés dans les mots nus, qui ne sont pas des caractères de citation et qui ne servent pas à des fins spéciales dans les expressions de requête FTS5 pourraient, à l’avenir, être autorisés dans les mots nus ou utilisés pour mettre en œuvre de nouvelles fonctionnalités de requête. Cela signifie que les requêtes qui sont actuellement des erreurs de syntaxe en raison de l’inclusion d’un tel caractère en dehors d’une chaîne citée pourraient être interprétées différemment par une version future de FTS5.
Phrases FTS5
Chaque chaîne dans une requête FTS5 est analysée (« tokenisée ») par le tokenizer, et une liste de zéro ou plusieurs tokens, ou termes, est extraite. Par exemple, le tokenizer par défaut tokenise la chaîne « alpha beta gamma » en trois tokens distincts : »alpha », « beta » et « gamma », dans cet ordre.
Les requêtes FTS sont composées de phrases. Une phrase est une liste ordonnée d’un ou plusieurs tokens. Les tokens de chaque chaîne dans la requête constituent chacun une phrase unique. Deux phrases peuvent être concaténées en une seule grande phrase à l’aide de l’opérateur « + ». Par exemple, en supposant que le module tokenizer utilisé tokenise l’entrée « un.deux.trois » en trois tokens distincts, les quatre requêtes suivantes spécifient toutes la même phrase :
... MATCH '"un deux trois"'
... MATCH 'un + deux + trois'
... MATCH '"un deux" + trois'
... MATCH 'un.deux.trois'Une phrase correspond à un document si le document contient au moins une sous-séquence de tokens qui correspond à la séquence de tokens qui compose la phrase.
Requêtes de Préfixe FTS5
Si un caractère « * » suit une chaîne dans une expression FTS, alors le dernier token extrait de la chaîne est marqué comme un token de préfixe. Comme on peut s’y attendre, un token de préfixe correspond à tout token de document dont il est un préfixe. Par exemple, les deux premières requêtes dans le bloc suivant correspondront à tout document contenant le token « un » immédiatement suivi du token « deux » et ensuite tout token commençant par « trois ».
... MATCH '"un deux tro" * '
... MATCH 'un + deux + tro*'
... MATCH '"un deux tro*"' -- Peut ne pas fonctionner comme prévu !La dernière requête dans le bloc ci-dessus peut ne pas fonctionner comme prévu. Étant donné que le caractère « * » est à l’intérieur des guillemets doubles, il sera transmis au tokenizer, qui risque de l’ignorer (ou peut-être, selon le tokenizer spécifique utilisé, de l’inclure comme partie du token final) au lieu de le reconnaître comme un caractère spécial FTS.
Requêtes de Token Initial FTS5
Si un caractère « ^ » apparaît immédiatement avant une phrase qui ne fait pas partie d’une requête NEAR, alors cette phrase ne correspond à un document que si elle commence au premier token d’une colonne. La syntaxe « ^ » peut être combinée avec un filtre de colonne, mais ne peut pas être insérée au milieu d’une phrase.
... MATCH '^un' -- le premier token de n'importe quelle colonne doit être "un"
... MATCH '^ un + deux' -- la phrase "un deux" doit apparaître au début d'une colonne
... MATCH '^ "un deux"' -- identique à la précédente
... MATCH 'a : ^deux' -- le premier token de la colonne "a" doit être "deux"
... MATCH 'NEAR(^un, deux)' -- erreur de syntaxe !
... MATCH 'un + ^deux' -- erreur de syntaxe !
... MATCH '"^un deux"' -- Peut ne pas fonctionner comme prévu !Requêtes NEAR FTS5
Les requêtes NEAR permettent de spécifier que les tokens doivent apparaître à proximité les uns des autres dans le texte. Cela est particulièrement utile pour les recherches où l’ordre et la proximité des mots sont cruciaux pour le sens de la phrase.
Groupes NEAR : Comprendre leur Utilisation
Les groupes NEAR permettent de regrouper deux ou plusieurs phrases. Un groupe NEAR est défini par le mot « NEAR » (sensible à la casse), suivi d’une parenthèse ouvrante, de deux phrases séparées par des espaces, et éventuellement d’une virgule suivie d’un paramètre numérique N, avant de fermer la parenthèse. Par exemple :
... MATCH 'NEAR("un deux" "trois quatre", 10)'
... MATCH 'NEAR("un deux" thr* + quatre)'
Si aucun paramètre N n’est spécifié, la valeur par défaut est 10. Un groupe NEAR correspond à un document si celui-ci contient au moins un ensemble de tokens qui :
- comprend au moins une occurrence de chaque phrase, et
- pour lequel le nombre de tokens entre la fin de la première phrase et le début de la dernière phrase dans l’ensemble est inférieur ou égal à N.
Prenons un exemple :
CREATE VIRTUAL TABLE f USING fts5(x);
INSERT INTO f(rowid, x) VALUES(1, 'A B C D x x x E F x');
... MATCH 'NEAR(e d, 4)'; -- Correspond !
... MATCH 'NEAR(e d, 3)'; -- Correspond !
... MATCH 'NEAR(e d, 2)'; -- Ne correspond pas !
... MATCH 'NEAR("c d" "e f", 3)'; -- Correspond !
... MATCH 'NEAR("c" "e f", 3)'; -- Ne correspond pas !
... MATCH 'NEAR(a d e, 6)'; -- Correspond !
... MATCH 'NEAR(a d e, 5)'; -- Ne correspond pas !
... MATCH 'NEAR("a b c d" "b c" "e f", 4)'; -- Correspond !
... MATCH 'NEAR("a b c d" "b c" "e f", 3)'; -- Ne correspond pas !
Filtres de Colonnes FTS5
Il est possible de restreindre une phrase ou un groupe NEAR à un texte spécifique dans une colonne donnée de la table FTS en préfixant celle-ci avec le nom de la colonne suivi d’un caractère deux-points. Pour plusieurs colonnes, on peut utiliser une liste de noms de colonnes séparés par des espaces, entourée de parenthèses, suivie d’un deux-points. Les noms de colonnes peuvent être spécifiés selon les deux formats décrits pour les chaînes. Contrairement aux chaînes qui font partie des phrases, les noms de colonnes ne sont pas transmis au module de tokenisation. Les noms de colonnes ne tiennent pas compte de la casse, conformément aux conventions habituelles des noms de colonnes SQLite.
... MATCH 'nom_colonne : NEAR("un deux" "trois quatre", 10)'
... MATCH '"nom_colonne" : un + deux + trois'
... MATCH '{col1 col2} : NEAR("un deux" "trois quatre", 10)'
... MATCH '{col2 col1 col3} : un + deux + trois'
Si une spécification de filtre de colonne est précédée d’un caractère « -« , elle est interprétée comme une liste de colonnes à ne pas prendre en compte. Par exemple :
-- Rechercher des correspondances dans toutes les colonnes sauf "nom_colonne"
... MATCH '- nom_colonne : NEAR("un deux" "trois quatre", 10)'
-- Rechercher des correspondances dans toutes les colonnes sauf "col1", "col2" et "col3"
... MATCH '- {col2 col1 col3} : un + deux + trois'
Les spécifications de filtre de colonne peuvent également être appliquées à des expressions arbitraires entre parenthèses. Dans ce cas, le filtre de colonne s’applique à toutes les phrases de l’expression. Les opérations de filtre de colonne imbriquées ne peuvent que restreindre davantage le sous-ensemble de colonnes correspondantes, sans réactiver les colonnes filtrées. Par exemple :
-- Les deux suivants sont équivalents :
... MATCH '{a b} : ( {b c} : "bonjour" AND "monde" )'
... MATCH '(b : "bonjour") AND ({a b} : "monde")'
Enfin, un filtre de colonne pour une seule colonne peut être spécifié en utilisant le nom de la colonne comme partie gauche d’un opérateur MATCH (au lieu du nom habituel de la table). Par exemple :
-- Étant donné la table suivante CREATE VIRTUAL TABLE ft USING fts5(a, b, c); -- Les deux suivants sont équivalents SELECT * FROM ft WHERE b MATCH 'uvw AND xyz'; SELECT * FROM ft WHERE ft MATCH 'b : (uvw AND xyz)'; -- Cette requête ne peut correspondre à aucune ligne (puisque toutes les colonnes sont filtrées) : SELECT * FROM ft WHERE b MATCH 'a : xyz';
Opérateurs Booléens FTS5
Les phrases et les groupes NEAR peuvent être combinés en expressions à l’aide d’opérateurs booléens. Par ordre de priorité, des plus élevés (groupement le plus serré) aux plus bas (groupement le plus lâche), les opérateurs sont :
| Opérateur | Fonction |
|---|---|
|
Correspond si query1 correspond et query2 ne correspond pas. |
|
Correspond si query1 et query2 correspondent. |
|
Correspond si query1 ou query2 correspondent. |
Des parenthèses peuvent être utilisées pour regrouper des expressions afin de modifier la priorité des opérateurs de manière habituelle. Par exemple :
-- Puisque NOT groupe plus étroitement que OR, l'un des suivants peut -- être utilisé pour correspondre à tous les documents contenant le token "deux" mais pas -- "trois", ou contenant le token "un". ... MATCH 'un OU deux NOT trois' ... MATCH 'un OU (deux NOT trois)' -- Correspond à des documents contenant au moins une instance de "un" -- ou "deux", mais ne contenant aucune instance du token "trois". ... MATCH '(un OU deux) NOT trois'
Les phrases et les groupes NEAR peuvent également être reliés par des opérateurs AND implicites. Pour simplifier, ceux-ci ne sont pas montrés dans la grammaire BNF ci-dessus. En essence, toute séquence de phrases ou de groupes NEAR (y compris ceux restreints à des colonnes spécifiques) est considérée comme une conjonction.
Création et Initialisation des Tables FTS5
Lors de l’utilisation de l’instruction « CREATE VIRTUAL TABLE … USING fts5 … », chaque argument spécifié peut être soit une déclaration de colonne, soit une option de configuration. Une déclaration de colonne se compose d’un ou plusieurs mots-clés FTS5 ou de littéraux de chaîne séparés par des espaces.
Le premier mot ou littéral dans une déclaration de colonne représente le nom de la colonne. Il est interdit de nommer une colonne d’une table fts5 « rowid » ou « rank », ou d’utiliser un nom déjà attribué à une colonne de la table. Cela n’est pas autorisé.
Les mots ou littéraux suivants dans une déclaration de colonne sont des options qui modifient le comportement de cette colonne. Les options de colonne ne tiennent pas compte de la casse. Contrairement au cœur de SQLite, FTS5 considère les options de colonne non reconnues comme des erreurs. Actuellement, la seule option reconnue est « UNINDEXED ».
Une option de configuration se compose d’un mot-clé FTS5 - le nom de l’option – suivi d’un caractère « = » et de la valeur de l’option. La valeur de l’option peut être soit un mot-clé FTS5, soit un littéral de chaîne, à nouveau cité de manière acceptable pour le cœur de SQLite. Par exemple :
CREATE VIRTUAL TABLE mail USING fts5(expéditeur, titre, corps, tokenize='porter ascii');
Les options de configuration actuellement disponibles incluent :
- L’option « tokenize », utilisée pour configurer un tokenizer personnalisé.
- L’option « prefix », qui permet d’ajouter des index de préfixe à une table FTS5.
- L’option « content », qui permet de faire de la table FTS5 une table de contenu externe ou sans contenu.
- L’option « content_rowid », utilisée pour définir le champ rowid d’une table de contenu externe.
- L’option « columnsize », qui configure si la taille en tokens de chaque valeur dans la table FTS5 est stockée séparément dans la base de données.
- L’option « detail », qui peut être utilisée pour réduire la taille de l’index FTS sur disque en omettant certaines informations.
Option de Colonne UNINDEXED
Les colonnes marquées avec l’option UNINDEXED ne sont pas ajoutées à l’index FTS. Cela signifie que, pour les requêtes MATCH et les fonctions auxiliaires FTS5, la colonne ne contient aucun token pouvant être apparié.
Par exemple, pour éviter d’ajouter le contenu du champ « uuid » à l’index FTS :
CREATE VIRTUAL TABLE clients USING fts5(nom, adresse, uuid UNINDEXED);
Index de Préfixe FTS5
Par défaut, FTS5 maintient un index unique qui enregistre la position de chaque instance de token dans l’ensemble de documents. Cela permet des requêtes rapides pour des tokens complets, nécessitant une seule recherche, mais les requêtes pour des tokens de préfixe peuvent être plus lentes, car elles nécessitent un balayage de plage. Par exemple, pour interroger le token de préfixe « abc* », un balayage de tous les tokens supérieurs ou égaux à »abc » et inférieurs à « abd » est nécessaire.
Un index de préfixe est un index distinct qui enregistre la position de toutes les instances de tokens de préfixe d’une certaine longueur en caractères, utilisé pour accélérer les requêtes pour ces tokens. Par exemple, pour optimiser une requête pour le token de préfixe « abc* », un index de préfixe de trois caractères est nécessaire.
Pour ajouter des index de préfixe à une table FTS5, l’option « prefix » doit être définie sur un entier positif ou une valeur textuelle contenant une liste séparée par des espaces d’un ou plusieurs entiers positifs. Un index de préfixe est créé pour chaque entier spécifié. Si plusieurs options « prefix » sont spécifiées dans une seule instruction CREATE VIRTUAL TABLE, toutes s’appliquent.
CREATE VIRTUAL TABLE ft USING fts5(a, b, prefix='2 3');
Tokenizers FTS5
L’option « tokenize » de CREATE VIRTUAL TABLE est utilisée pour configurer le tokenizer spécifique utilisé par la table FTS5. L’argument de l’option doit être soit un mot-clé FTS5, soit un littéral de texte SQL. Le texte de l’argument est traité comme une série d’espaces de un ou plusieurs mots-clés FTS5 ou littéraux de texte SQL. Le premier de ces éléments est le nom du tokenizer à utiliser. Les éléments suivants, s’ils existent, sont des arguments passés à l’implémentation du tokenizer.
Contrairement aux valeurs d’options et aux noms de colonnes, les littéraux de texte SQL destinés à être des tokenizers doivent être cités avec des guillemets simples. Par exemple :
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize='porter ascii');
FTS5 propose quatre modules de tokenizer intégrés, décrits dans les sections suivantes :
- Le tokenizer unicode61, basé sur la norme Unicode 6.1. C’est le tokenizer par défaut.
- Le tokenizer ascii, qui considère tous les caractères en dehors de rn comme des tokens.
Comprendre les Tokenizers dans FTS5
Dans le cadre de l’indexation et de la recherche de texte, FTS5 (Full-Text Search 5) propose plusieurs types de tokenizers qui permettent de segmenter le texte en unités significatives appelées tokens. Voici un aperçu des différents tokenizers disponibles et de leurs fonctionnalités.
Tokenizers Disponibles
- Le tokenizer ASCII, qui traite les caractères dans la plage de code ASCII (0-127) comme des caractères de token.
- Le tokenizer Porter, qui applique l’algorithme de racinisation Porter.
- Le tokenizer Trigramme, qui considère chaque séquence continue de trois caractères comme un token, permettant ainsi un appariement de sous-chaînes plus général.
FTS5 permet également la création de tokenizers personnalisés. Les détails de l’API pour cette personnalisation sont disponibles dans la documentation.
Tokeniseur Unicode61
Le tokenizer Unicode61 classe tous les caractères Unicode en tant que caractères « séparateurs » ou « tokens ». Par défaut, tous les espaces et signes de ponctuation, tels que définis par Unicode 6.1, sont considérés comme des séparateurs, tandis que tous les autres caractères sont considérés comme des tokens. Plus précisément, tous les caractères Unicode appartenant à une catégorie générale commençant par « L » ou »N » (lettres et chiffres) ou à la catégorie « Co » (utilisation privée) sont considérés comme des tokens. Tous les autres caractères sont des séparateurs.
Chaque séquence continue d’un ou plusieurs caractères de token est considérée comme un token. Le tokenizer est insensible à la casse selon les règles définies par Unicode 6.1.
Par défaut, les diacritiques sont supprimés de tous les caractères en écriture latine. Par exemple, « A », « a », « À », « à », « Â » et « â » sont tous considérés comme équivalents.
Les arguments qui suivent « unicode61 » dans la spécification du token sont interprétés comme une liste de noms d’options et de valeurs alternées. Unicode61 prend en charge les options suivantes :
| Option | Utilisation |
|---|---|
| remove_diacritics | Cette option peut être définie sur « 0 », « 1 » ou « 2 ». La valeur par défaut est « 1 ». Si elle est définie sur « 1 » ou « 2 », les diacritiques sont supprimés des caractères latins. Si elle est définie sur »1″, les diacritiques ne sont pas supprimés dans le cas rare où un seul point de code Unicode représente un caractère avec plusieurs diacritiques. Si elle est définie sur « 2 », les diacritiques sont correctement supprimés de tous les caractères latins. |
| categories | Cette option permet de modifier l’ensemble des catégories générales Unicode considérées comme correspondant à des caractères de token. L’argument doit être une liste séparée par des espaces d’abréviations de catégories générales à deux caractères (par exemple, »Lu » ou « Nd »). La valeur par défaut est « L* N* Co ». |
| tokenchars | Cette option spécifie des caractères Unicode supplémentaires à considérer comme des caractères de token, même s’ils sont des espaces ou des signes de ponctuation selon Unicode 6.1. |
| separators | Cette option spécifie des caractères Unicode supplémentaires à considérer comme des caractères séparateurs, même s’ils sont des caractères de token selon Unicode 6.1. |
Exemple d’utilisation :
-- Créer une table FTS5 qui ne supprime pas les diacritiques des caractères latins
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize="unicode61 remove_diacritics 0 tokenchars '-_'"
);
Tokeniseur ASCII
Le tokenizer ASCII fonctionne de manière similaire au tokenizer Unicode61, mais avec quelques différences :
- Tous les caractères non-ASCII (ceux avec des points de code supérieurs à 127) sont toujours considérés comme des caractères de token. Si des caractères non-ASCII sont spécifiés dans l’option des séparateurs, ils sont ignorés.
- La conversion de casse n’est effectuée que pour les caractères ASCII. Ainsi, »A » et « a » sont considérés comme équivalents, tandis que « Ã » et « ã » sont distincts.
