Technologie
À l’abri des tendances : Découvrez pourquoi nous privilégions les VMs isolées
Would your rather observe an eclipse through a pair of new Ray-Bans, or a used Shade 12 welding helmet? Undoubtably the Aviators are more fashionable, but the permanent retinal damage sucks. Fetch the trusty welding helmet. We’ve made a number of security choices when building Canary that have held us in pretty good stead. These

Préféreriez-vous observer une éclipse avec une paire de nouvelles lunettes Ray-Ban ou un ancien casque de soudure Shade 12 ? Sans aucun doute, les lunettes Aviator sont plus élégantes, mais les dommages rétiniens permanents ne sont pas à prendre à la légère. Optez plutôt pour le casque de soudure fiable.
Lors de la conception de Canary, nous avons pris plusieurs décisions en matière de sécurité qui se sont révélées bénéfiques. Ces choix sont intéressants car ils ne nécessitent pas l’achat de produits de sécurité, ne sont pas souvent discutés dans les forums d’ingénierie de la sécurité, et peuvent sembler peu attrayants. Une décision architecturale peu glamour a fait ses preuves : l’isolement complet des clients.
Contexte
Canary repose fondamentalement sur deux éléments : les dispositifs Canary (matériels ou virtuels) déployés dans l’infrastructure des clients, et la Console (que nous gérons) à laquelle ces Canaries rapportent. De manière générale, cela ressemble à la plupart des produits ou appareils gérés dans le cloud : les appareils envoient des données de télémétrie vers le cloud. Il est courant que les dispositifs gérés dans le cloud rapportent à un unique point de terminaison (par exemple, un service HTTPS), ou peut-être à un point de terminaison spécifique à une région. Dans ces produits, les dispositifs sont gérés via un site web partagé par plusieurs clients, ce qui présente de nombreux avantages opérationnels et économiques, et constitue un choix naturel.
Cependant, nous avons choisi une autre voie. Chaque client de Canary dispose de son propre espace, la Console.
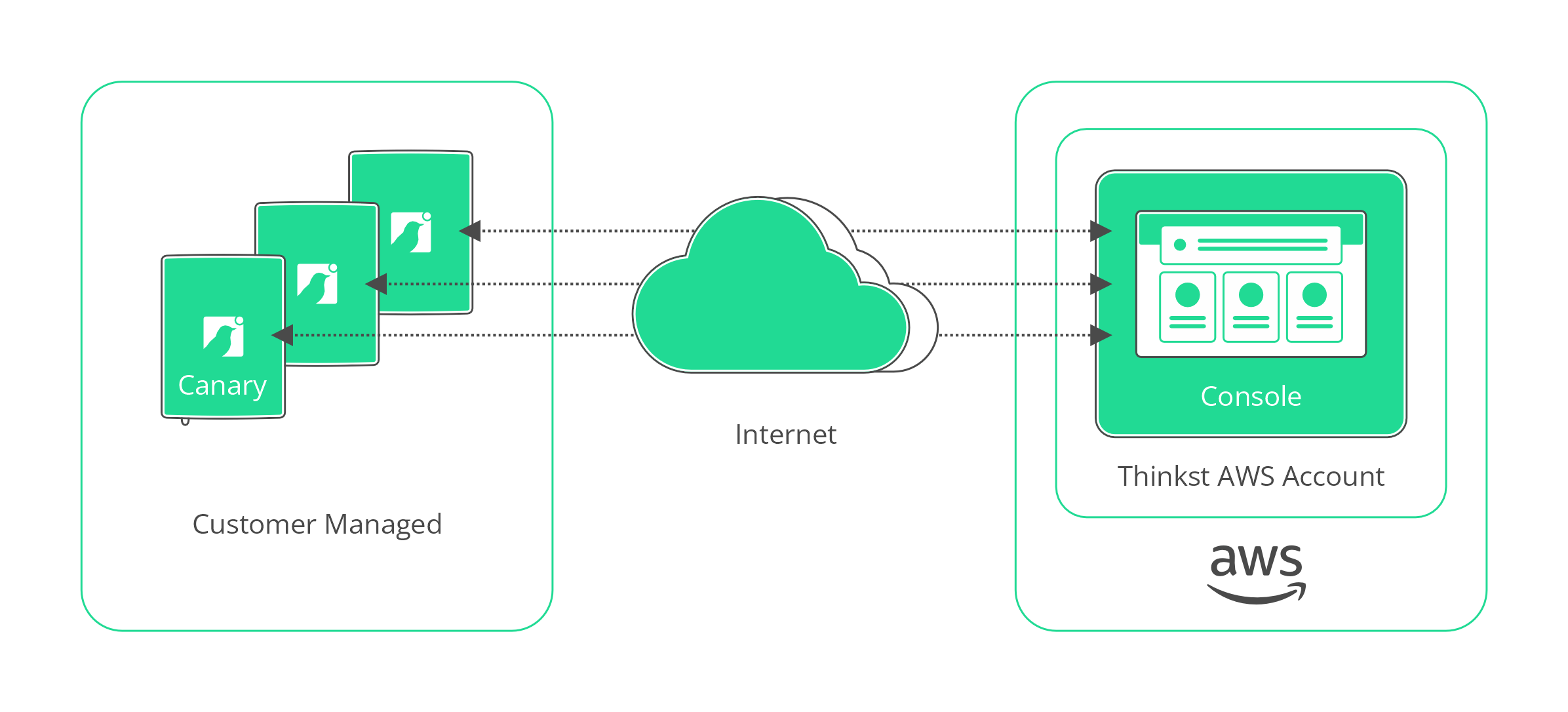
Pourquoi cette décision ? C’est précisément le sujet de cet article. Canary est régulièrement évalué par des testeurs de sécurité externes. Il est toujours intéressant de voir leurs réactions lorsqu’ils apprennent que les clients de Canary ne sont pas co-localisés. Les visages se décomposent, des notes furieuses sont prises, et les questions fusent pour tenter de découvrir de nouvelles failles potentielles.