- L’option remove_diacritics n’est pas prise en charge.
Exemple d’utilisation :
-- Créer une table FTS5 qui utilise le tokenizer ASCII, mais ne considère pas les caractères numériques comme des tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize="ascii separators '0123456789'"
);
Tokeniseur Porter
Le tokenizer Porter est un tokenizer d’enveloppement. Il prend la sortie d’un autre tokenizer et applique l’algorithme de racinisation Porter à chaque token avant de le renvoyer à FTS5. Cela permet aux termes de recherche comme « correction » de correspondre à des mots similaires tels que « corrigé » ou « corrigeant ». L’algorithme de racinisation Porter est conçu pour être utilisé avec des termes en anglais uniquement – son utilisation avec d’autres langues peut ou non améliorer l’utilité de la recherche.
Par défaut, le tokenizer Porter fonctionne comme un enveloppe autour du tokenizer par défaut (unicode61). Si un ou plusieurs arguments supplémentaires sont ajoutés à l’option « tokenize » après « porter », ils sont interprétés comme une spécification pour le tokenizer sous-jacent utilisé par le raciniseur Porter. Par exemple :
-- Deux façons de créer une table FTS5 qui utilise le tokenizer Porter pour
-- raciniser la sortie du tokenizer par défaut (unicode61).
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize=porter);
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize='porter unicode61');
-- Un tokenizer Porter utilisé pour raciniser la sortie du tokenizer unicode61,
-- avec les diacritiques supprimés avant la racinisation.
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize='porter unicode61 remove_diacritics 1');
Tokeniseur Trigramme
Le tokenizer Trigramme étend FTS5 pour prendre en charge l’appariement de sous-chaînes en général, au lieu de l’appariement habituel de tokens. Lors de l’utilisation du tokenizer trigramme, un terme de requête ou un token de phrase peut correspondre à n’importe quelle séquence de caractères dans une ligne, et pas seulement à un token complet. Par exemple :
CREATE VIRTUAL TABLE tri USING fts5(a, tokenize="trigram");
Comprendre le Tokenizer Trigramme dans FTS5
Le tokenizer trigramme est un outil puissant utilisé dans les bases de données pour améliorer la recherche de texte intégral. Il permet de diviser le texte en séquences de trois caractères, appelées trigrammes, facilitant ainsi la recherche de motifs complexes dans les données textuelles.
Options du Tokenizer Trigramme
Le tokenizer trigramme propose plusieurs options configurables qui influencent son comportement lors de l’indexation et de la recherche.
| Option | Utilisation |
|---|---|
| case_sensitive |
Cette option peut être définie sur 1 (sensible à la casse) ou 0 (insensible à la casse par défaut). Si elle est réglée sur 1, la recherche tiendra compte de la casse des caractères. |
| remove_diacritics |
Cette option peut également être définie sur 1 ou 0 (valeur par défaut). Elle ne peut être activée que si l’option case_sensitive est réglée sur 0. Si activée, les diacritiques sont supprimés avant la recherche, permettant ainsi des correspondances plus flexibles. |
Indexation et Requêtes avec le Tokenizer Trigramme
Lorsqu’un index trigramme est créé avec l’option case_sensitive activée, il ne peut indexer que les requêtes GLOB, et non les requêtes LIKE. Par exemple, une requête pour rechercher un motif spécifique pourrait ressembler à ceci :
SELECT * FROM tri WHERE a LIKE '%cdefg%'; SELECT * FROM tri WHERE a GLOB '*ij klm*xyz';
Il est important de noter que les sous-chaînes de moins de trois caractères Unicode ne renvoient aucun résultat lors d’une requête de texte intégral. Si un motif LIKE ou GLOB ne contient pas au moins une séquence de caractères Unicode non génériques, FTS5 effectuera une recherche linéaire dans toute la table.
Tables de Contenu Externe et Tables Sans Contenu
Lorsqu’une ligne est insérée dans une table FTS5, une copie du contenu original est généralement créée. Cependant, il est possible de créer une table FTS5 qui ne stocke que les entrées d’index de texte intégral, ce qui peut économiser de l’espace dans la base de données.
Tables Sans Contenu
Une table FTS5 sans contenu est créée en définissant l’option « content » sur une chaîne vide. Par exemple :
CREATE VIRTUAL TABLE f1 USING fts5(a, b, c, content='');
Ces tables ne prennent pas en charge les instructions UPDATE ou DELETE, ni les INSERT sans valeur non nulle pour le champ rowid. Les tentatives de lecture de valeurs de colonnes autres que rowid renverront une valeur NULL.
Tables de Suppression Sans Contenu
Depuis la version 3.43.0, il existe également des tables de suppression sans contenu. Celles-ci permettent des opérations de DELETE et d’INSERT OR REPLACE, tout en maintenant une structure similaire aux tables sans contenu.
CREATE VIRTUAL TABLE f1 USING fts5(a, b, c, content='', contentless_delete=1);
Ces tables prennent en charge les mises à jour, mais uniquement si de nouvelles valeurs sont fournies pour toutes les colonnes définies par l’utilisateur.
Tables de Contenu Externe
Une table FTS5 de contenu externe est créée en spécifiant le nom d’une table, d’une table virtuelle ou d’une vue dans la même base de données. Cela permet à FTS5 d’accéder aux valeurs de colonne à tout moment, garantissant ainsi que les résultats des requêtes sont cohérents avec les données sous-jacentes.
le tokenizer trigramme et les différentes options de configuration qu’il offre permettent d’optimiser la recherche de texte intégral dans les bases de données, tout en offrant une flexibilité dans la gestion des données.# Comprendre les Tables de Contenu Externes FTS5
## Introduction aux Requêtes FTS5
Lorsqu’il s’agit d’interroger une table de contenu avec FTS5, la requête se présente comme suit, où l’identifiant de ligne (rowid) de la ligne pour laquelle les valeurs sont nécessaires est lié à une variable SQL :
« `sql
SELECT
« `
Dans cette requête, `
« `sql
— Si le schéma de la base de données est :
CREATE TABLE tbl (a, b, c, d INTEGER PRIMARY KEY);
CREATE VIRTUAL TABLE fts USING fts5(a, c, content=tbl, content_rowid=d);
— FTS5 peut émettre des requêtes telles que :
SELECT d, a, c FROM tbl WHERE d=?;
« `
## Interrogation de la Table de Contenu
La table de contenu peut également être interrogée de la manière suivante :
« `sql
SELECT
SELECT
« `
Il incombe à l’utilisateur de s’assurer que le contenu d’une table FTS5 externe est maintenu à jour par rapport à la table de contenu. Une méthode pour y parvenir est l’utilisation de déclencheurs (triggers). Par exemple :
« `sql
— Créer une table et une table FTS5 externe pour l’indexer.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, b, c);
CREATE VIRTUAL TABLE fts_idx USING fts5(b, c, content=’tbl’, content_rowid=’a’);
— Déclencheurs pour maintenir l’index FTS à jour.
CREATE TRIGGER tbl_ai AFTER INSERT ON tbl BEGIN
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
CREATE TRIGGER tbl_ad AFTER DELETE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c) VALUES(‘delete’, old.a, old.b, old.c);
END;
CREATE TRIGGER tbl_au AFTER UPDATE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c) VALUES(‘delete’, old.a, old.b, old.c);
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
« `
## Problèmes Potentiels avec les Tables de Contenu Externes
### Consistance des Tables de Contenu
Il est essentiel que l’utilisateur veille à ce qu’une table de contenu externe FTS5 (c’est-à-dire celle avec une option content=non vide) reste cohérente avec la table de contenu elle-même. Si ces tables deviennent incohérentes, les résultats des requêtes sur la table FTS5 peuvent sembler déroutants et incohérents.
Dans ces cas, les résultats apparemment incohérents des requêtes sur la table de contenu externe FTS5 peuvent être interprétés comme suit :
– Si la requête n’utilise pas l’index de texte intégral (c’est-à-dire qu’elle ne contient pas d’opérateur MATCH ou une syntaxe de fonction de table équivalente), alors la requête est effectivement transmise à la table de contenu externe. Dans ce cas, le contenu de l’index FTS n’a aucun impact sur les résultats de la requête.
– Si la requête utilise l’index de texte intégral, le module FTS5 l’interroge pour obtenir l’ensemble des valeurs rowid correspondant aux documents qui correspondent à la requête. Pour chaque rowid, il exécute une requête similaire à celle-ci pour récupérer les valeurs de colonnes requises, où ‘?’ est remplacé par la valeur rowid, et `
« `sql
SELECT
« `
### Exemples de Cohérence des Données
Prenons un exemple où une base de données est créée avec le script suivant :
« `sql
— Créer et peupler une table.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
INSERT INTO tbl VALUES(1, ‘tout ce qui brille’);
INSERT INTO tbl VALUES(2, ‘n’est pas or’);
— Créer une table FTS5 externe
CREATE VIRTUAL TABLE ft USING fts5(t, content=’tbl’, content_rowid=’a’);
« `
Dans ce cas, la table de contenu contient deux lignes, mais l’index FTS ne contient aucune entrée correspondante. Les requêtes suivantes donneront des résultats incohérents :
« `sql
— Retourne 2 lignes. Comme la requête n’utilise pas l’index FTS, elle est
— exécutée directement sur la table ‘tbl’, et retourne donc les deux lignes.
SELECT * FROM tbl;
— Retourne 0 lignes. Cette requête utilise l’index FTS, qui ne contient actuellement
— aucune entrée. Donc, elle retourne 0 lignes.
SELECT rowid, t FROM ft(‘or’);
« `
Si la base de données était créée et peuplée comme suit :
« `sql
— Créer et peupler une table.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
— Créer une table FTS5 externe
CREATE VIRTUAL TABLE ft USING fts5(t, content=’tbl’, content_rowid=’a’);
INSERT INTO ft(rowid, t) VALUES(1, ‘tout ce qui brille’);
INSERT INTO ft(rowid, t) VALUES(2, ‘n’est pas or’);
« `
Dans ce cas, la table de contenu est vide, mais l’index FTS contient des entrées pour six tokens différents. Les requêtes suivantes donneront des résultats incohérents :
« `sql
— Retourne 0 lignes. Comme elle n’utilise pas l’index FTS, la requête est
— transmise directement à la table ‘tbl’, qui ne contient aucune donnée.
SELECT * FROM tbl;
— Retourne 1 ligne. Le champ « rowid » de la ligne retournée est 2, et
— le champ « t » est défini sur NULL. « t » est NULL car lorsque la table
— de contenu externe « tbl » a été interrogée pour les données associées à la ligne
— avec a=2 (où « a » est la colonne content_rowid), aucune donnée n’a pu être trouvée.
SELECT rowid, t FROM ft(‘or’);
« `
### Conclusion
Comme mentionné précédemment, l’utilisation de déclencheurs sur la table de contenu est une méthode efficace pour garantir la cohérence d’une table de contenu externe FTS5. Toutefois, il est important de noter que les déclencheurs ne s’activent que lorsque des lignes sont insérées, mises à jour ou supprimées.
Gestion des Index FTS5 : Optimisation et Options
Introduction aux Index FTS5
Les index de texte intégral (FTS5) sont essentiels pour la gestion efficace des recherches dans les bases de données. Ils permettent d’indexer des documents et d’effectuer des recherches rapides sur de grandes quantités de données textuelles. Cependant, il est crucial de maintenir la cohérence entre la table de contenu et l’index FTS5 pour garantir des résultats précis.
Problèmes de Cohérence entre les Tables
Lorsqu’une table de contenu est créée, il est possible que l’index FTS5 ne soit pas synchronisé avec les données existantes. Par exemple, si une table est définie comme suit :
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
INSERT INTO tbl VALUES(1, 'tout ce qui brille');
INSERT INTO tbl VALUES(2, 'n’est pas or');
CREATE VIRTUAL TABLE ft USING fts5(t, content='tbl', content_rowid='a');Dans ce cas, l’index FTS5 ne contiendra pas les lignes déjà présentes dans la table de contenu. Les déclencheurs créés pour maintenir l’index à jour ne fonctionneront que pour les modifications effectuées après leur création. Pour résoudre ce problème, la commande ‘rebuild’ peut être utilisée pour reconstruire complètement l’index FTS5 en fonction des données actuelles de la table de contenu.
Option de Taille de Colonne
FTS5 utilise une table de soutien pour stocker la taille de chaque valeur de colonne. Cette fonctionnalité est utile pour le fonctionnement de certaines fonctions de classement, comme la fonction de classement bm25. Pour économiser de l’espace, il est possible de désactiver cette table en définissant l’option de taille de colonne à zéro :
CREATE VIRTUAL TABLE ft USING fts5(a, b, c, columnsize=0);Il est important de noter que si la table est configurée avec columnsize=0, l’API xColumnSize fonctionnera, mais de manière moins efficace, car elle devra compter les tokens à la volée.
Option de Détail
L’option de détail dans FTS5 permet de contrôler la quantité d’informations stockées pour chaque terme dans un document. En fonction de la configuration, il est possible de stocker des informations complètes, uniquement le numéro de colonne, ou aucune information supplémentaire. Par exemple :
CREATE VIRTUAL TABLE ft1 USING fts5(a, b, c);
CREATE VIRTUAL TABLE ft2 USING fts5(a, b, c, detail=column);
CREATE VIRTUAL TABLE ft3 USING fts5(a, b, c, detail=none);Si l’option est définie sur column, certaines requêtes, comme les requêtes NEAR ou les requêtes de phrase, ne seront pas disponibles. En revanche, si l’option est réglée sur none, seules les identifiants de ligne seront stockés, ce qui entraîne des limitations supplémentaires.
Performance des Index FTS5
Des tests ont montré que l’utilisation de l’option de détail a un impact significatif sur la taille de l’index. Par exemple, pour un ensemble de données de 1636 MiB, l’index FTS5 occupait 743 MiB avec detail=full, 340 MiB avec detail=column, et seulement 134 MiB avec detail=none. Cela démontre l’importance de choisir judicieusement les options d’indexation en fonction des besoins spécifiques de l’application.
Conclusion
La gestion des index FTS5 nécessite une attention particulière pour garantir la cohérence et l’efficacité des recherches. En comprenant les différentes options disponibles, telles que la taille de colonne et le détail, les développeurs peuvent optimiser leurs bases de données pour des performances maximales.
Option Tokendata
L’option Tokendata est pertinente uniquement pour les applications qui utilisent des tokenizers personnalisés. En général, les tokenizers peuvent renvoyer des tokens composés de n’importe quelle séquence d’octets, y compris des octets 0x00. Toutefois, si la table spécifie l’option tokendata=1, alors fts5 ignore le premier octet 0x00 ainsi que toute donnée qui suit dans le token lors des opérations de correspondance. Bien que l’intégralité du token soit stockée telle que renvoyée par le tokenizer, elle est ignorée par le cœur de fts5.
La version complète du token, y compris tout octet 0x00 et les données qui suivent, est accessible aux fonctions auxiliaires personnalisées via les API xQueryToken et xInstToken.
Cela peut s’avérer utile pour les fonctions de classement. Un tokenizer personnalisé peut ajouter des données supplémentaires à certains tokens de documents, permettant ainsi à une fonction de classement d’accorder plus de poids à certaines occurrences de tokens (par exemple, ceux présents dans les titres de documents).
De plus, l’association d’un tokenizer personnalisé et d’une fonction auxiliaire personnalisée peut être utilisée pour mettre en œuvre une recherche asymétrique. Le tokenizer pourrait, par exemple, pour chaque token de document, renvoyer la version normalisée et non marquée du token, suivie d’un octet 0x00, puis du texte complet du token provenant du document. Lors d’une requête, fts5 fournirait des résultats comme si tous les caractères de la requête étaient normalisés et non marqués. La fonction auxiliaire personnalisée pourrait ensuite être utilisée dans la clause WHERE de la requête pour filtrer les lignes qui ne correspondent pas en fonction des marquages secondaires ou tertiaires dans les termes du document ou de la requête.
5. Fonctions Auxiliaires
Les fonctions auxiliaires ressemblent aux fonctions scalaires SQL, mais elles ne peuvent être utilisées que dans le cadre de requêtes en texte intégral (celles qui utilisent l’opérateur MATCH, ou LIKE/GLOB avec le tokenizer trigramme) sur une table FTS5. Leurs résultats sont calculés non seulement en fonction des arguments qui leur sont passés, mais aussi en fonction de la correspondance actuelle et de la ligne correspondante. Par exemple, une fonction auxiliaire peut renvoyer une valeur numérique indiquant la précision de la correspondance (voir la fonction bm25()), ou un extrait de texte de la ligne correspondante contenant une ou plusieurs occurrences des termes recherchés (voir la fonction snippet()).
Pour invoquer une fonction auxiliaire, le nom de la table FTS5 doit être spécifié comme premier argument. D’autres arguments peuvent suivre, selon la fonction auxiliaire spécifique invoquée. Par exemple, pour invoquer la fonction « highlight » :
SELECT highlight(email, 2, '', '') FROM email WHERE email MATCH 'fts5'
Les fonctions auxiliaires intégrées fournies par FTS5 sont décrites dans la section suivante. Les applications peuvent également implémenter des fonctions auxiliaires personnalisées en C.
5.1. Fonctions Auxiliaires Intégrées
FTS5 propose trois fonctions auxiliaires intégrées :
- La fonction auxiliaire bm25() renvoie une valeur réelle reflétant la précision de la correspondance actuelle. Les meilleures correspondances se voient attribuer des valeurs numériquement plus faibles.
- La fonction highlight() renvoie une copie du texte d’une des colonnes de la correspondance actuelle, avec chaque occurrence d’un terme recherché entourée d’un balisage spécifié (par exemple « « et « « ).
- La fonction snippet() sélectionne un court extrait de texte d’une des colonnes de la ligne correspondante et le renvoie avec chaque occurrence d’un terme recherché entourée de balisage de la même manière que la fonction highlight(). L’extrait de texte est choisi pour maximiser le nombre de termes distincts recherchés qu’il contient. Un poids plus élevé est accordé aux extraits qui apparaissent au début d’une valeur de colonne ou qui suivent immédiatement des caractères « . » ou « : » dans le texte.