J’ai moi-même réalisé ce type de consultation en sécurité, et l’accès non autorisé aux données d’autres utilisateurs était un problème que nous rencontrions systématiquement lors des tests d’applications multi-tenant (en particulier les applications web). Les possibilités d’exploration sont nombreuses. Les références d’objets directs non sécurisées (par exemple, accéder à l’extrait de compte de n’importe qui en itérant à travers l’identifiant numérique dans l’URL https://banquevulnerable.com/compte/extrait?id=4728309), les bugs de script intersites utilisant la messagerie dans l’application entre utilisateurs, les bugs côté serveur permettant à l’attaquant d’accéder localement au serveur et ainsi de voir toutes les données, les bugs d’injection de requêtes (comme SQLi) permettant à l’attaquant d’extraire des données directement de la base de données sans autres vérifications, et bien d’autres. Une des causes profondes de ces attaques était la co-localisation des données d’organisations non liées.
Lors de la conception de l’architecture de Canary, nous avons explicitement voulu maintenir les données des clients séparées par une barrière solide, et pas seulement par des vérifications de permissions au niveau de l’application. Nous avons opté pour un modèle qui nous permettait un isolement complet entre les clients : ils ne partageaient pas de services, de bases de données, ni de ressources comme les adresses IP.
Cela a entraîné des inconvénients sur le plan opérationnel (et a influencé la conception du produit), mais nous sommes extrêmement satisfaits de cet échange. Dans cet article, nous allons explorer ce modèle plus en détail et fournir des exemples clairs de son efficacité. Commençons par une brève explication des services que nous proposons réellement.
Exigences de service
Pour fournir Thinkst Canary à nos clients, nous devons exécuter plusieurs services. La Console est un site web fonctionnant sur uWSGI et Nginx ; il y a des configurations de honeypot et des données d’alerte qui doivent être stockées de manière persistante et récupérées rapidement ; des services pour communiquer avec les dispositifs déployés ; des services Canarytoken qui gèrent le trafic HTTP et DNS sur une adresse IP distincte de l’interface de gestion ; et un service séparé pour expédier des alertes via Syslog pour les clients qui le souhaitent.
Ensemble, ces éléments constituent le produit Thinkst Canary.
Notre architecture : isolement des VM
Tous les services de la Console Canary pour un client unique sont contenus dans leur propre instance AWS EC2. En d’autres termes, nous exécutons une machine virtuelle par client.
Dans certains cercles, cette approche n’est pas considérée comme attrayante. Il n’y a pas de conteneurs, pas de fonctions sans serveur, pas de bases de données cloud, pas de support hyperscale, pas de bus de messages (enfin… il y en a, mais ils existent uniquement sur l’instance), pas d’équilibreurs de charge, pas de clusters k8s. Rien ici ne nous vaudra une invitation à prendre la parole lors d’événements CNCF, ni un diagramme d’architecture rempli d’icônes de services AWS, et nous acceptons volontiers ce compromis.