5.1.1. La fonction bm25()
La fonction auxiliaire intégrée bm25() renvoie une valeur réelle indiquant à quel point la ligne actuelle correspond à la requête en texte intégral. Plus la correspondance est bonne, plus la valeur renvoyée est numériquement petite. Une requête telle que celle-ci peut être utilisée pour renvoyer des correspondances par ordre de la meilleure à la moins bonne :
SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts)
Pour calculer le score d’un document, la requête en texte intégral est décomposée en ses phrases constitutives. Le score bm25 pour le document D et la requête Q est ensuite calculé comme suit :
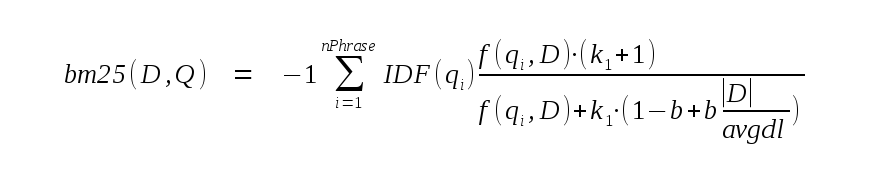
Dans l’expression ci-dessus, nPhrase représente le nombre de phrases dans la requête. |D| est le nombre de tokens dans le document actuel, et avgdl est le nombre moyen de tokens dans tous les documents de la table FTS5. Les constantes k1 et b sont fixées respectivement à 1,2 et 0,75.
Le terme « -1 » au début de la formule n’est pas présent dans la plupart des implémentations de l’algorithme BM25. Sans lui, une meilleure correspondance se verrait attribuer un score BM25 numériquement plus élevé. Étant donné que l’ordre de tri par défaut est « ascendant », cela signifie que l’ajout de « ORDER BY bm25(fts) » à une requête entraînerait le retour des résultats dans l’ordre de la moins bonne à la meilleure correspondance. Le mot-clé « DESC » serait nécessaire pour renvoyer les meilleures correspondances en premier. Pour éviter ce problème, l’implémentation de BM25 dans FTS5 multiplie le résultat par -1 avant de le renvoyer, garantissant ainsi que les meilleures correspondances se voient attribuer des scores numériquement plus faibles.
IDF(qi) est la fréquence inverse des documents pour la phrase de requête i. Elle est calculée comme suit, où N est le nombre total de lignes dans la table FTS5 et n(qi) est le nombre total de lignes contenant au moins une occurrence de la phrase i :
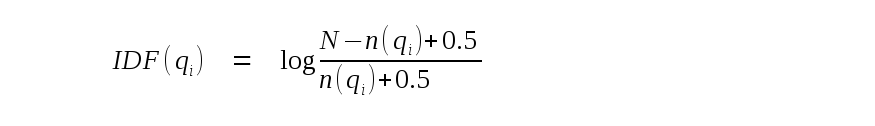
Enfin, f(qi,D) est la fréquence de la phrase i. Par défaut, cela correspond simplement au nombre d’occurrences de la phrase dans la ligne actuelle. Cependant, en passant des arguments de valeur réelle supplémentaires à la fonction SQL bm25(), chaque colonne de la table peut se voir attribuer un poids différent, et la fréquence de la phrase peut être calculée comme suit :
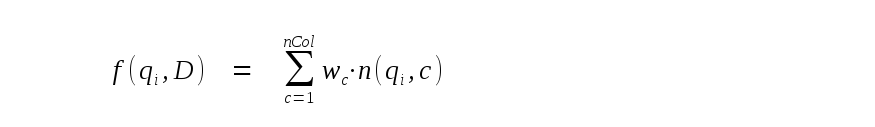
où wc est le poids attribué à la colonne c et n(qi,c) est le nombre d’occurrences de la phrase i dans la colonne c de la ligne actuelle. Le premier argument passé à bm25() après le nom de la table est le poids attribué à la colonne la plus à gauche de la table FTS5. Le second est le poids attribué à la deuxième colonne la plus à gauche, et ainsi de suite. Si le nombre d’arguments n’est pas suffisant pour toutes les colonnes de la table, les arguments restants…
Introduction au FTS5
Le FTS5, ou Full-Text Search 5, est une extension puissante qui permet d’effectuer des recherches textuelles avancées dans des bases de données. Il utilise des structures de données optimisées pour gérer efficacement les requêtes de recherche, offrant ainsi des résultats rapides et pertinents.
Poids des Colonnes dans les Requêtes
Dans FTS5, chaque colonne peut se voir attribuer un poids spécifique, facilitant ainsi la hiérarchisation des résultats. Par exemple, si une colonne est définie avec un poids de 1.0, cela signifie qu’elle a une importance égale dans le processus de recherche. Si des arguments supplémentaires sont fournis, ceux-ci seront ignorés. Voici un exemple :
-- Supposons le schéma suivant : CREATE VIRTUAL TABLE email USING fts5(expéditeur, sujet, contenu); -- Retourner les résultats selon l'ordre bm25, en considérant chaque correspondance dans la colonne "expéditeur" -- comme équivalente à 10 correspondances dans la colonne "contenu", et -- chaque correspondance dans la colonne "sujet" comme équivalente à 5 dans -- la colonne "contenu". SELECT * FROM email WHERE email MATCH ? ORDER BY bm25(email, 10.0, 5.0);
Pour plus de détails sur BM25 et ses variantes, vous pouvez consulter des ressources en ligne.
5.1.2. La fonction highlight()
La fonction highlight() permet de renvoyer une copie du texte d’une colonne spécifiée de la ligne actuelle, avec des balises ajoutées pour marquer le début et la fin des correspondances de phrases.
Cette fonction nécessite trois arguments après le nom de la table :
- Un entier indiquant l’index de la colonne FTS à partir de laquelle lire le texte. Les colonnes sont numérotées de gauche à droite, en commençant par zéro.
- Le texte à insérer avant chaque correspondance de phrase.
- Le texte à insérer après chaque correspondance de phrase.
Par exemple :
-- Retourner une copie du texte de la colonne la plus à gauche de la ligne actuelle, -- avec les correspondances de phrases marquées par des balises "b". SELECT highlight(fts, 0, '', '') FROM fts WHERE fts MATCH ?
Dans les cas où deux ou plusieurs instances de phrases se chevauchent, un seul marqueur d’ouverture et de fermeture est inséré pour chaque ensemble de phrases qui se chevauchent. Par exemple :
-- Supposons ceci :
CREATE VIRTUAL TABLE ft USING fts5(a);
INSERT INTO ft VALUES('a b c x c d e');
INSERT INTO ft VALUES('a b c c d e');
INSERT INTO ft VALUES('a b c d e');
-- La requête suivante retourne ces trois lignes :
-- '[a b c] x [c d e]'
-- '[a b c] [c d e]'
-- '[a b c d e]'
SELECT highlight(ft, 0, '[', ']') FROM ft WHERE ft MATCH 'a+b+c AND c+d+e';
5.1.3. La fonction snippet()
La fonction snippet() fonctionne de manière similaire à highlight(), mais au lieu de renvoyer des valeurs de colonne complètes, elle extrait automatiquement un court extrait de texte à traiter et à renvoyer. Cette fonction nécessite cinq paramètres après le nom de la table :
- Un entier indiquant l’index de la colonne FTS à partir de laquelle sélectionner le texte renvoyé.
- Le texte à insérer avant chaque correspondance de phrase dans le texte renvoyé.
- Le texte à insérer après chaque correspondance de phrase dans le texte renvoyé.
- Le texte à ajouter au début ou à la fin du texte sélectionné pour indiquer que le texte renvoyé ne se trouve pas au début ou à la fin de sa colonne, respectivement.
- Le nombre maximum de tokens dans le texte renvoyé, qui doit être supérieur à zéro et inférieur ou égal à 64.
5.2. Tri par Résultats de Fonction Auxiliaire
Toutes les tables FTS5 possèdent une colonne cachée spéciale nommée « rank ». Si la requête actuelle n’est pas une requête de texte intégral (c’est-à-dire si elle n’inclut pas d’opérateur MATCH), la valeur de la colonne « rank » est toujours NULL. En revanche, dans une requête de texte intégral, la colonne rank contient par défaut la même valeur que celle qui serait renvoyée par l’exécution de la fonction auxiliaire bm25() sans arguments supplémentaires.
La différence entre la lecture de la colonne rank et l’utilisation de la fonction bm25() directement dans la requête n’est significative que lors du tri par la valeur renvoyée. Dans ce cas, utiliser « rank » est plus rapide que d’utiliser bm25().
-- Les requêtes suivantes sont logiquement équivalentes. Cependant, la seconde peut -- être plus rapide, surtout si l'appelant abandonne la requête avant que -- toutes les lignes aient été retournées. SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts); SELECT * FROM fts WHERE fts MATCH ? ORDER BY rank;
Au lieu d’utiliser bm25() sans arguments supplémentaires, la fonction auxiliaire spécifique mappée à la colonne rank peut être configurée soit pour une requête particulière, soit en définissant un paramètre par défaut persistant pour la table FTS.
Pour modifier le mappage de la colonne rank pour une seule requête, un terme similaire à l’un des suivants est ajouté à la clause WHERE d’une requête :
rank MATCH 'nom-fonction-auxiliaire(arg1, arg2, ...)' rank='nom-fonction-auxiliaire(arg1, arg2, ...)'
Le côté droit de l’opérateur MATCH ou = doit être une expression constante qui évalue à une chaîne consistant en la fonction auxiliaire à invoquer, suivie de zéro ou plusieurs arguments séparés par des virgules dans des parenthèses. Les arguments doivent être des littéraux SQL. Par exemple :
-- Les requêtes suivantes sont logiquement équivalentes. Cependant, la seconde peut -- être plus rapide. SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts, 10.0, 5.0); SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)' ORDER BY rank;
La syntaxe de fonction de table peut également être utilisée pour spécifier une fonction de classement alternative. Dans ce cas, le texte décrivant la fonction de classement doit être spécifié comme le deuxième argument de la fonction de table. Les trois requêtes suivantes sont équivalentes :
SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)' ORDER BY rank; SELECT * FROM fts WHERE fts=? AND rank='bm25(10.0, 5.0)' ORDER BY rank; SELECT * FROM fts WHERE fts(?, 'bm25(10.0, 5.0)') ORDER BY rank;
Le mappage par défaut de la colonne rank pour une table peut être modifié à l’aide de l’option de configuration de rang FTS5.
6. Commandes INSERT Spéciales
6.1. L’Option de Configuration ‘automerge’
FTS5 utilise une série de b-arbres au lieu d’une seule structure de données sur disque pour stocker l’index de texte intégral. Chaque fois qu’une nouvelle transaction est validée, un nouvel arbre b est créé, ce qui permet une gestion plus efficace des données et une amélioration des performances lors des opérations de recherche.
L’Indexation en Texte Intégral
Lorsqu’une transaction est validée, son contenu est enregistré dans le fichier de base de données. Lors de l’interrogation de l’index en texte intégral, chaque arbre B (b-tree) doit être interrogé séparément, et les résultats doivent ensuite être fusionnés avant d’être présentés à l’utilisateur.
Optimisation des Arbres B
Pour éviter que le nombre d’arbres B dans la base de données ne devienne trop élevé, ce qui ralentirait les requêtes, des arbres B plus petits sont régulièrement fusionnés en un seul arbre B plus grand contenant les mêmes données. Par défaut, cette opération se fait automatiquement lors des instructions INSERT, UPDATE ou DELETE qui modifient l’index en texte intégral. Le paramètre ‘automerge’ détermine combien d’arbres B plus petits sont fusionnés à la fois. Un réglage à une valeur faible peut accélérer les requêtes, car elles doivent interroger et fusionner les résultats de moins d’arbres B, mais cela peut également ralentir l’écriture dans la base de données, car chaque instruction d’insertion, de mise à jour ou de suppression doit effectuer plus de travail dans le cadre du processus de fusion automatique.
Niveaux des Arbres B
Chaque arbre B qui compose l’index en texte intégral est classé par « niveau » en fonction de sa taille. Les arbres B de niveau 0 sont les plus petits, car ils contiennent le contenu d’une seule transaction. Les arbres de niveaux supérieurs résultent de la fusion de deux ou plusieurs arbres B de niveau 0, ce qui les rend plus grands. FTS5 commence à fusionner les arbres B lorsque le nombre d’arbres B au même niveau atteint M, où M est la valeur du paramètre ‘automerge’.
Paramètre ‘automerge’
La valeur maximale autorisée pour le paramètre ‘automerge’ est de 16, tandis que la valeur par défaut est de 4. Si le paramètre ‘automerge’ est réglé à 0, la fusion incrémentielle automatique des arbres B est complètement désactivée.
INSERT INTO ft(ft, rank) VALUES('automerge', 8);
Option de Configuration ‘crisismerge’
L’option ‘crisismerge’ fonctionne de manière similaire à ‘automerge’, en déterminant comment et à quelle fréquence les arbres B qui composent l’index en texte intégral sont fusionnés. Lorsque le nombre d’arbres B à un même niveau atteint C, où C est la valeur de l’option ‘crisismerge’, tous les arbres B de ce niveau sont immédiatement fusionnés en un seul arbre B.
La différence entre cette option et ‘automerge’ réside dans le fait qu’une fois la limite ‘automerge’ atteinte, FTS5 commence seulement à fusionner les arbres B. La majeure partie du travail est effectuée lors des opérations INSERT, UPDATE ou DELETE suivantes. En revanche, lorsque la limite ‘crisismerge’ est atteinte, tous les arbres B concernés sont fusionnés immédiatement, ce qui peut prolonger le temps d’exécution d’une opération d’insertion, de mise à jour ou de suppression.
La valeur par défaut de ‘crisismerge’ est de 16, sans limite maximale. Tenter de régler le paramètre ’crisismerge’ à 0 ou 1 équivaut à le définir à la valeur par défaut (16). Il est interdit de définir l’option ‘crisismerge’ à une valeur négative.
INSERT INTO ft(ft, rank) VALUES('crisismerge', 16);
Commande ‘delete’
Cette commande est uniquement disponible avec des contenus externes et des tables sans contenu. Elle permet de supprimer les entrées d’index associées à une seule ligne de l’index en texte intégral. Cette commande et la commande delete-all sont les seules manières de retirer des entrées de l’index en texte intégral d’une table sans contenu.
Pour utiliser cette commande afin de supprimer une ligne, la valeur textuelle ‘delete’ doit être insérée dans la colonne spéciale portant le même nom que la table. L’identifiant de la ligne à supprimer est inséré dans la colonne rowid. Les valeurs insérées dans les autres colonnes doivent correspondre aux valeurs actuellement stockées dans la table. Par exemple :
-- Insérer une ligne avec rowid=14 dans la table fts5.
INSERT INTO ft(rowid, a, b, c) VALUES(14, $a, $b, $c);
-- Supprimer la même ligne de la table fts5.
INSERT INTO ft(ft, rowid, a, b, c) VALUES('delete', 14, $a, $b, $c);
Si les valeurs « insérées » dans les colonnes de texte lors d’une commande ‘delete’ ne correspondent pas à celles actuellement stockées dans la table, les résultats peuvent être imprévisibles.
La raison en est simple : lorsqu’un document est inséré dans la table FTS5, une entrée est ajoutée à l’index en texte intégral pour enregistrer la position de chaque jeton dans le nouveau document. Lorsqu’un document est supprimé, les données d’origine sont nécessaires pour déterminer l’ensemble des entrées à retirer de l’index en texte intégral. Ainsi, si les données fournies à FTS5 lors de la suppression d’une ligne avec cette commande diffèrent de celles utilisées pour déterminer l’ensemble des instances de jetons lors de l’insertion, certaines entrées de l’index en texte intégral peuvent ne pas être correctement supprimées, ou FTS5 peut tenter de retirer des entrées d’index qui n’existent pas. Cela peut laisser l’index en texte intégral dans un état imprévisible, rendant les résultats des requêtes futures peu fiables.
Commande ‘delete-all’
Cette commande est uniquement disponible avec des contenus externes et des tables sans contenu (y compris les tables sans contenu à supprimer). Elle supprime toutes les entrées de l’index en texte intégral.
INSERT INTO ft(ft) VALUES('delete-all');
Option de Configuration ‘deletemerge’
L’option ‘deletemerge’ est utilisée uniquement par les tables sans contenu à supprimer.
Lorsqu’une ligne est supprimée d’une table sans contenu à supprimer, les entrées associées à ses jetons ne sont pas immédiatement retirées de l’index FTS. Au lieu de cela, un marqueur « tombstone » contenant l’identifiant de la ligne supprimée est attaché à l’arbre B qui contient les entrées d’index FTS de la ligne. Lors de l’interrogation de l’arbre B, toutes les lignes de résultats de requête pour lesquelles des marqueurs tombstone existent sont omises. Lorsque l’arbre B est fusionné avec d’autres arbres B, les lignes supprimées et leurs marqueurs tombstone sont toutes deux éliminées.
Cette option spécifie un pourcentage minimum de lignes dans un arbre B qui doivent avoir des marqueurs tombstone avant que l’arbre B ne soit éligible pour la fusion, que ce soit par des fusions automatiques ou par des commandes de fusion explicites de l’utilisateur, même s’il ne répond pas aux critères habituels déterminés par les options ‘automerge’ et ‘usermerge’.
Par exemple, pour indiquer que FTS5 doit envisager de fusionner un arbre B composant après que 15 % de ses lignes aient des marqueurs tombstone :
INSERT INTO ft(ft, rank) VALUES('deletemerge', 15);
La valeur par défaut de cette option est de 10. Tenter de la régler à moins de zéro rétablit la valeur par défaut. Réglage de cette option à 0 ou à une valeur supérieure à 100 garantit que les arbres B ne seront jamais éligibles pour la fusion en raison des marqueurs tombstone.
Commande ‘integrity-check’
Cette commande est utilisée pour vérifier que l’index en texte intégral est cohérent en interne et, en option, qu’il est cohérent avec tout contenu externe.
La commande de vérification d’intégrité est activée en insérant la valeur textuelle ‘integrity-check’ dans la colonne spéciale portant le même nom que la table FTS5. Si une valeur est fournie pour la colonne « rank », elle doit être soit 0, soit 1. Par exemple :
INSERT INTO ft(ft) VALUES('integrity-check');
INSERT INTO ft(ft, rank) VALUES('integrity-check', 0);
INSERT INTO ft(ft, rank) VALUES('integrity-check', 1);
Les trois formes ci-dessus sont équivalentes pour toutes les tables FTS qui ne sont pas des tables de contenu externe. Elles vérifient que les structures de données d’index ne sont pas corrompues et, si la table FTS contient des données, que le contenu de l’index correspond à celui de la table elle-même.
Pour une table de contenu externe, le contenu de l’index n’est comparé à celui de la table externe que si la valeur spécifiée pour la colonne de rang est 1.
Dans tous les cas, si des incohérences sont détectées, la commande échoue avec une erreur SQLITE_CORRUPT_VTAB.
6.7. La commande ‘merge’
INSERT INTO ft(ft, rank) VALUES('merge', 500);
Cette commande fusionne les structures B-tree jusqu’à ce qu’environ N pages de données fusionnées aient été écrites dans la base de données, où N est la valeur absolue du paramètre spécifié dans la commande ‘merge’. La taille de chaque page est configurée par l’option pgsz de FTS5.
Si le paramètre est une valeur positive, les structures B-tree ne sont éligibles à la fusion que si l’une des conditions suivantes est remplie :
- Il y a U ou plus de ces B-trees à un même niveau (voir la documentation pour l’option automerge de FTS5 pour une explication des niveaux de B-tree), où U est la valeur assignée à l’option usermerge de FTS5.
- Une fusion a déjà été initiée (peut-être par une commande ‘merge’ qui spécifiait un paramètre négatif).
Il est possible de déterminer si la commande ’merge’ a trouvé des B-trees à fusionner en vérifiant la valeur retournée par l’API sqlite3_total_changes() avant et après l’exécution de la commande. Si la différence entre les deux valeurs est de 2 ou plus, alors un travail a été effectué. Si la différence est inférieure à 2, la commande ‘merge’ n’a eu aucun effet. Dans ce cas, il n’est pas nécessaire d’exécuter à nouveau la même commande ‘merge’, du moins jusqu’à la prochaine mise à jour de la table FTS.
Si le paramètre est négatif et qu’il y a des structures B-tree sur plus d’un niveau dans l’index FTS, toutes les structures B-tree sont assignées au même niveau avant que l’opération de fusion ne commence. De plus, si le paramètre est négatif, la valeur de l’option usermerge n’est pas respectée – aussi peu que deux B-trees du même niveau peuvent être fusionnés.
Ce qui précède signifie qu’exécuter la commande ‘merge’ avec un paramètre négatif jusqu’à ce que la différence entre les valeurs retournées par sqlite3_total_changes() soit inférieure à deux optimise l’index FTS de la même manière que la commande d’optimisation FTS5. Cependant, si un nouveau B-tree est ajouté à l’index FTS pendant ce processus, FTS5 déplacera le nouveau B-tree au même niveau que les B-trees existants et redémarrera la fusion. Pour éviter cela, seule la première invocation de ‘merge’ doit spécifier un paramètre négatif. Chaque appel suivant à ‘merge’ doit spécifier une valeur positive afin que la fusion commencée par le premier appel soit menée à bien, même si de nouveaux B-trees sont ajoutés à l’index FTS.
6.8. La commande ‘optimize’
Cette commande fusionne tous les B-trees individuels qui composent actuellement l’index de texte intégral en une seule grande structure B-tree. Cela garantit que l’index de texte intégral utilise l’espace minimum dans la base de données et est dans la forme la plus rapide pour les requêtes.
Pour plus de détails concernant la relation entre l’index de texte intégral et ses B-trees composants, consultez la documentation sur l’option automerge de FTS5.
INSERT INTO ft(ft) VALUES('optimize');
Étant donné qu’elle réorganise l’ensemble de l’index FTS, la commande d’optimisation peut prendre beaucoup de temps à s’exécuter. La commande de fusion FTS5 peut être utilisée pour diviser le travail d’optimisation de l’index FTS en plusieurs étapes. Pour ce faire :
- Appelez la commande ‘merge’ une fois avec le paramètre défini sur -N, puis
- Appelez la commande ’merge’ zéro ou plusieurs fois avec le paramètre défini sur N.
où N est le nombre de pages de données à fusionner dans chaque invocation de la commande merge. L’application doit cesser d’invoquer merge lorsque la différence dans la valeur retournée par la fonction sqlite3_total_changes() avant et après la commande merge tombe en dessous de deux. Les commandes de fusion peuvent être émises dans le cadre de la même transaction ou de transactions séparées, et par le même client de base de données ou des clients différents. Consultez la documentation de la commande merge pour plus de détails.
6.9. L’option de configuration ‘pgsz’
Cette commande est utilisée pour définir l’option persistante « pgsz ».
L’index de texte intégral maintenu par FTS5 est stocké sous forme de séries de blobs de taille fixe dans une table de base de données. Il n’est pas strictement nécessaire que tous les blobs qui composent un index de texte intégral soient de la même taille. L’option pgsz détermine la taille de tous les blobs créés par les écrivains d’index suivants. La valeur par défaut est 1000.
INSERT INTO ft(ft, rank) VALUES('pgsz', 4072);
6.10. L’option de configuration ‘rank’
Cette commande est utilisée pour définir l’option persistante »rank ».
L’option de rang est utilisée pour modifier la fonction auxiliaire par défaut pour la colonne de rang. L’option doit être définie sur une valeur textuelle dans le même format que celui décrit pour les termes « rank MATCH ? ». Par exemple :
INSERT INTO ft(ft, rank) VALUES('rank', 'bm25(10.0, 5.0)');
6.11. La commande ‘rebuild’
Cette commande supprime d’abord l’intégralité de l’index de texte intégral, puis le reconstruit en fonction du contenu de la table ou de la table de contenu. Elle n’est pas disponible avec des tables sans contenu.
INSERT INTO ft(ft) VALUES('rebuild');
6.12. L’option de configuration ‘secure-delete’
Cette commande est utilisée pour définir l’option booléenne persistante « secure-delete ». Par exemple :
INSERT INTO ft(ft, rank) VALUES('secure-delete', 1);
Normalement, lorsqu’une entrée dans une table fts5 est mise à jour ou supprimée, au lieu de retirer les entrées de l’index de texte intégral, des clés de suppression sont ajoutées au nouveau B-tree créé par la commande.
La gestion des entrées d’indexation dans les bases de données peut s’avérer complexe, notamment en ce qui concerne les opérations de suppression et de mise à jour. Lorsqu’une transaction est effectuée, les anciennes entrées d’indexation en texte intégral demeurent dans le fichier de la base de données jusqu’à ce qu’elles soient finalement éliminées par des opérations de fusion sur l’index. Cela signifie que toute personne ayant accès à la base de données peut facilement reconstruire le contenu des lignes de table supprimées. Cependant, en activant l’option ‘secure-delete’ à 1, les entrées d’indexation en texte intégral sont effectivement supprimées de la base de données lors de la mise à jour ou de la suppression des lignes de la table FTS5. Bien que ce processus soit plus lent, il empêche la récupération des anciennes entrées pour reconstituer les lignes supprimées.
Cette option garantit que les anciennes entrées d’indexation ne sont pas accessibles aux attaquants ayant un accès SQL à la base de données. Pour renforcer la sécurité et s’assurer qu’elles ne peuvent pas être récupérées par des attaquants ayant accès au fichier de base de données SQLite, l’application doit également activer l’option de suppression sécurisée du cœur SQLite avec une commande telle que « PRAGMA secure_delete=1 ».
Avertissement : Une fois qu’une ou plusieurs lignes de table ont été mises à jour ou supprimées avec cette option activée, la table FTS5 ne pourra plus être lue ou écrite par les versions antérieures à 3.42.0 (la première version à proposer cette option). Tenter de le faire entraînera une erreur, avec un message du type « format de fichier fts5 invalide (trouvé 5, attendu 4) – exécutez ‘rebuild' ». Le format de fichier FTS5 peut être rétabli pour être lu par des versions antérieures en exécutant la commande ‘rebuild’ sur la table avec la version 3.42.0 ou ultérieure.
La valeur par défaut de l’option de suppression sécurisée est 0.
Option de Configuration ‘usermerge’
Cette commande permet de définir l’option persistante « usermerge ».
L’option usermerge est comparable aux options automerge et crisismerge. Elle représente le nombre minimum de segments d’arbre B qui seront fusionnés par une commande ’merge’ avec un paramètre positif. Par exemple :
INSERT INTO ft(ft, rank) VALUES('usermerge', 4);La valeur par défaut de l’option usermerge est 4. La valeur minimale autorisée est 2, et la valeur maximale est 16.
Extension de FTS5
FTS5 propose des API permettant son extension par :
- L’ajout de nouvelles fonctions auxiliaires implémentées en C.
- L’ajout de nouveaux tokenizers, également implémentés en C.
Les tokenizers et fonctions auxiliaires intégrés décrits dans ce document sont tous implémentés à l’aide de l’API publique décrite ci-dessous.
Avant qu’une nouvelle fonction auxiliaire ou une implémentation de tokenizer puisse être enregistrée avec FTS5, une application doit obtenir un pointeur vers la structure « fts5_api ». Il existe une structure fts5_api pour chaque connexion de base de données avec laquelle l’extension FTS5 est enregistrée. Pour obtenir le pointeur, l’application invoque la fonction SQL définie par l’utilisateur fts5() avec un seul argument. Cet argument doit être un pointeur vers un pointeur vers un objet fts5_api en utilisant l’interface sqlite3_bind_pointer(). Le code d’exemple suivant illustre cette technique :
/*
** Retourne un pointeur vers le pointeur fts5_api pour la connexion de base de données db.
** En cas d'erreur, retourne NULL et laisse une erreur dans le handle de la base de données
** (accessible via sqlite3_errcode()/errmsg()).
*/
fts5_api *fts5_api_from_db(sqlite3 *db){
fts5_api *pRet=0;
sqlite3_stmt *pStmt=0;
if( SQLITE_OK==sqlite3_prepare(db, "SELECT fts5(?1)", -1, &pStmt, 0) ){
sqlite3_bind_pointer(pStmt, 1, (void*)&pRet, "fts5_api_ptr", NULL);
sqlite3_step(pStmt);
}
sqlite3_finalize(pStmt);
return pRet;
}Avertissement de Compatibilité : Avant la version 3.20.0 de SQLite (2017-08-01), la fonction fts5() fonctionnait légèrement différemment. Les anciennes applications qui étendent FTS5 doivent être révisées pour utiliser la nouvelle technique décrite ci-dessus.
La structure fts5_api est définie comme suit. Elle expose trois méthodes, une pour enregistrer de nouvelles fonctions auxiliaires et tokenizers, et une pour récupérer un tokenizer existant. Cette dernière est destinée à faciliter l’implémentation de »wrappers de tokenizer » similaires au tokenizer porter intégré.
typedef struct fts5_api fts5_api;
struct fts5_api {
int iVersion; /* Actuellement toujours fixé à 2 */
/* Créer un nouveau tokenizer */
int (*xCreateTokenizer)(
fts5_api *pApi,
const char *zName,
void *pUserData,
fts5_tokenizer *pTokenizer,
void (*xDestroy)(void*)
);
/* Trouver un tokenizer existant */
int (*xFindTokenizer)(
fts5_api *pApi,
const char *zName,
void **ppUserData,
fts5_tokenizer *pTokenizer
);
/* Créer une nouvelle fonction auxiliaire */
int (*xCreateFunction)(
fts5_api *pApi,
const char *zName,
void *pUserData,
fts5_extension_function xFunction,
void (*xDestroy)(void*)
);
};Pour invoquer une méthode de l’objet fts5_api, le pointeur fts5_api lui-même doit être passé comme premier argument, suivi des autres arguments spécifiques à la méthode. Par exemple :
rc=pFts5Api->xCreateTokenizer(pFts5Api, ... autres arguments ...);Les méthodes de la structure fts5_api sont décrites individuellement dans les sections suivantes.
Tokenizers Personnalisés
Pour créer un tokenizer personnalisé, une application doit implémenter trois fonctions : un constructeur de tokenizer (xCreate), un destructeur (xDelete) et une fonction pour effectuer la tokenisation proprement dite (xTokenize). Le type de chaque fonction est similaire à celui des variables membres de la structure fts5_tokenizer :
typedef struct Fts5Tokenizer Fts5Tokenizer;
typedef struct fts5_tokenizer fts5_tokenizer;
struct fts5_tokenizer {
int (*xCreate)(void*, const char **azArg, int nArg, Fts5Tokenizer **ppOut);
void (*xDelete)(Fts5Tokenizer*);
int (*xTokenize)(Fts5Tokenizer*,
void *pCtx,
int flags, /* Masque des drapeaux FTS5_TOKENIZE_* */
const char *pText, int nText,
int (*xToken)(
void *pCtx, /* Copie du 2ème argument */« `html
Introduction aux Tokenizers Personnalisés dans FTS5
Dans le cadre de l’utilisation de FTS5, il est possible d’intégrer des tokenizers personnalisés pour améliorer la gestion des textes. Ces tokenizers permettent de segmenter le texte en unités significatives, appelées tokens, qui peuvent ensuite être indexées pour des recherches efficaces.
Création et Gestion des Tokenizers
Pour enregistrer un tokenizer avec le module FTS5, il est nécessaire d’utiliser la méthode xCreateTokenizer() de l’objet fts5_api. Si un tokenizer portant le même nom existe déjà, il sera remplacé. En cas de passage d’un paramètre xDestroy non nul à xCreateTokenizer(), cette fonction sera appelée avec une copie du pointeur pUserData lors de la fermeture de la base de données ou du remplacement du tokenizer.
En cas de succès, xCreateTokenizer() renvoie SQLITE_OK. Dans le cas contraire, un code d’erreur SQLite est retourné, et la fonction xDestroy ne sera pas exécutée.
Fonctions Principales des Tokenizers
Lorsqu’une table FTS5 utilise un tokenizer personnalisé, le cœur de FTS5 appelle xCreate() une fois pour créer le tokenizer, puis xTokenize() plusieurs fois pour segmenter les chaînes de caractères, et enfin xDelete() pour libérer les ressources allouées par xCreate().
Fonction xCreate
Cette fonction est utilisée pour allouer et initialiser une instance de tokenizer. L’instance est essentielle pour le processus de tokenisation du texte. Le premier argument est un pointeur (void*) fourni par l’application lors de l’enregistrement de l’objet fts5_tokenizer avec FTS5. Les deuxième et troisième arguments sont un tableau de chaînes de caractères terminées par un caractère nul, contenant les arguments du tokenizer, le cas échéant, spécifiés après le nom du tokenizer dans l’instruction CREATE VIRTUAL TABLE.
Le dernier argument est une variable de sortie. Si l’opération réussit, (*ppOut) doit pointer vers le nouveau handle du tokenizer, et SQLITE_OK doit être retourné. En cas d’erreur, une valeur différente de SQLITE_OK est renvoyée, et la valeur finale de *ppOut est considérée comme indéfinie.
Fonction xDelete
Cette fonction est appelée pour supprimer un handle de tokenizer précédemment alloué via xCreate(). FTS5 garantit que cette fonction sera appelée exactement une fois pour chaque appel réussi à xCreate().
Fonction xTokenize
Cette fonction est chargée de segmenter la chaîne de caractères nText indiquée par l’argument pText. Ce dernier peut ou non être terminé par un caractère nul. Le premier argument est un pointeur vers un objet Fts5Tokenizer obtenu lors d’un appel précédent à xCreate().
Le deuxième argument indique la raison pour laquelle FTS5 demande la tokenisation du texte fourni. Cela peut être l’un des quatre cas suivants :
- FTS5_TOKENIZE_DOCUMENT – Un document est inséré ou retiré de la table FTS. Le tokenizer est appelé pour déterminer les tokens à ajouter ou à supprimer de l’index FTS.
- FTS5_TOKENIZE_QUERY – Une requête MATCH est exécutée contre l’index FTS. Le tokenizer est appelé pour segmenter un mot ou une chaîne de caractères spécifiée dans la requête.
- (FTS5_TOKENIZE_QUERY | FTS5_TOKENIZE_PREFIX) – Semblable à FTS5_TOKENIZE_QUERY, mais la chaîne est suivie d’un caractère « * », indiquant que le dernier token sera traité comme un préfixe.
- FTS5_TOKENIZE_AUX – Le tokenizer est appelé pour satisfaire une demande
fts5_api.xTokenize()d’une fonction auxiliaire.
Pour chaque token dans la chaîne d’entrée, le callback xToken() doit être invoqué. Le premier argument doit être une copie du pointeur passé en second argument à xTokenize(). Les troisième et quatrième arguments sont un pointeur vers un tampon contenant le texte du token et la taille du token en octets. Les quatrième et cinquième arguments sont les décalages en octets du premier octet et du premier octet suivant le texte d’origine du token.
Le deuxième argument passé au callback xToken() (tflags) doit généralement être défini à 0, sauf si le tokenizer prend en charge les synonymes.
FTS5 suppose que le callback xToken() est appelé pour chaque token dans l’ordre d’apparition dans le texte d’entrée.
Si un callback xToken() retourne une valeur autre que SQLITE_OK, la tokenisation doit être abandonnée et xTokenize() doit immédiatement retourner une copie de la valeur retournée par xToken(). Si le tampon d’entrée est épuisé, xTokenize() doit retourner SQLITE_OK. En cas d’erreur dans l’implémentation de xTokenize(), celle-ci peut abandonner la tokenisation et retourner un code d’erreur autre que SQLITE_OK ou SQLITE_DONE.
Support des Synonymes
Les tokenizers personnalisés peuvent également prendre en charge les synonymes. Par exemple, si un utilisateur souhaite interroger une expression telle que « première place », l’utilisation des tokenizers intégrés permettrait de faire correspondre « première place » dans l’ensemble des documents, mais pas des formes alternatives comme « 1ère place ». Dans certaines applications, il serait préférable de faire correspondre toutes les occurrences de « première place » ainsi que ses variantes.