Le fait est que les architectures cloud peuvent devenir des caricatures d’elles-mêmes. Le design de référence d’AWS pour héberger WordPress ressemble à ceci :

En termes généraux, les principaux bénéficiaires des architectures cloud-native sont les développeurs et les opérateurs d’un service, et non leurs clients. Vos clients ne se soucient pas de savoir si votre base de données est hébergée sur RDS, Aurora, ou si elle fonctionne sur un serveur physique dans un centre de données, tant qu’ils peuvent accéder aux données de manière fiable, sécurisée et rapide. La technologie cloud-native facilite la construction de tels systèmes pour les développeurs et les opérateurs, mais les clients (en moyenne) n’ont pas d’exigences concernant l’utilisation de la technologie cloud (ou non).
Adopter des technologies et des approches natives du cloud présente des défis spécifiques. Pour nous, le principal problème réside dans le fait que la frontière de sécurité qui sépare les clients devient une question d’application, ce qui est trop risqué. En tant que fournisseur de solutions de sécurité, une violation des données clients est un scénario cauchemardesque.
Imaginons un modèle de déploiement classique où les données des clients sont centralisées dans une seule base de données ou un nombre restreint de bases de données (qu’il s’agisse d’une base de données relationnelle, d’une base de données documentaire, ou autre). Les frontières entre ces données seraient soit imposées par la base de données via différents utilisateurs et rôles, soit (plus couramment) par l’application de requête qui applique des vérifications d’autorisation après que les données ont été récupérées de la base de données ou dans le cadre de la requête fournie par l’application à la base de données. Si l’application est responsable du maintien de cette frontière, alors toute vulnérabilité permettant à un attaquant de contourner la vérification d’autorisation violerait cette frontière. Chaque requête, chaque récupération de données est une source potentielle de vulnérabilités, et doit être soigneusement protégée. Aucune erreur n’est permise. Cela est vrai chaque fois que les données sont co-localisées ou que les utilisateurs dépendent des mêmes points d’accès et adresses web pour accéder aux données. Ces problèmes sont malheureusement très fréquents.
Modifier notre backend web pour s’appuyer sur des Lambdas serait une approche désastreuse pour plusieurs raisons, et ignorerait l’interrelation avec d’autres services (comme les communications entre appareils). De même, AWS IoT ne convient pas pour la gestion de nos appareils ; nous opérons dans des réseaux où les communications sortantes MQTT et HTTPS ne sont tout simplement pas autorisées (c’est pourquoi nous utilisons un trafic DNS chiffré pour la communication entre appareils et la console). En d’autres termes, assembler le même service à partir des blocs de services AWS donnerait un produit plus encombrant et moins centré sur le client. En revanche, si nous prenons la responsabilité de construire ces blocs nous-mêmes, nous pouvons créer un service qui s’assemble harmonieusement, comme un puzzle complexe sur mesure.
Bien que l’approche des machines virtuelles isolées présente des inconvénients, elle offre également de nombreux avantages.
Avantages
Externalisation du problème le plus complexe
En adoptant cette approche éprouvée, nous comptons sur l’hyperviseur d’AWS pour maintenir une frontière de sécurité assistée par silicium. En effet, l’ensemble de l’activité de cloud computing d’AWS repose sur la robustesse de leur hyperviseur. Les bugs dans cet hyperviseur qui permettraient un accès inter-client représentent une menace existentielle pour AWS, et ils ont un intérêt profond à maintenir cette frontière. Ils ont prouvé leur capacité à gérer et à maintenir cet hyperviseur sur une longue période. De plus, dans le cas extrême où un bug 0day de l’hyperviseur serait utilisé pour attaquer un client, il faudrait d’abord que l’attaquant place sa machine virtuelle d’attaque sur le même hôte physique que celle de notre client, et seulement un client serait affecté ; la zone d’impact est naturellement limitée.
Performance et surveillance
Faire fonctionner tous les services liés à un client sur la même instance simplifie considérablement certains types de surveillance et d’investigation. Nous n’avons pas besoin de collecter des données de performance provenant de plusieurs systèmes pour comprendre ce qu’un client expérimente ; tout est déjà centralisé. Nous gérons un serveur DNS personnalisé, et parfois le débogage implique des captures de paquets pour comprendre les problèmes ; il est extrêmement utile de savoir que le trafic à la console est lié au problème du client en cours d’examen.