« `
Approches pour la gestion des synonymes dans FTS5
Dans le cadre de la recherche en texte intégral (FTS5), il existe plusieurs méthodes pour traiter les synonymes, permettant ainsi une meilleure flexibilité lors des requêtes. Voici un aperçu des différentes stratégies que l’on peut adopter.
1. Normalisation des synonymes en un seul jeton
La première méthode consiste à mapper tous les synonymes à un seul jeton. Par exemple, si l’on considère les termes « premier » et « 1er », le tokenizer renverra le même jeton pour ces deux entrées. Supposons que ce jeton soit « premier ». Ainsi, lorsque l’utilisateur soumet le document « J’ai gagné 1er place », les entrées ajoutées à l’index seront « j », « ai », « gagné », « premier » et « place ». Si l’utilisateur effectue une recherche avec ’1er + place’, le tokenizer remplacera « 1er » par « premier », et la requête fonctionnera comme prévu.
2. Requêtes séparées pour chaque synonyme
Une autre approche consiste à interroger l’index pour chaque synonyme de manière distincte. Dans ce cas, lors de la tokenisation du texte de la requête, le tokenizer peut fournir plusieurs synonymes pour un même terme. Par exemple, si l’utilisateur effectue une recherche avec « 1er » et « premier », FTS5 exécutera une requête similaire à :
... MATCH '(premier OR 1er) place'
Dans ce scénario, pour les fonctions auxiliaires, la requête est toujours considérée comme contenant deux phrases, « (premier OR 1er) » étant traité comme une seule phrase.
3. Ajout de synonymes multiples à l’index FTS
La troisième méthode consiste à ajouter plusieurs synonymes pour un même terme dans l’index FTS. Ainsi, lorsque le texte d’un document tel que »J’ai gagné premier place » est tokenisé, les entrées « j », « ai », « gagné », « premier », « 1er » et « place » sont ajoutées à l’index. Cela signifie que même si le tokenizer ne fournit pas de synonymes lors de la tokenisation du texte de la requête, il n’est pas problématique si l’utilisateur recherche ‘premier + place’ ou ’1er + place’, car les deux formes du premier jeton sont présentes dans l’index FTS.
Considérations sur l’utilisation des synonymes
Lors de l’analyse du texte d’un document ou d’une requête, toute invocation de xToken qui spécifie un argument tflags avec le bit FTS5_TOKEN_COLOCATED est considérée comme fournissant un synonyme pour le jeton précédent. Par exemple, pour le document « J’ai gagné premier place », un tokenizer prenant en charge les synonymes appellerait xToken() cinq fois, comme suit :
xToken(pCtx, 0, "j", 1, 0, 1); xToken(pCtx, 0, "ai", 3, 2, 5); xToken(pCtx, 0, "gagné", 5, 6, 11); xToken(pCtx, FTS5_TOKEN_COLOCATED, "1er", 3, 6, 11); xToken(pCtx, 0, "place", 5, 12, 17);
Il est important de noter qu’il est incorrect de spécifier le drapeau FTS5_TOKEN_COLOCATED lors de la première invocation de xToken(). On peut spécifier plusieurs synonymes pour un même jeton en effectuant plusieurs appels à xToken(FTS5_TOKEN_COLOCATED) de manière consécutive, sans limite quant au nombre de synonymes pouvant être fournis.
Choix de la méthode appropriée
Dans de nombreux cas, la première méthode est la plus efficace, car elle n’ajoute pas de données supplémentaires à l’index FTS et ne nécessite pas de requêtes pour plusieurs termes, ce qui optimise l’espace disque et la rapidité des requêtes. Cependant, elle ne gère pas très bien les requêtes par préfixe. Si le tokenizer remplace « 1er » par « premier », alors la requête :
ne correspondra pas aux documents contenant le jeton « 1er » (car le tokenizer ne fera probablement pas correspondre « 1s » à un préfixe de « premier »).
Pour un support complet des préfixes, la troisième méthode peut être privilégiée. Dans ce cas, l’index contient des entrées pour « premier » et « 1er », permettant ainsi aux requêtes par préfixe telles que ‘pr*’ ou ‘1s*’ de correspondre correctement. Cependant, cette méthode utilise plus d’espace dans la base de données en raison des entrées supplémentaires ajoutées à l’index FTS.
La méthode intermédiaire (deuxième méthode) permet de faire correspondre des documents contenant le jeton littéral « 1er », mais pas « premier » (à condition que le tokenizer ne puisse pas fournir de synonymes pour les préfixes). Cependant, une requête non préfixe comme ‘1er’ correspondra à « 1er » et « premier ». Cette méthode ne nécessite pas d’espace disque supplémentaire, car aucune entrée supplémentaire n’est ajoutée à l’index FTS. En revanche, elle peut nécessiter plus de cycles CPU pour exécuter les requêtes MATCH, car des requêtes distinctes de l’index FTS sont nécessaires pour chaque synonyme.
Lors de l’utilisation des méthodes (2) ou (3), il est crucial que le tokenizer ne fournisse des synonymes que lors de la tokenisation du texte du document (méthode (3)) ou du texte de la requête (méthode (2)), mais pas les deux simultanément. Bien que cela ne provoque pas d’erreurs, cela reste inefficace.
Fonctions auxiliaires personnalisées dans FTS5
La mise en œuvre d’une fonction auxiliaire personnalisée est similaire à celle d’une fonction SQL scalaire. L’implémentation doit être une fonction C de type fts5_extension_function, définie comme suit :
typedef struct Fts5ExtensionApi Fts5ExtensionApi; typedef struct Fts5Context Fts5Context; typedef struct Fts5PhraseIter Fts5PhraseIter; typedef void (*fts5_extension_function)( const Fts5ExtensionApi *pApi, /* API offerte par la version actuelle de FTS */ Fts5Context *pFts, /* Premier argument à passer aux fonctions pApi */ sqlite3_context *pCtx, /* Contexte pour retourner le résultat/l'erreur */
Fonctionnalités des Fonctions Auxiliaires dans FTS5
La création d'une fonction auxiliaire est réalisée en utilisant la méthode xCreateFunction() de l'objet fts5_api. Si une fonction auxiliaire portant le même nom existe déjà, elle sera remplacée par la nouvelle. Si un paramètre xDestroy non nul est fourni à xCreateFunction(), il sera appelé avec une copie du pointeur pUserData comme unique argument lorsque la connexion à la base de données est fermée ou lorsque la fonction auxiliaire enregistrée est remplacée.
En cas de succès, xCreateFunction() renvoie SQLITE_OK. Dans le cas contraire, un code d'erreur SQLite est retourné, et la fonction xDestroy ne sera pas appelée.
Les trois derniers arguments passés à la fonction auxiliaire (pCtx, nVal et apVal) sont analogues aux trois arguments d'une fonction SQL scalaire. Le tableau apVal[] contient tous les arguments SQL, à l'exception du premier, transmis à la fonction auxiliaire. L'implémentation doit renvoyer un résultat ou une erreur via le gestionnaire de contenu pCtx.
Le premier argument de la fonction auxiliaire est un pointeur vers une structure (pApi) contenant des méthodes qui peuvent être appelées pour obtenir des informations sur la requête ou la ligne actuelle. Le second argument est un identifiant opaque (pFts) qui doit être passé comme premier argument à toute invocation de méthode. Par exemple, la fonction auxiliaire suivante renvoie le nombre total de jetons dans toutes les colonnes de la ligne actuelle :
/* ** Implémentation d'une fonction auxiliaire qui retourne le nombre ** de jetons dans la ligne actuelle (y compris toutes les colonnes). */ static void taille_colonne_imp( const Fts5ExtensionApi *pApi, Fts5Context *pFts, sqlite3_context *pCtx, int nVal, sqlite3_value **apVal ){ int rc; int nToken; rc=pApi->xColumnSize(pFts, -1, &nToken); if( rc==SQLITE_OK ){ sqlite3_result_int(pCtx, nToken); }else{ sqlite3_result_error_code(pCtx, rc); } }La section suivante décrit en détail l'API proposée pour les implémentations de fonctions auxiliaires. D'autres exemples peuvent être trouvés dans le fichier "fts5_aux.c" du code source.
7.2.1. Vue d'ensemble de l'API des Fonctions Auxiliaires Personnalisées
Cette section présente un aperçu des capacités de l'API des fonctions auxiliaires. Elle ne décrit pas chaque fonction. Pour une description complète, veuillez vous référer au texte de référence ci-dessous.
Lorsqu'une fonction auxiliaire est appelée, elle a accès à des API qui lui permettent d'interroger FTS5 pour diverses informations. Certaines de ces API renvoient des informations relatives à la ligne actuelle de la table FTS5 visitée, d'autres concernant l'ensemble des lignes qui seront visitées par la requête FTS5, et certaines se rapportent à la table FTS5 elle-même. Considérons une table FTS5 peuplée comme suit :
CREATE VIRTUAL TABLE ft USING fts5(a, b); INSERT INTO ft(rowid, a, b) VALUES (1, 'ab cd', 'cd de un'), (2, 'de fg', 'fg gh'), (3, 'gh ij', 'ij ab trois quatre');Et la requête :
SELECT ma_fonction_auxiliaire(ft) FROM ft('ab')Dans ce cas, la fonction auxiliaire personnalisée sera invoquée pour les lignes 1 et 3 (toutes les lignes contenant le jeton "ab" et correspondant ainsi à la requête).
Nombre de lignes/colonnes dans la table : xRowCount, xColumnCount
Le système peut être interrogé pour connaître le nombre total de lignes dans la table FTS5 en utilisant l'API xRowCount. Cela fournit le nombre total de lignes dans la table, et non le nombre correspondant à la requête actuelle.
Les colonnes de la table sont numérotées de gauche à droite en commençant par 0. La colonne "rowid" n'est pas comptée - seules les colonnes déclarées par l'utilisateur le sont - donc dans l'exemple ci-dessus, la colonne "a" est la colonne 0 et la colonne "b" est la colonne 1. Dans l'implémentation d'une fonction auxiliaire, l'API xColumnCount peut être utilisée pour déterminer combien de colonnes la table interrogée possède. Si l'API xColumnCount() est appelée dans l'implémentation de la fonction auxiliaire ma_fonction_auxiliaire dans l'exemple ci-dessus, elle renvoie 2.
Données de la Ligne Actuelle : xColumnText, xRowid
L'API xRowid peut être utilisée pour trouver la valeur rowid de la ligne actuelle. L'API xColumnText peut être utilisée pour obtenir le texte stocké dans une colonne spécifiée de la ligne actuelle.
Comptes de Jetons : xColumnSize, xColumnTotalSize
FTS5 divise les documents insérés dans une table fts en jetons. Ceux-ci sont généralement des mots, éventuellement convertis en majuscules ou minuscules et avec toute ponctuation supprimée. Par exemple, le tokenizer unicode61 par défaut tokenize le texte "Le tokenizer est insensible à la casse" en une liste de 5 jetons - "le", "tokenizer", "est", "insensible" et "à". La manière dont les jetons sont extraits du texte est déterminée par le tokenizer.
L'API des fonctions auxiliaires fournit des fonctions pour interroger à la fois le nombre de jetons dans une colonne spécifiée de la ligne actuelle (l'API xColumnSize) ou pour le nombre de jetons dans une colonne spécifiée de toutes les lignes de la table (l'API xColumnTotalSize). Pour l'exemple en haut de cette section, lors de la visite de la ligne 1, xColumnSize renvoie 2 pour la colonne 0 et 3 pour la colonne 1. xColumnTotalSize renvoie 6 pour la colonne 0 et 9 pour la colonne 1, indépendamment de la ligne actuelle.
La Requête de Texte Intégral Actuelle : xPhraseCount, xPhraseSize, xQueryToken
Une requête FTS5 contient une ou plusieurs phrases. Les API xPhraseCount, xPhraseSize et xQueryToken permettent à une implémentation de fonction auxiliaire d'interroger le système pour obtenir des détails sur la requête actuelle. L'API xPhraseCount renvoie le nombre de phrases dans la requête actuelle. Par exemple, si une table FTS5 est interrogée comme suit :
SELECT ma_fonction_auxiliaire(ft) FROM ft('ab ET "cd ef gh" OU ij + kl')Et que l'API xPhraseCount() est invoquée dans l'implémentation de la fonction auxiliaire, elle renvoie 3 (les trois phrases étant "ab", "cd ef gh" et "ij kl").
Les phrases sont numérotées dans l'ordre d'apparition dans une requête, en commençant par 0. L'API xPhraseSize() peut être utilisée pour interroger le nombre de jetons dans une phrase spécifiée de la requête. Dans l'exemple ci-dessus, la phrase 0 contient 1 jeton, la phrase 1 contient 3 jetons, et la phrase 2 contient 2.
L'API xQueryToken peut être utilisée pour accéder au texte d'un jeton spécifié dans une phrase donnée de la requête. Les jetons sont numérotés dans leurs phrases de gauche à droite, en commençant par 0. Par exemple, si l'API xQueryToken est utilisée pour demander le jeton 1 de la phrase 2 dans l'exemple ci-dessus, elle renvoie le texte "kl". Le jeton 0 de la phrase 0 est "ab".
Occurrences de Phrases dans la Ligne Actuelle : xPhraseFirst, xPhraseNext
Ces deux fonctions API peuvent être utilisées pour itérer...
Analyse des Correspondances de Phrases dans une Table Virtuelle
Lorsqu’on interroge une table virtuelle, il est possible d’examiner les correspondances pour une phrase spécifique dans la ligne actuelle. Ces correspondances sont déterminées par la colonne et le décalage de jeton au sein de la ligne. Prenons un exemple avec une table suivante :
CREATE VIRTUAL TABLE ft2 USING fts5(x, y); INSERT INTO ft2(rowid, x, y) VALUES (1, 'xxx un deux xxx cinq xxx six', 'sept quatre'), (2, 'cinq quatre quatre xxx six', 'trois quatre cinq six quatre cinq six');Cette table est interrogée avec la requête suivante :
SELECT ma_fonction_auxiliaire(ft2) FROM ft2( '("un deux" OU "trois") ET y:quatre PROCHE(cinq six, 2)' );Dans cette requête, cinq phrases sont présentes : « un deux », « trois », « quatre », « cinq » et »six ». Toutes les lignes de la table correspondent, ce qui entraîne l’appel de la fonction auxiliaire pour chaque ligne.
Pour la première ligne, concernant la phrase 0, « un deux », il y a une seule correspondance à examiner – dans la colonne 0, décalage de jeton 1. Le numéro de colonne est 0 car la correspondance se trouve dans la colonne la plus à gauche. Le décalage de jeton est 1, car il y a un jeton (« xxx ») avant la correspondance de phrase dans la valeur de la colonne. Pour la phrase 1, « trois », aucune correspondance n’est trouvée. La phrase 2, « quatre », a une correspondance dans la colonne 1, décalage de jeton 0. La phrase 3, « cinq », a une correspondance dans la colonne 0, décalage de jeton 4, et la phrase 4, « six », a une correspondance dans la colonne 0, décalage de jeton 6.
Le tableau ci-dessous présente l’ensemble des correspondances pour chaque phrase dans chaque ligne de l’exemple. Chaque correspondance est notée sous la forme (numéro de colonne, décalage de jeton) :
| Ligne | Phrase 0 | Phrase 1 | Phrase 2 | Phrase 3 | Phrase 4 |
|---|---|---|---|---|---|
| 1 | (0, 1) | (1, 1) | (0, 4) | (0, 6) | |
| 2 | (1, 0) | (1, 1), (1, 4) | (1, 2), (1, 5) | (1, 3), (1, 6) |
La deuxième ligne est légèrement plus complexe. Il n’y a pas de correspondances pour la phrase 0. La phrase 1 (« trois ») apparaît une fois, à la colonne 1, décalage de jeton 0. Bien qu’il y ait des occurrences de la phrase 2 (« quatre ») dans la colonne 0, aucune d’elles n’est rapportée par l’API, car la phrase 4 a un filtre de colonne – « y: ». Les correspondances filtrées par des filtres de colonne ne sont pas comptées. De même, bien que les phrases 3 et 4 apparaissent dans la colonne « x » de la ligne 2, elles sont exclues par le filtre PROCHE. Les correspondances filtrées par des filtres PROCHE ne sont pas comptées non plus.
Correspondances de Phrases dans la Ligne Actuelle (2) : xInstCount, xInst
Les API xInstCount et xInst fournissent un accès aux mêmes informations que les xPhraseFirst et xPhraseNext décrites précédemment. La différence réside dans le fait que, au lieu d’itérer à travers les correspondances d’une phrase spécifiée, les API xInstCount/xInst rassemblent toutes les correspondances dans un tableau plat unique, trié par ordre d’apparition dans la ligne actuelle. Les éléments de ce tableau peuvent ensuite être accédés de manière aléatoire.
Chaque élément du tableau se compose de trois valeurs :
- Un numéro de phrase,
- Un numéro de colonne, et
- Un décalage de jeton.
En utilisant les mêmes données et la même requête que pour xPhraseFirst/xPhraseNext ci-dessus, le tableau accessible via xInstCount/xInst se compose des entrées suivantes pour chaque ligne :
| Ligne | Tableau xInstCount/xInst |
|---|---|
| 1 | (0, 0, 1), (3, 0, 4), (4, 0, 6), (2, 1, 1) |
| 2 | (1, 1, 0), (2, 1, 1), (3, 1, 2), (4, 1, 3), (2, 1, 4), (3, 1, 5), (4, 1, 6) |
Chaque entrée du tableau est appelée une correspondance de phrase. Les correspondances de phrases sont numérotées dans l’ordre, en commençant par 0. Ainsi, dans l’exemple ci-dessus, dans la ligne 2, la correspondance de phrase 3 est (4, 1, 3) – la phrase 4 de la requête correspond à la colonne 1, décalage de jeton 3.
Référence de l’API des Fonctions Auxiliaires Personnalisées
struct Fts5ExtensionApi {
int iVersion; /* Actuellement toujours fixé à 3 */
void *(*xUserData)(Fts5Context*);
int (*xColumnCount)(Fts5Context*);
int (*xRowCount)(Fts5Context*, sqlite3_int64 *pnRow);
int (*xColumnTotalSize)(Fts5Context*, int iCol, sqlite3_int64 *pnToken);
int (*xTokenize)(Fts5Context*,
const char *pText, int nText, /* Texte à tokeniser */
void *pCtx, /* Contexte passé à xToken() */
int (*xToken)(void*, int, const char*, int, int, int) /* Callback */
);
int (*xPhraseCount)(Fts5Context*);
int (*xPhraseSize)(Fts5Context*, int iPhrase);
int (*xInstCount)(Fts5Context*, int *pnInst);
int (*xInst)(Fts5Context*, int iIdx, int *piPhrase, int *piCol, int *piOff);
sqlite3_int64 (*xRowid)(Fts5Context*);
int (*xColumnText)(Fts5Context*, int iCol, const char **pz, int *pn);
int (*xColumnSize)(Fts5Context*, int iCol, int *pnToken);
int (*xQueryPhrase)(Fts5Context*, int iPhrase, void *pUserData,
int(*)(const Fts5ExtensionApi*,Fts5Context*,void*)
);
int (*xSetAuxdata)(Fts5Context*, void *pAux, void(*xDelete)(void*));
void *(*xGetAuxdata)(Fts5Context*, int bClear);
int (*xPhraseFirst)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*, int*);
void (*xPhraseNext)(Fts5Context*, Fts5PhraseIter*, int *piCol, int *piOff);
/* À partir de ce point, uniquement pour iVersion>=3 */
int (*xQueryToken)(Fts5Context*,
int iPhrase, int iToken,
const char **ppToken, int *pnToken
);
int (*xInstToken)(Fts5Context*, int iIdx,
Comprendre les Fonctions de l’API FTS5
Introduction à FTS5
FTS5, ou Full-Text Search version 5, est une extension de SQLite qui permet d’effectuer des recherches textuelles avancées. Cette API offre une variété de fonctions pour interagir avec les données textuelles, facilitant ainsi la gestion et l’analyse des informations.
Récupération des Données Utilisateur
xUserData
La fonction xUserData permet de récupérer une copie du pointeur pUserData qui a été fourni lors de l’enregistrement de la fonction d’extension via l’API xCreateFunction(). Cela permet aux développeurs d’accéder à des données spécifiques à l’utilisateur tout au long de l’exécution de la fonction.
Analyse des Colonnes
xColumnTotalSize
La fonction xColumnTotalSize est utilisée pour obtenir la taille totale des tokens dans une colonne spécifique d’une table FTS5. Si le paramètre iCol est inférieur à zéro, la fonction renvoie le nombre total de tokens dans l’ensemble de la table. En revanche, si iCol est valide mais dépasse le nombre de colonnes, un code d’erreur SQLITE_RANGE est retourné.
xColumnCount
Avec xColumnCount, il est possible de déterminer le nombre total de colonnes présentes dans la table. Cette information est essentielle pour naviguer dans les données de manière efficace.
xColumnSize
La fonction xColumnSize permet de connaître le nombre de tokens dans une colonne spécifique pour la ligne actuelle. Si iCol est valide, elle renvoie le nombre de tokens dans cette colonne. En cas d’erreur, un code d’erreur approprié est retourné.
xColumnText
Pour récupérer le texte d’une colonne donnée, xColumnText est utilisée. Si le paramètre iCol est valide, la fonction renvoie le texte de la colonne sous forme de chaîne UTF-8, ainsi que la taille de cette chaîne. En cas d’erreur, des codes d’erreur SQLite sont fournis.
Gestion des Phrases
xPhraseCount
La fonction xPhraseCount retourne le nombre de phrases présentes dans l’expression de requête actuelle. Cela permet de mieux comprendre la structure de la requête en cours.
xPhraseSize
Avec xPhraseSize, il est possible de connaître le nombre de tokens dans une phrase spécifique de la requête. Les phrases sont numérotées à partir de zéro, et cette fonction renvoie le nombre de tokens pour la phrase demandée.
Détails des Occurrences
xInstCount
La fonction xInstCount permet de compter le nombre total d’occurrences de toutes les phrases dans la ligne actuelle. Elle peut être lente si utilisée avec des tables FTS5 créées avec des options de détail limitées.
xInst
Pour obtenir des détails sur une correspondance de phrase spécifique, xInst est utilisée. Elle fournit des informations sur le numéro de la phrase, la colonne dans laquelle elle se trouve, et l’offset du premier token. En cas d’erreur, un code d’erreur est retourné.
Identification des Lignes
xRowid
La fonction xRowid renvoie l’identifiant de la ligne actuelle, ce qui est crucial pour le suivi des données dans les opérations de recherche.
Tokenisation du Texte
xTokenize
La fonction xTokenize permet de diviser un texte en tokens en utilisant le tokenizer associé à la table FTS5. Cela est particulièrement utile pour préparer des données textuelles pour des recherches ultérieures.
Requêtes de Phrases
xQueryPhrase
La fonction xQueryPhrase est utilisée pour interroger la table FTS pour une phrase spécifique de la requête actuelle. Elle exécute une requête qui correspond à la phrase demandée et invoque une fonction de rappel pour chaque ligne visitée, permettant ainsi d’accéder aux propriétés de chaque ligne correspondante.
Conclusion
L’API FTS5 de SQLite offre une multitude de fonctions pour gérer efficacement les recherches textuelles. En comprenant et en utilisant ces fonctions, les développeurs peuvent améliorer la performance et la précision des recherches dans leurs applications.
Gestion des Fonctions d’Extension FTS5 dans SQLite
Introduction aux Fonctions d’Extension
Les fonctions d’extension FTS5 dans SQLite permettent d’effectuer des recherches textuelles avancées. Ces fonctions sont essentielles pour gérer les données textuelles de manière efficace, en offrant des outils pour interroger et manipuler les résultats de recherche.
Retour des Codes d’Erreur
Lorsqu’une fonction de rappel renvoie une valeur autre que SQLITE_OK, la requête est interrompue et la fonction xQueryPhrase se termine immédiatement. Si la valeur retournée est SQLITE_DONE, alors xQueryPhrase renvoie SQLITE_OK. Dans tous les autres cas, le code d’erreur est transmis à l’appelant.
Si la requête s’exécute sans problème, SQLITE_OK est renvoyé. En revanche, si une erreur survient avant la fin de la requête ou si elle est annulée par la fonction de rappel, un code d’erreur SQLite est retourné.
Gestion des Données Auxiliaires
Fonction xSetAuxdata
La fonction xSetAuxdata permet de sauvegarder un pointeur comme « données auxiliaires » de la fonction d’extension. Ce pointeur peut être récupéré lors de l’invocation actuelle ou future de la même fonction d’extension FTS5 dans le cadre de la même requête MATCH via l’API xGetAuxdata().
Chaque fonction d’extension dispose d’un emplacement unique pour les données auxiliaires par requête FTS. Si la fonction est appelée plusieurs fois pour une même requête, toutes les invocations partageront le même contexte de données auxiliaires.
Si un pointeur de données auxiliaires existe déjà lors de l’appel de cette fonction, il sera remplacé par le nouveau pointeur. Si un rappel xDelete a été spécifié avec le pointeur original, il sera exécuté à ce moment-là.
En cas d’erreur, comme une condition de mémoire insuffisante, les données auxiliaires sont définies sur NULL et un code d’erreur est renvoyé. Si le paramètre xDelete n’est pas NULL, il est également appelé sur le pointeur de données auxiliaires avant le retour.
Fonction xGetAuxdata
La fonction xGetAuxdata retourne le pointeur de données auxiliaires actuel pour la fonction d’extension FTS5. Si l’argument bClear est non nul, les données auxiliaires sont effacées avant le retour de cette fonction, sans invoquer le xDelete.
Comptage des Lignes
Fonction xRowCount
Cette fonction permet d’obtenir le nombre total de lignes dans la table, équivalent à la requête suivante :
SELECT count(*) FROM ftstable;
Itération sur les Phrases
Fonction xPhraseFirst
La fonction xPhraseFirst, en conjonction avec la structure Fts5PhraseIter et la méthode xPhraseNext, permet d’itérer à travers toutes les occurrences d’une phrase de requête dans la ligne actuelle. Bien que les API xInstCount/xInst soient plus pratiques, cette API peut offrir de meilleures performances dans certaines situations.
Fts5PhraseIter iter;
int iCol, iOff;
for(pApi->xPhraseFirst(pFts, iPhrase, &iter, &iCol, &iOff);
iCol >= 0;
pApi->xPhraseNext(pFts, &iter, &iCol, &iOff)
){
// Une occurrence de la phrase iPhrase à l'offset iOff de la colonne iCol
}
Il est important de ne pas modifier directement la structure Fts5PhraseIter. Elle doit être utilisée uniquement avec les méthodes xPhraseFirst() et xPhraseNext().
Cette API peut être lente si elle est utilisée avec une table FTS5 créée avec les options « detail=none » ou « detail=column ». Dans ces cas, elle itère toujours à travers un ensemble vide.
Fonction xPhraseNext
Pour plus de détails, référez-vous à la fonction xPhraseFirst ci-dessus.
Fonction xPhraseFirstColumn
Cette fonction, ainsi que xPhraseNextColumn(), permet d’itérer à travers les colonnes de la ligne actuelle contenant une ou plusieurs occurrences d’une phrase spécifiée. Par exemple :
Fts5PhraseIter iter;
int iCol;
for(pApi->xPhraseFirstColumn(pFts, iPhrase, &iter, &iCol);
iCol >= 0;
pApi->xPhraseNextColumn(pFts, &iter, &iCol)
){
// La colonne iCol contient au moins une occurrence de la phrase iPhrase
}
Cette API peut également être lente si elle est utilisée avec une table FTS5 créée avec l’option « detail=none ». Dans ce cas, elle itère toujours à travers un ensemble vide.
Les informations accessibles via cette API peuvent également être obtenues par les méthodes xPhraseFirst/xPhraseNext, mais l’avantage principal de cette API est son efficacité accrue lorsqu’elle est utilisée avec des tables « detail=column ».
Fonction xPhraseNextColumn
Pour plus de détails, référez-vous à la fonction xPhraseFirstColumn ci-dessus.
Accès aux Tokens de Phrases
Fonction xQueryToken
Cette fonction est utilisée pour accéder au token iToken de la phrase iPhrase, permettant ainsi une manipulation plus fine des données textuelles.
8. Module de Table Virtuelle fts5vocab
Le module de table virtuelle fts5vocab permet aux utilisateurs d’extraire des informations directement d’un index de texte intégral FTS5. Ce module fait partie intégrante de FTS5 et est disponible chaque fois que FTS5 l’est.
Chaque table fts5vocab est liée à une seule table FTS5. Pour créer une table fts5vocab, il suffit de spécifier deux arguments à la place des noms de colonnes dans l’instruction CREATE VIRTUAL TABLE : le nom de la table FTS5 associée et le type de table fts5vocab. Actuellement, il existe trois types de tables fts5vocab : « row », « col » et « instance ». À moins que la table fts5vocab ne soit créée dans la base de données « temp », elle doit faire partie de la même base de données que la table FTS5 associée.
-- Création d'une table fts5vocab de type "row" pour interroger l'index de texte intégral de la table FTS5 "ft1".
CREATE VIRTUAL TABLE ft1_v USING fts5vocab('ft1', 'row');
-- Création d'une table fts5vocab de type "col" pour interroger l'index de texte intégral de la table FTS5 "ft2".
CREATE VIRTUAL TABLE ft2_v USING fts5vocab(ft2, col);
-- Création d'une table fts5vocab de type "instance" pour interroger l'index de texte intégral de la table FTS5 "ft3".
CREATE VIRTUAL TABLE ft3_v USING fts5vocab(ft3, instance);
Si une table fts5vocab est créée dans la base de données temp, elle peut être associée à une table FTS5 dans n’importe quelle base de données attachée. Pour attacher la table fts5vocab à une table FTS5 située dans une base de données autre que « temp », il faut insérer le nom de la base de données avant le nom de la table FTS5 dans les arguments de CREATE VIRTUAL TABLE. Par exemple :
-- Création d'une table fts5vocab de type "row" pour interroger l'index de texte intégral de la table FTS5 "ft1" dans la base de données "main".
CREATE VIRTUAL TABLE temp.ft1_v USING fts5vocab(main, 'ft1', 'row');
-- Création d'une table fts5vocab de type "col" pour interroger l'index de texte intégral de la table FTS5 "ft2" dans la base de données attachée "aux".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft2, col);
-- Création d'une table fts5vocab de type "instance" pour interroger l'index de texte intégral de la table FTS5 "ft3" dans la base de données attachée "autre".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft3, 'instance');
La spécification de trois arguments lors de la création d’une table fts5vocab dans une base de données autre que « temp » entraîne une erreur.
Une table fts5vocab de type « row » contient une ligne pour chaque terme distinct dans la table FTS5 associée. Les colonnes de la table sont les suivantes :
| Colonne | Contenu |
|---|---|
| terme | Le terme, tel qu’il est stocké dans l’index FTS5. |
| doc | Le nombre de lignes contenant au moins une instance du terme. |
| cnt | Le nombre total d’instances du terme dans l’ensemble de la table FTS5. |
Une table fts5vocab de type « col » contient une ligne pour chaque combinaison terme/colonne distincte dans la table FTS5 associée. Les colonnes de la table sont les suivantes :
| Colonne | Contenu |
|---|---|
| terme | Le terme, tel qu’il est stocké dans l’index FTS5. |
| col | Le nom de la colonne de la table FTS5 contenant le terme. |
| doc | Le nombre de lignes dans la table FTS5 pour lesquelles la colonne $col contient au moins une instance du terme. |
| cnt | Le nombre total d’instances du terme apparaissant dans la colonne $col de la table FTS5 (en tenant compte de toutes les lignes). |
Une table fts5vocab de type « instance » contient une ligne pour chaque instance de terme stockée dans l’index FTS associé. En supposant que la table FTS5 soit créée avec l’option ‘detail’ définie sur ‘full’, les colonnes de la table sont les suivantes :
| Colonne | Contenu |
|---|---|
| terme | Le terme, tel qu’il est stocké dans l’index FTS5. |
| doc | Le rowid du document contenant l’instance de terme. |
| col | Le nom de la colonne contenant l’instance de terme. |
| offset | L’index de l’instance de terme dans sa colonne. |
Lorsqu’une table FTS5 est créée avec l’option ‘detail’ définie sur ‘col’, la colonne offset d’une table virtuelle d’instance contient toujours NULL. Dans ce cas, il y a une ligne dans la table pour chaque combinaison unique de terme/doc/col. En revanche, si la table FTS5 est créée avec ‘detail’ réglé sur ‘none’, alors les colonnes offset et col contiennent également des valeurs NULL. Pour les tables FTS5 avec detail=none, il existe une ligne dans la table fts5vocab pour chaque combinaison unique de terme/doc.
Illustration :
-- Supposons une base de données créée avec :
CREATE VIRTUAL TABLE ft1 USING fts5(c1, c2);
INSERT INTO ft1 VALUES('pomme banane cerise', 'banane banane cerise');
INSERT INTO ft1 VALUES('cerise cerise cerise', 'date date date');
-- Ensuite, interroger la table fts5vocab (type "col") renvoie :
--
-- pomme | c1 | 1 | 1
-- banane | c1 | 1 | 1
-- banane | c2 | 1 | 2
-- cerise | c1 | 2 | 4
-- cerise | c2 | 1 | 1
-- date | c3 | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_col USING fts5vocab(ft1, col);
-- Interroger une table fts5vocab de type "row" renvoie :
--
-- pomme | 1 | 1
-- banane | 1 | 3
-- cerise | 2 | 5
-- date | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_row USING fts5vocab(ft1, row);
-- Et, pour le type "instance"
INSERT INTO ft1 VALUES('pomme banane cerise', 'banane banane cerise');
INSERT INTO ft1 VALUES('cerise cerise cerise', 'date date date');
--
-- pomme | 1 | c1 | 0
-- banane | 1 | c1 | 1
-- banane | 1 | c2 | 0
-- banane | 1 | c2 | 1
-- cerise | 1 | c1 | 2
-- cerise | 1 | c2 | 2
-- cerise | 2 | c1 | 0
-- cerise | 2 | c1 | 1
-- cerise | 2 | c1 | 2
-- date | 2 | c2 | 0
-- date | 2 | c2 | 1
-- date | 2 | c2 | 2
--
CREATE VIRTUAL TABLE ft1_v_instance USING fts5vocab(ft1, instance);
9. Structures de Données FTS5
Cette section présente de manière générale comment le module FTS stocke ses index et son contenu dans la base de données. Bien qu’il ne soit pas nécessaire de lire ou de comprendre ce contenu pour utiliser FTS dans une application, cela peut s’avérer utile pour les développeurs d’applications cherchant à analyser et à comprendre les caractéristiques de performance de FTS, ou pour ceux envisageant des améliorations des fonctionnalités FTS existantes.
Lorsqu’une table virtuelle FTS5 est créée dans une base de données, entre 3 et 5 tables réelles sont générées. Ces tables sont appelées »tables ombres » et sont utilisées par le module de table virtuelle pour stocker des données persistantes. Elles ne doivent pas être accessibles directement par l’utilisateur. De nombreux autres modules de tables virtuelles, y compris FTS3 et rtree, créent également et utilisent des tables ombres.
FTS5 crée les tables ombres suivantes. Dans chaque cas, le nom de la table réelle est basé sur le nom de la table virtuelle FTS5 (dans ce qui suit, remplacez % par le nom de la table virtuelle pour trouver le nom de la table ombre réelle).
-- Cette table contient la majorité des données de l'index de texte intégral. CREATE TABLE %_data(id INTEGER PRIMARY KEY, block BLOB); -- Cette table contient le reste des données de l'index de texte intégral. -- Elle est presque toujours beaucoup plus petite que la table %_data. CREATE TABLE %_idx(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID; -- Contient les valeurs des paramètres de configuration persistants. CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID; -- Contient la taille de chaque colonne de chaque ligne dans la table virtuelle -- en tokens. Cette table ombre n'est pas présente si l'option "columnsize" -- est définie sur 0. CREATE TABLE %_docsize(id INTEGER PRIMARY KEY, sz BLOB); -- Contient les données réelles insérées dans la table FTS5. Il -- y a une colonne "cN" pour chaque colonne indexée dans la table FTS5. -- Cette table ombre n'est pas présente pour les tables FTS5 sans contenu ou de contenu externe. CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
Les sections suivantes décrivent plus en détail comment ces cinq tables sont utilisées pour stocker les données FTS5.