Inversement, isoler les services d’un client dans une machine virtuelle signifie que toute augmentation d’utilisation ou dégradation de service est limitée à cette seule console. Les pannes se produisent ; nous rencontrons régulièrement des problèmes matériels sur EC2, et lorsque cela se produit, c’est une seule console qui est affectée (et automatiquement restaurée), et non l’ensemble du service pour tous les clients. Dans un scénario hypothétique où tous nos services fonctionnent dans un cluster Kubernetes, tous nos œufs seraient dans le même panier. Une défaillance de Kubernetes affecterait tous les clients ; dans le modèle VM, il faudrait que « AWS dans plusieurs régions échoue simultanément » pour trouver un point de défaillance unique.
Les machines virtuelles isolées sont simplement une étape vers l’évolutivité horizontale d’origine (c’est-à-dire plus de serveurs physiques). Notre modèle d’évolutivité lors de l’ajout de nouveaux clients consiste à dupliquer l’infrastructure pour eux, plutôt que de les entasser avec les autres. Cela signifie que nous ne nous concentrons pas sur l’optimisation excessive d’un petit nombre de services que tous les clients finissent par utiliser. Nos consoles ont des besoins de calcul modestes et, dans la plupart des cas, fonctionnent sur des instances EC2 « petites ». La charge moyenne est généralement d’environ 0,04, et la charge au 99e percentile est de 0,5.
Conformité réglementaire
Avoir des machines virtuelles par client nous permet de répondre facilement aux exigences réglementaires ; certains clients doivent conserver leurs données dans une région géographique spécifique pour des raisons de conformité. Il est trivial pour nous de gérer ces demandes et nous pouvons actuellement ajouter de nouvelles régions en quelques heures à notre liste de régions prises en charge. En revanche, si nous dépendions d’une infrastructure partagée, l’ajout de nouvelles régions serait une tâche complexe et coûteuse.
Déploiements progressifs
Cette approche nous permet également de déployer du code et des fonctionnalités à des sous-ensembles de clients de manière simple avant de les rendre disponibles à tous. Le nouveau code est déployé de manière échelonnée à travers la flotte et, en conséquence, les déploiements seront suspendus si nous détectons des erreurs avant que le code n’atteigne tous les clients.
Sécurité opérationnelle
Nous pouvons également mettre en œuvre un filtrage IP au niveau du groupe de sécurité pour les clients, si cela est nécessaire. Ce niveau d’isolement n’est tout simplement pas possible sur une infrastructure partagée.
En construisant l’application, notre modèle utilisateur est simplifié car nous n’avons pas besoin de prendre en compte une frontière organisationnelle entre les ensembles de données. Nous avons des utilisateurs de différents niveaux d’autorisation, mais tous appartiennent à la même organisation. Cela rend le code d’autorisation plus facile à comprendre et aide à accélérer le développement.
Avantages illusoires
Un argument souvent avancé en faveur du modèle VM est qu’il réduit la dépendance à un fournisseur de cloud unique, facilitant ainsi la transition, car théoriquement, vous pouvez simplement exécuter votre VM ailleurs. Bien qu’il soit vrai que nous ne dépendons pas entièrement d’AWS pour l’environnement de calcul (car nous fournissons notre propre VM), nous restons néanmoins tributaires d’autres services AWS, notamment en matière de surveillance, d’orchestration et de services réseau. Passer à un autre fournisseur serait complexe, et je ne considère pas la VM comme un véritable avantage à cet égard. La barrière à la transition reste extrêmement élevée.
Inconvénients
Le revers de la médaille est que nous supportons des coûts opérationnels plus élevés en termes d’effort et de dépenses. Maintenir des milliers d’instances exige de notre part une maîtrise de la gestion de configuration. Nous devons penser à la fois en termes de configuration à grande échelle (gérer des milliers d’instances) et à des problèmes très locaux (un exemple récent est le changement de comportement des permissions de /tmp sur Ubuntu, nécessitant des personnalisations dans /etc/sysctl.conf. Dans un monde de conteneurs, quelqu’un d’autre aurait probablement géré cela). Nos compétences en administration système Linux nous ont été très utiles ; sans de bonnes compétences en administration, cette voie aurait été difficile à suivre.
Les Défis et Avantages des Machines Virtuelles Isolées
L’utilisation de machines virtuelles (VM) isolées présente des défis uniques, mais elle offre également des avantages significatifs en matière de sécurité et de gestion des données. Dans cet article, nous explorerons les implications de cette approche sur la conception des produits, le suivi personnalisé, la dépendance matérielle, les limitations, ainsi que les coûts associés.