9.1. Format Varint
Les sections ci-dessous font référence à des entiers signés de 64 bits stockés sous forme de « varint ». FTS5 utilise le même format varint que celui utilisé à divers endroits par le cœur de SQLite.
Un varint a une longueur comprise entre 1 et 9 octets. Le varint se compose soit de zéro ou plusieurs octets dont le bit de poids fort est défini, suivi d’un seul octet dont le bit de poids fort est clair, soit de neuf octets, selon ce qui est le plus court. Les sept bits inférieurs de chacun des huit premiers octets et tous les 8 bits du neuvième octet sont utilisés pour reconstruire l’entier en complément à deux de 64 bits. Les varints sont en big-endian : les bits provenant de l’octet précédent du varint sont plus significatifs que ceux provenant des octets suivants.
9.2. L’Index FTS (%_idx et %_data)
L’index FTS est un magasin de clés-valeurs ordonné où les clés sont des termes de document ou des préfixes de termes, et les valeurs associées sont des »listes de documents ». Une liste de documents est un tableau compact de varints qui encode la position de chaque instance du terme dans la table FTS5. La position d’une instance de terme unique est définie par la combinaison de :
- L’identifiant de la ligne de la table FTS5 dans laquelle elle apparaît,
- L’index de la colonne dans laquelle l’instance de terme apparaît (les colonnes sont numérotées de gauche à droite à partir de zéro), et
- L’offset du terme dans la valeur de la colonne (c’est-à-dire le nombre de tokens qui apparaissent dans la valeur de la colonne avant celui-ci).
L’index FTS contient jusqu’à (nPrefix+1) entrées pour chaque token dans l’ensemble de données, où nPrefix est le nombre d’index de préfixes définis.
Les clés associées à l’index principal FTS (celui qui n’est pas un index de préfixe) sont préfixées par le caractère « 0 ». Les clés pour le premier index de préfixe sont préfixées par « 1 ». Les clés pour le deuxième index de préfixe sont préfixées par « 2 », et ainsi de suite. Par exemple, si le token « document » est inséré dans une table FTS5 avec des index de préfixe spécifiés par prefix= »2 4″, alors les clés ajoutées à l’index FTS seraient « 0document », « 1do ».
Les entrées de l’index FTS ne sont pas conservées dans une structure unique de type arbre ou table de hachage. Au lieu de cela, elles sont organisées dans une série de structures immuables de type arbre B, appelées « arbres B de segment ». Chaque fois qu’une écriture dans la table FTS5 est validée, un ou plusieurs (mais généralement un seul) nouveaux arbres B de segment sont ajoutés, contenant à la fois les nouvelles entrées et des tombstones pour les entrées supprimées. Lorsqu’une requête est effectuée sur l’index FTS, le lecteur interroge chaque arbre B de segment à tour de rôle et fusionne les résultats, en donnant la priorité aux données les plus récentes.
Chaque arbre B de segment se voit attribuer un niveau numérique. Lorsqu’un nouvel arbre B de segment est écrit dans la base de données dans le cadre de la validation d’une transaction, il est affecté au niveau 0. Les arbres B de segment appartenant à un même niveau sont périodiquement fusionnés pour créer un arbre B de segment plus grand, qui est assigné au niveau suivant (c’est-à-dire que les arbres B de segment de niveau 0 sont fusionnés pour devenir un seul arbre B de segment de niveau 1). Ainsi, les niveaux numériquement plus élevés contiennent des données plus anciennes dans des arbres B de segment généralement plus grands. Pour plus de détails sur la gestion de la fusion, consultez les options ‘automerge’, ‘crisismerge’ et ‘usermerge’, ainsi que les commandes ‘merge’ et ‘optimize’.
Dans les cas où la liste de documents associée à un terme ou à un préfixe de terme est très volumineuse, un index de liste de documents peut être associé. Cet index est similaire à l’ensemble des nœuds internes d’un arbre B. Il permet d’interroger efficacement une grande liste de documents pour obtenir des identifiants de lignes ou des plages d’identifiants de lignes. Par exemple, lors du traitement d’une requête telle que :
SELECT ... FROM fts_table('terme') WHERE rowid BETWEEN ? AND ?
FTS5 utilise l’index de l’arbre B de segment pour localiser la liste de documents pour le terme « terme », puis utilise son index de liste de documents (s’il est présent) pour identifier efficacement le sous-ensemble de correspondances avec les identifiants de lignes dans la plage requise.
9.2.1. Espace Rowid de la Table %_data
CREATE TABLE %_data( id INTEGER PRIMARY KEY, block BLOB );
La table %_data est utilisée pour stocker trois types d’enregistrements :
- L’enregistrement de structure spécial, stocké avec id=10.
- L’enregistrement des moyennes spécial, stocké avec id=1.
- Un enregistrement pour stocker chaque feuille d’arbre B de segment, ainsi que les feuilles et nœuds internes de l’index de liste de documents. Consultez ci-dessous pour savoir comment les valeurs d’id sont calculées pour ces enregistrements.
Chaque arbre B de segment dans le système se voit attribuer un identifiant de segment unique de 16 bits. Les identifiants de segment ne peuvent être réutilisés qu’après que l’arbre B de segment d’origine a été complètement fusionné dans un arbre B de segment de niveau supérieur. Au sein d’un arbre B de segment, chaque page feuille se voit attribuer un numéro de page unique – 1 pour la première page feuille, 2 pour la deuxième, et ainsi de suite.
Chaque page feuille de l’index de liste de documents se voit également attribuer un numéro de page. La première page feuille (la plus à gauche) dans un index de liste de documents reçoit le même numéro de page que la page feuille de l’arbre B de segment sur laquelle son terme apparaît (car les index de liste de documents ne sont créés que pour les termes ayant des listes de documents très longues, au maximum un terme par page feuille d’arbre B de segment). Appelons ce numéro de page P. Si la liste de documents est si volumineuse qu’elle nécessite une seconde feuille, la seconde feuille se voit attribuer le numéro de page P+1. La troisième feuille P+2. Chaque niveau d’un arbre B d’index de liste de documents (feuilles, parents de feuilles, grands-parents, etc.) se voit attribuer des numéros de page de cette manière, en commençant par le numéro de page P.
La valeur « id » utilisée dans la table %_data pour stocker une feuille d’arbre B de segment ou une feuille ou un nœud de l’index de liste de documents est composée comme suit :
| Bits Rowid | Contenu |
|---|---|
| 38..43 | (16 bits) Valeur d’identifiant de l’arbre B de segment. |
| 37 | (1 bit) Drapeau d’index de liste de documents. Défini pour les pages d’index de liste de documents, clair pour les feuilles d’arbre B de segment. |
| 32..36 | (5 bits) Hauteur dans l’arbre. Cela est défini à 0 pour les feuilles d’arbre B de segment et d’index de liste de documents, à 1 pour les parents des feuilles d’index de liste de documents, 2 pour les grands-parents, etc. |
| 0..31 | (32 bits) Numéro de page |
9.2.2. Format de l’Enregistrement de Structure
L’enregistrement de structure identifie l’ensemble des arbres B de segment qui composent l’index FTS actuel, ainsi que les détails de toute opération de fusion incrémentale en cours. Il est stocké dans la table %_data avec id=10.
Un enregistrement de structure commence par une seule valeur non signée de 32 bits - la valeur de cookie. Cette valeur est incrémentée chaque fois que la structure est modifiée. Après la valeur de cookie, trois valeurs varint suivent, comme suit :
- Le nombre de niveaux dans l’index (c’est-à-dire le niveau maximum associé à un arbre B de segment plus un).
- Le nombre total d’arbres B de segment dans l’index.
- Le nombre total de feuilles d’arbres B de segment écrites dans les arbres de niveau 0 depuis la création de la table FTS5.
Ensuite, pour chaque niveau de 0 à nLevel :
- Le nombre de segments d’entrée du niveau précédent utilisés comme entrées pour la fusion incrémentale actuelle, ou zéro s’il n’y a pas de fusion incrémentale en cours pour créer un nouvel arbre B de segment pour ce niveau.
- Le nombre total d’arbres B de segment à ce niveau.
- Ensuite, pour chaque arbre B de segment, du plus ancien au plus récent :
- L’identifiant de segment.
- Numéro de page de la première feuille (souvent 1, toujours >0).
- Numéro de page de la dernière feuille (toujours >0).
9.2.3. Format de l’Enregistrement des Moyennes
L’enregistrement des moyennes, qui est toujours stocké avec id=1 dans la table %_data, ne stocke pas la moyenne de quoi que ce soit. Au lieu de cela, il contient un vecteur de (nCol+1) valeurs varint compactées, où nCol est le nombre de colonnes dans la table FTS5, y compris les colonnes non indexées. La première valeur varint contient le nombre total de lignes dans la table FTS5. La seconde contient le nombre total de tokens dans toutes les valeurs stockées dans la colonne la plus à gauche de la table FTS5. La troisième contient le nombre de tokens dans toutes les valeurs pour la colonne suivante la plus à gauche, et ainsi de suite. La valeur pour les colonnes non indexées est toujours zéro.
9.2.4. Format de l’Arbre B de Segment
9.2.4.1. Format Clé/Liste de Documents
Le format clé/liste de documents est utilisé pour stocker une série de clés (termes de documents ou préfixes de termes précédés d’un caractère unique pour identifier l’index spécifique auquel ils appartiennent).
Structure des Clés et des Doclists dans FTS5
Format de Stockage des Clés
Les clés sont organisées dans un ordre trié, chacune étant associée à une liste de documents (doclist). Le format de stockage alterne entre les clés et les doclists.
Stockage de la Première Clé
La première clé est enregistrée sous la forme suivante :
- Un varint qui indique le nombre d’octets dans la clé (N), suivi de
- Les données de la clé elle-même (N octets).
Stockage des Clés Suivantes
Chaque clé suivante est stockée comme suit :
- Un varint qui indique la taille du préfixe commun avec la clé précédente en octets,
- Un varint qui indique le nombre d’octets dans la clé après le préfixe commun (N), suivi de
- Les données du suffixe de la clé (N octets).
Exemple de Stockage des Clés
Prenons un exemple : si les deux premières clés dans un enregistrement de clé/doclist FTS5 sont « 0challenger » et « 0chandelier », la première clé est stockée comme un varint de 11, suivi des 11 octets « 0challenger ». La seconde clé est alors enregistrée avec des varints de 4 et 7, suivis des 7 octets « ndelier ».
Compréhension des Doclists
Chaque doclist identifie les lignes (par leurs valeurs de rowid) qui contiennent au moins une instance du terme ou du préfixe de terme, accompagnée d’une liste de positions, ou « poslist », qui énumère la position de chaque instance de terme dans la ligne. Dans ce contexte, une « position » est définie comme un numéro de colonne et un décalage de terme au sein de la valeur de la colonne.
Organisation des Documents dans un Doclist
Dans un doclist, les documents sont toujours stockés dans un ordre trié par rowid. Le premier rowid dans un doclist est enregistré tel quel, sous forme de varint. Il est immédiatement suivi de sa liste de positions associée. Ensuite, la différence entre le premier rowid et le second est stockée sous forme de varint, suivie du doclist associé au second rowid, et ainsi de suite.
Limitations de la Détermination de la Taille d’un Doclist
Il n’est pas possible de déterminer la taille d’un doclist simplement en l’analysant. Cette information doit être stockée séparément. Pour plus de détails sur la manière dont cela est réalisé dans FTS5, veuillez consulter la section suivante.
Illustration du Format Term/Doclist
Cette figure illustre la structure des clés et des doclists, mettant en évidence les différentes parties du format de stockage.
Conclusion
La compréhension de la structure des clés et des doclists dans FTS5 est essentielle pour optimiser les performances de recherche et de récupération des données. En maîtrisant ce format, les développeurs peuvent améliorer l’efficacité de leurs applications de gestion de données.
Comprendre le Format de la Liste de Positions
Qu’est-ce qu’une Liste de Positions ?
Une liste de positions, souvent abrégée en « poslist », est un élément essentiel dans le traitement des données textuelles. Elle permet d’identifier la colonne et l’offset du token dans chaque ligne où ce token apparaît. Le format d’une liste de positions est structuré de la manière suivante :
Structure d’une Liste de Positions
-
Varint Initial : Ce champ représente le double de la taille de la liste de positions, sans inclure ce champ lui-même. Si le drapeau « supprimer » est activé pour l’entrée, on ajoute un à ce nombre.
-
Liste d’Offsets pour la Colonne 0 : Cette liste, qui peut être vide, contient les offsets pour la première colonne (colonne 0) de la ligne. Chaque offset est stocké sous forme de varint. Le premier varint indique la valeur du premier offset, augmentée de 2. Le second varint représente la différence entre le deuxième et le premier offset, également augmentée de 2. Par exemple, si la liste d’offsets contient les valeurs 0, 10, 15 et 16, elle sera encodée comme suit :
2, 12, 7, 3 -
Colonnes Supplémentaires : Pour chaque colonne, autre que la colonne 0, qui contient une ou plusieurs instances du token, les éléments suivants sont inclus :
- Un octet avec la valeur 0x01.
- Le numéro de la colonne, sous forme de varint.
- Une liste d’offsets, formatée de la même manière que celle de la colonne 0.
Illustration du Format de la Liste de Positions
Détails de la Liste d’Offsets
La liste d’offsets pour la colonne 0 est essentielle pour le traitement des données. Elle permet de localiser précisément où chaque instance du token se trouve dans la ligne. Les colonnes supplémentaires suivent un format similaire, ce qui assure une cohérence dans la manière dont les données sont stockées et récupérées.
Importance de la Taille de la Liste de Positions
Si la taille de la liste de positions est suffisamment petite (par défaut, cela signifie moins de 4000 octets), elle peut être traitée de manière efficace. Cela permet d’optimiser les performances lors de l’accès aux données, en garantissant que les informations sont rapidement disponibles pour les requêtes et les analyses.
Conclusion
La compréhension du format de la liste de positions est cruciale pour quiconque travaille avec des bases de données ou des systèmes de gestion de contenu. En maîtrisant cette structure, les développeurs et les analystes peuvent améliorer l’efficacité de leurs systèmes de recherche et de traitement de données.
Le contenu d’un segment d’un arbre b peut être enregistré dans un format clé/liste de documents, comme décrit précédemment, sous la forme d’un seul blob dans la table %_data. Alternativement, la clé/liste de documents peut être divisée en pages (généralement d’environ 4000 octets chacune) et stockée dans un ensemble contigu d’entrées dans la table %_data.
Modifications du Format lors de la Division en Pages
Lorsque la clé/liste de documents est fragmentée en pages, plusieurs ajustements sont apportés au format :
- Un champ de données clé ou varint ne s’étend jamais sur deux pages.
- La première clé de chaque page n’est pas compressée par préfixe. Elle est enregistrée dans le format décrit pour la première clé d’une liste de documents, c’est-à-dire sa taille sous forme de varint suivie des données de la clé.
- Si une ou plusieurs identifications de ligne (rowids) se trouvent sur une page avant la première clé, la première d’entre elles n’est pas compressée par delta. Elle est stockée telle quelle, comme si elle était la première rowid de sa liste de documents (ce qui peut ou non être le cas).
Chaque page comprend également un en-tête fixe de 4 octets et un pied de page de taille variable. L’en-tête est divisé en deux champs d’entiers de 16 bits en big-endian. Ces champs contiennent :
- Le décalage en octets de la première valeur rowid sur la page, si elle se trouve avant la première clé, ou 0 sinon.
- Le décalage en octets du pied de page de la page.
Le pied de page de la page se compose d’une série de varints contenant le décalage en octets de chaque clé apparaissant sur la page. Si aucune clé n’est présente sur la page, le pied de page fait zéro octet.
Format de l’Index de Segment
Le résultat de la mise en forme du contenu de l’arbre b en format clé/liste de documents, puis de sa division en pages, ressemble beaucoup aux feuilles d’un arbre b+. Au lieu de créer un format pour les nœuds internes de cet arbre b+ et de les stocker dans la table %_data aux côtés des feuilles, les clés qui auraient été stockées sur ces nœuds sont ajoutées à la table %_idx, définie comme suit :
CREATE TABLE %_idx(
segid INTEGER, -- identifiant du segment
term TEXT, -- préfixe de la première clé sur la page
pgno INTEGER, -- (2*pgno + bDoclistIndex)
PRIMARY KEY(segid, term)
);Pour chaque page « feuille » contenant au moins une clé, une entrée est ajoutée à la table %_idx. Les champs sont définis comme suit :
| Colonne | Contenu |
|---|---|
| segid | L’identifiant entier du segment. |
| term | Le plus petit préfixe de la première clé sur la page qui est supérieur à toutes les clés de la page précédente. Pour la première page d’un segment, ce préfixe fait zéro octet. |
| pgno | Ce champ encode à la fois le numéro de page (dans le segment – commençant à 1) et le drapeau d’index de liste de documents. Le drapeau d’index de liste de documents est activé si la dernière clé de la page a un index de liste de documents associé. La valeur de ce champ est : |
(pgno*2 + bDoclistIndexFlag)Pour localiser la feuille pour le segment i qui pourrait contenir le terme t, au lieu de rechercher à travers les nœuds internes, FTS5 exécute la requête suivante :
SELECT pgno FROM %_idx WHERE segid=$i AND term>=$t ORDER BY term LIMIT 1Format de l’Index de Liste de Documents
L’index de segment décrit précédemment permet d’interroger efficacement un arbre b par terme ou, en supposant qu’il existe un index de préfixe de la taille requise, un préfixe de terme. La structure de données décrite dans cette section, les index de liste de documents, permet à FTS5 de rechercher efficacement un rowid ou une plage de rowids au sein de la liste de documents associée à un terme ou un préfixe de terme unique.
Il est important de noter que toutes les clés n’ont pas d’index de liste de documents associés. Par défaut, un index de liste de documents n’est ajouté pour une clé que si sa liste de documents s’étend sur plus de 4 pages de feuilles d’arbre b. Les index de liste de documents sont eux-mêmes des arbres b, avec des feuilles et des nœuds internes stockés comme des entrées.
Indexation Documentaire avec FTS5
Dans la table %_data, la plupart des listes de documents sont suffisamment petites pour tenir sur une seule page. FTS5 utilise une taille approximative similaire pour les nœuds d’index de la liste de documents et les feuilles de l’arbre b des segments, avec une taille par défaut de 4000 octets.
Les feuilles et les nœuds internes de l’index de la liste de documents partagent le même format de page. Le premier octet est un octet de »flags ». Il est défini à 0x00 pour la page racine de l’index de la liste de documents et à 0x01 pour toutes les autres pages. Le reste de la page est constitué d’une série de varints étroitement empaquetés, comprenant :
- le numéro de page de la page enfant la plus à gauche, suivi de
- la valeur de rowid la plus petite sur la page enfant la plus à gauche, suivie de
- un varint pour chaque page enfant suivante, contenant la valeur :
- 0x00 s’il n’y a pas de rowids sur la page enfant (ce qui ne peut se produire que lorsque la page « enfant » est en réalité une feuille de l’arbre b des segments), ou
- la différence entre le rowid le plus petit sur la page enfant et la valeur de rowid précédente stockée sur la page d’index de la liste de documents.
Pour la feuille d’index de la liste de documents la plus à gauche, la page enfant la plus à gauche est la première feuille de l’arbre b des segments après celle qui contient la clé elle-même.
Table des Tailles de Documents (%_docsize)
CREATE TABLE %_docsize(
id INTEGER PRIMARY KEY, -- identifiant de la ligne FTS5 à laquelle cet enregistrement se rapporte
sz BLOB -- blob contenant des varints nCol empaquetés
);
De nombreuses fonctions de classement des résultats de recherche nécessitent en entrée la taille en tokens du document résultant (un terme de recherche dans un document court est considéré comme plus significatif que dans un document long). Pour un accès rapide à cette information, chaque ligne de la table FTS5 a un enregistrement correspondant (avec le même rowid) dans la table ombre %_docsize qui contient la taille de chaque valeur de colonne dans la ligne, en tokens.
Les tailles des valeurs de colonne sont stockées dans un blob contenant un varint empaqueté pour chaque colonne de la table FTS5, de gauche à droite. Le varint contient, bien sûr, le nombre total de tokens dans la valeur de colonne correspondante. Les colonnes non indexées sont incluses dans ce vecteur de varints ; pour elles, la valeur est toujours fixée à zéro.
Cette table est utilisée par l’API xColumnSize. Elle peut être complètement omise en spécifiant l’option columnsize=0. Dans ce cas, l’API xColumnSize reste disponible pour les fonctions auxiliaires, mais fonctionne beaucoup plus lentement.
Contenu de la Table (%_content)
CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
Le contenu réel de la table – les valeurs insérées dans la table FTS5, est stocké dans la table %_content. Cette table est créée avec une colonne « c* » pour chaque colonne de la table FTS5, y compris les colonnes non indexées. Les valeurs de la colonne la plus à gauche de la table FTS5 sont stockées dans la colonne « c0 » de la table %_content, les valeurs de la colonne suivante dans « c1 », et ainsi de suite.
Cette table est complètement omise pour les contenus externes ou les tables FTS5 sans contenu.
Options de Configuration (%_config)
CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID;
Cette table stocke les valeurs de toutes les options de configuration persistantes. La colonne « k » contient le nom de l’option (texte) et la colonne « v » la valeur. Exemple de contenu :
sqlite> SELECT * FROM fts_tbl_config; ┌───────────────┬──────┐ │ k │ v │ ├───────────────┼──────┤ │ crisismerge │ 8 │ │ pgsz │ 8000 │ │ usermerge │ 4 │ │ version │ 4 │ └───────────────┴──────┘
Annexe A : Comparaison avec FTS3/4
Le module FTS3/4, plus mature, est également disponible. FTS5 est une nouvelle version de FTS4 qui inclut diverses corrections et solutions à des problèmes qui ne pouvaient pas être résolus dans FTS4 sans compromettre la compatibilité ascendante. Certains de ces problèmes sont décrits ci-dessous.
Guide de Portage des Applications
Pour utiliser FTS5 à la place de FTS3 ou FTS4, les applications nécessitent généralement des modifications minimales. La plupart de ces modifications se répartissent en trois catégories : les changements nécessaires à l’instruction CREATE VIRTUAL TABLE utilisée pour créer la table FTS, les modifications requises pour les requêtes SELECT exécutées contre la table, et les ajustements nécessaires pour les applications utilisant les fonctions auxiliaires FTS.
Modifications aux instructions CREATE VIRTUAL TABLE
-
Le nom du module doit être changé de « fts3 » ou « fts4 » à « fts5 ».
-
Toutes les informations de type ou spécifications de contrainte doivent être supprimées des définitions de colonnes. FTS3/4 ignore tout ce qui suit le nom de la colonne dans une définition de colonne, tandis que FTS5 tente de l’analyser (et signalera une erreur si cela échoue).
-
L’option « matchinfo=fts3 » n’est pas disponible. L’option « columnsize=0 » est équivalente.
-
L’option notindexed= n’est pas disponible. Ajouter UNINDEXED à la définition de la colonne.
Différences Techniques entre FTS5 et ses Prédécesseurs
FTS5, tout comme FTS3 et FTS4, a pour objectif principal de maintenir un index qui associe chaque token unique à une liste d’occurrences de ce token dans un ensemble de documents. Chaque occurrence est identifiée par le document dans lequel elle apparaît ainsi que sa position au sein de ce document. Par exemple :
-- Exemple de SQL : CREATE VIRTUAL TABLE ft USING fts5(a, b); INSERT INTO ft(rowid, a, b) VALUES(1, 'X Y', 'Y Z'); INSERT INTO ft(rowid, a, b) VALUES(2, 'A Z', 'Y Y'); -- Le module FTS5 crée la correspondance suivante sur disque : A --> (2, 0, 0) X --> (1, 0, 0) Y --> (1, 0, 1) (1, 1, 0) (2, 1, 0) (2, 1, 1) Z --> (1, 1, 1) (2, 0, 1)
Dans cet exemple, chaque triplet indique la localisation d’une occurrence de token par son rowid, le numéro de colonne (numéroté de 0 de gauche à droite) et la position au sein de la valeur de la colonne (le premier token d’une valeur de colonne est 0, le second est 1, etc.). Grâce à cet index, FTS5 peut fournir des réponses rapides à des requêtes telles que « l’ensemble de tous les documents contenant le token ’A' » ou « l’ensemble de tous les documents contenant la séquence ‘Y Z' ». La liste des occurrences associées à un token unique est appelée une « liste d’occurrences ».
La principale différence entre FTS3/4 et FTS5 réside dans la manière dont les listes d’occurrences sont stockées. Dans FTS3/4, chaque liste d’occurrences est conservée sous la forme d’un seul enregistrement de base de données volumineux, tandis qu’en FTS5, les grandes listes d’occurrences sont réparties sur plusieurs enregistrements de base de données. Cela a plusieurs implications pour la gestion de grandes bases de données contenant d’importantes listes :
-
FTS5 peut charger les listes d’occurrences en mémoire de manière incrémentielle, ce qui permet de réduire l’utilisation de la mémoire et la taille d’allocation maximale. En revanche, FTS3/4 charge souvent l’intégralité des listes d’occurrences en mémoire.
-
Lors du traitement de requêtes comportant plusieurs tokens, FTS5 peut parfois déterminer que la requête peut être satisfaite en inspectant un sous-ensemble d’une grande liste d’occurrences. FTS3/4 doit presque toujours parcourir l’intégralité des listes d’occurrences.
-
Si une liste d’occurrences devient si volumineuse qu’elle dépasse la limite SQLITE_MAX_LENGTH, FTS3/4 ne peut pas la gérer. FTS5, en revanche, n’est pas confronté à ce problème.
Pour ces raisons, de nombreuses requêtes complexes peuvent nécessiter moins de mémoire et s’exécuter plus rapidement avec FTS5.
Voici d’autres différences notables entre FTS5 et ses prédécesseurs :
-
FTS5 prend en charge « ORDER BY rank » pour retourner les résultats par ordre de pertinence décroissante.
-
FTS5 propose une API permettant aux utilisateurs de créer des fonctions auxiliaires personnalisées pour des applications avancées de classement et de traitement de texte. La colonne spéciale « rank » peut être associée à une fonction auxiliaire personnalisée, ce qui permet à l’ajout de « ORDER BY rank » dans une requête de fonctionner comme prévu.
-
FTS5 reconnaît par défaut les caractères de séparation Unicode et l’équivalence de casse. Cela est également possible avec FTS3/4, mais doit être activé explicitement.
Modifications des Instructions SELECT
-
L’alias « docid » n’existe pas. Les applications doivent utiliser « rowid » à la place.
-
Le comportement des requêtes lorsqu’un filtre de colonne est spécifié à la fois dans la requête FTS et en utilisant une colonne comme LHS d’un opérateur MATCH est légèrement différent. Pour une table avec les colonnes « a » et « b », une requête similaire à :
FTS3/4 recherche des correspondances dans la colonne « b ». Cependant, FTS5 renvoie toujours zéro ligne, car les résultats sont d’abord filtrés pour la colonne « b », puis pour la colonne « a », laissant ainsi aucun résultat. En d’autres termes, dans FTS3/4, le filtre interne remplace l’extérieur, tandis qu’en FTS5, les deux filtres sont appliqués.
-
La syntaxe de la requête FTS (côté droit de l’opérateur MATCH) a changé de certaines manières. La syntaxe FTS5 est assez proche de la « syntaxe améliorée » de FTS4. La principale différence est que FTS5 est plus strict concernant les caractères de ponctuation non reconnus et similaires dans les chaînes de requête. La plupart des requêtes qui fonctionnent avec FTS3/4 devraient également fonctionner avec FTS5, et celles qui ne fonctionnent pas devraient renvoyer des erreurs de parsing.
Modifications des Fonctions Auxiliaires
FTS5 ne dispose pas des fonctions matchinfo() ou offsets(), et la fonction snippet() n’est pas aussi complète que dans FTS3/4. Cependant, FTS5 offre une API permettant aux applications de créer des fonctions auxiliaires personnalisées, ce qui permet d’implémenter toute fonctionnalité requise dans le code de l’application.
Il est possible que l’ensemble des fonctions auxiliaires intégrées fournies par FTS5 soit amélioré à l’avenir.
Autres Problèmes
-
La fonctionnalité fournie par le module fts4aux est désormais assurée par fts5vocab. Le schéma de ces deux tables est légèrement différent.
-
La commande « merge=X,Y » de FTS3/4 a été remplacée par la commande de fusion de FTS5.
-
La commande « automerge=X » de FTS3/4 a été remplacée par l’option automerge de FTS5.
La syntaxe des requêtes a été révisée pour éliminer les ambiguïtés et permettre l’échappement des caractères spéciaux dans les termes de requête.
Par défaut, FTS3/4 fusionne parfois deux ou plusieurs des arbres b qui composent son index de texte intégral lors d’une instruction INSERT, UPDATE ou DELETE exécutée par l’utilisateur. Cela signifie que toute opération sur une table FTS3/4 peut s’avérer étonnamment lente, car FTS3/4 peut choisir de manière imprévisible de fusionner deux ou plusieurs grands arbres b. En revanche, FTS5 utilise par défaut une fusion incrémentielle, ce qui limite la quantité de traitement pouvant avoir lieu lors d’une opération INSERT, UPDATE ou DELETE donnée.








Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Technologie
Ne manquez pas cette offre incroyable : le Air Fryer Moulinex Easy Fry Max à -42% sur Amazon !
Les soldes d’hiver sont là ! Ne ratez pas l’incroyable offre d’Amazon sur le Moulinex Easy Fry Max, à seulement 69 euros au lieu de 119 euros, soit une réduction sensationnelle de -42% ! Avec sa capacité généreuse de 5 L, cette friteuse sans huile est idéale pour régaler jusqu’à 6 convives. Grâce à ses 10 programmes de cuisson et son interface tactile intuitive, préparez des plats sains et savoureux en un clin d’œil. Dépêchez-vous, les stocks s’épuisent vite et cette offre est limitée dans le temps !

Technologie
Les soldes d’hiver sont en cours, et Amazon en profite pour offrir des promotions intéressantes, notamment sur les friteuses à air. Actuellement, le Moulinex Easy Fry Max est proposé à un prix attractif de 69 euros au lieu de 119 euros, ce qui représente une réduction immédiate de 42 %. C’est une occasion parfaite pour acquérir une friteuse sans huile XL d’une capacité généreuse de 5 L, idéale pour préparer des repas pour jusqu’à six personnes à un tarif très compétitif.
Étant donné que cette offre est limitée dans le temps,il est conseillé d’agir rapidement si vous souhaitez en bénéficier. De plus, avec un tel prix, les stocks pourraient s’épuiser rapidement. Ce modèle se classe parmi les meilleures ventes sur Amazon avec plus de 1000 unités écoulées le mois dernier.
Profitez des offres sur Amazon
Amazon propose également la livraison gratuite et rapide pour cet article qui bénéficie d’une garantie de deux ans. En outre, il existe une option de paiement échelonné en quatre fois sans frais sur ce modèle. Enfin, sachez que vous avez la possibilité de changer d’avis et retourner le produit gratuitement dans un délai de 30 jours afin d’obtenir un remboursement intégral.
Moulinex Easy Fry Max : cuisinez sainement pour toute la famille
Le moulinex Easy Fry Max fonctionne comme un four à air chaud permettant la préparation de plats savoureux tout en utilisant peu ou pas du tout d’huile. En plus des frites croustillantes qu’il réalise parfaitement, cet appareil se révèle très polyvalent et peut cuisiner une multitude d’autres recettes.
avec ses dix programmes prédéfinis adaptés à divers ingrédients tels que poulet,steak,poisson ou légumes ainsi que des options pour bacon et desserts comme les pizzas ,cet appareil répond aux besoins variés des familles modernes. De plus, Moulinex met à disposition un livre numérique rempli de recettes accessible via QR Code afin que vous puissiez facilement trouver l’inspiration culinaire lorsque nécessaire.
Sa capacité généreuse permet non seulement la préparation rapide mais aussi économique : jusqu’à 70 % moins énergivore et presque deux fois plus rapide qu’un four traditionnel ! Son interface intuitive avec écran tactile facilite son utilisation quotidienne.
en outre, le panier antiadhésif compatible lave-vaisselle simplifie grandement l’entretien après chaque utilisation. N’oubliez pas qu’il s’agit là encore d’une offre temporaire ; ne tardez donc pas si vous souhaitez profiter du meilleur prix possible sur cette friteuse innovante !
Pour accéder à cette remise exceptionnelle :
Technologie
TikTok revient en force aux États-Unis, mais pas sur l’App Store !
Le suspense autour de TikTok est à son comble ! En avril 2024, le Congrès américain a voté une loi obligeant l’application à changer de propriétaire avant le 19 janvier. Les utilisateurs ont anxieusement attendu la décision finale. Bien que TikTok ait brièvement cessé ses activités, elle est revenue en ligne, mais absente de l’App Store. Apple justifie cette décision par des obligations légales. Cependant, les utilisateurs peuvent toujours accéder à leur compte… sans mises à jour. L’avenir de TikTok pourrait prendre un tournant décisif avec les promesses du nouveau président.

Technologie
En avril 2024, le Congrès américain a adopté une législation obligeant TikTok à trouver un nouvel acquéreur, ByteDance étant accusé d’activités d’espionnage. Les utilisateurs de l’submission aux États-Unis ont donc attendu avec impatience le week-end précédent la date limite du 19 janvier pour savoir si TikTok serait interdit dans le pays.
Bien que TikTok n’ait pas réussi à dénicher un repreneur avant cette échéance, l’application a temporairement suspendu ses activités… mais seulement pour quelques heures. le réseau social est désormais de retour en ligne, mais il n’est plus accessible sur l’App Store.
Retour de TikTok : Une Absence Persistante sur l’App Store
Apple a expliqué sa décision de retirer TikTok de son App store par un communiqué officiel. « Apple doit respecter les lois en vigueur dans les régions où elle opère. Selon la loi Protecting Americans from Foreign Adversary Controlled Applications act, les applications développées par ByteDance ltd., y compris TikTok et ses filiales comme CapCut et Lemon8, ne pourront plus être téléchargées ou mises à jour sur l’App Store pour les utilisateurs américains après le 19 janvier 2025 », précise la société.
Il est crucial de souligner que les utilisateurs américains ayant déjà installé TikTok peuvent toujours accéder au service. Cependant, ils ne recevront plus aucune mise à jour future de l’application. L’avenir du réseau social pourrait dépendre des décisions du nouveau président des États-Unis.
DÉCLARATION DE TIKTOK :
>
En collaboration avec nos partenaires techniques, nous travaillons activement à rétablir notre service. Nous remercions le président Trump pour avoir clarifié la situation et rassuré nos partenaires qu’ils ne subiront aucune sanction en continuant d’offrir TikTok aux plus de 170 millions d’utilisateurs…
Le successeur de Joe Biden sera investi comme président ce lundi 20 janvier et prévoit d’émettre un décret afin d’accorder un délai supplémentaire à TikTok pour trouver un acquéreur potentiel.Donald Trump propose même que les États-Unis détiennent une participation significative dans cette application.
« Je souhaite que les États-Unis possèdent une part importante dans une coentreprise avec cet outil numérique afin que nous puissions préserver son intégrité tout en lui permettant d’évoluer […]. Ainsi,notre pays détiendrait la moitié des parts dans une coentreprise établie entre nous et tout acheteur sélectionné »,a déclaré Donald Trump.
L’avenir immédiat de TikTok pourrait donc connaître des évolutions majeures très prochainement. Il convient également de noter qu’une rumeur circulait selon laquelle Elon Musk envisagerait d’acquérir des parts dans la plateforme,mais celle-ci a été rapidement démentie par un porte-parole officiel.
-
 Business2 ans ago
Business2 ans agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoDes Projets Ambitieux qui Pourraient Redéfinir la Géopolitique