Impact sur la Conception des Produits
L’intégration des VM isolées dans notre infrastructure est essentielle. Lors de la livraison de nos appareils, qu’ils soient matériels ou logiciels, il est crucial qu’ils puissent identifier leur Console. Ce processus de découverte est fondamental et mérite une attention particulière.
Suivi Personnalisé
Bien qu’AWS propose des vérifications d’instance pour surveiller la santé des systèmes, nous avons dû développer des outils de suivi sur mesure. Avec des milliers d’instances et d’adresses IP, ainsi que des entrées DNS et plusieurs services, il est impératif de détecter toute inactivité dans un délai de quelques minutes. Nous avons donc conçu des outils spécifiques pour surveiller l’état de chaque instance, tout en effectuant également un suivi interne pour anticiper d’éventuels modes de défaillance.
Dépendance Matérielle et Limitations
L’isolation des pannes matérielles est un avantage indéniable, car elle ne touche qu’une seule Console en cas de défaillance. Cependant, cela signifie qu’un client peut être hors ligne jusqu’à ce que notre système redémarre automatiquement la VM, ce qui se produit généralement en quelques minutes. Bien que nous n’ayons pas encore atteint de limites significatives en termes de taille d’instance, il existe une limite théorique à une instance par client, qui est la plus grande instance EC2 disponible. Cependant, cela ne nous préoccupe pas, car nous n’avons pas encore atteint la moitié de la progression des tailles d’instance, même pour nos clients les plus exigeants.
Déploiements Plus Lents
Le déploiement de code sur des milliers d’instances prend généralement plusieurs heures, car nous procédons par étapes de plus en plus larges. Si nous utilisions un nombre réduit de serveurs massifs, le déploiement serait probablement plus rapide.
Coûts Associés
Cette approche est presque certainement plus coûteuse. Nos instances restent souvent inactives, ce qui entraîne des frais importants pour EC2. C’est probablement le principal inconvénient pour de nombreuses organisations envisageant cette méthode. Bien que cette stratégie soit plus onéreuse que le modèle traditionnel, elle n’est pas prohibitive, car les coûts augmentent de manière linéaire avec le nombre de clients. Si vous êtes en difficulté financière et espérez améliorer vos marges en augmentant le nombre de clients sur la même infrastructure, cette approche n’est pas adaptée.
Malgré ces inconvénients, les avantages l’emportent largement sur les inconvénients. Nous avons des exemples concrets où le modèle de VM isolées a prouvé son efficacité.
Études de Cas
Étude de Cas 1 : Console de Débogage
Dans nos débuts, un incident a eu lieu sur une Console où un développeur avait laissé un débogueur accessible sur le Web. Si des données clients avaient été présentes, nous aurions dû gérer une réponse externe et publier des annonces de violation. Cependant, grâce à la VM isolée, il n’y avait aucune donnée client sur cette VM. Après avoir détecté l’incident, nous avons simplement détruit cette infrastructure et mis en place des contrôles pour éviter que ce problème ne se reproduise.
Étude de Cas 2 : Bugs d’Application Web
Au fil des années, lors des évaluations de sécurité, plusieurs classes de bugs ont été identifiées, mais jamais d’accès aux données d’un autre client. Nous privilégions les tests en boîte claire et fournissons le code source lors des tests. Même après des exploits astucieux avec un accès complet au code source, il est impossible d’accéder à des données qui n’existent pas.
Étude de Cas 3 : osslsigncode
Plus tôt cette année, nous avons découvert qu’une version vulnérable d’un package appelé osslsigncode était installée, malgré le paiement pour des correctifs de sécurité dans Ubuntu. Bien que la situation soit maintenant résolue, nous avons dû évaluer les risques pour décider si nous devions expédier notre propre version ou mettre à jour vers une version d’Ubuntu où le correctif était déjà disponible. Si nous avions utilisé une infrastructure partagée, nous aurions dû agir rapidement pour éviter qu’un client n’exploite la vulnérabilité.
Cependant, grâce au modèle de VM isolées, notre évaluation des risques a abouti à une conclusion différente. Nous avons déterminé qu’un attaquant devait être authentifié et que l’accès à d’autres données était impossible. Cela a considérablement réduit la valeur de l’attaque, nous permettant de résoudre le problème de manière approfondie.
Faut-il Opter par Défaut pour des VM Isolées ?
La réponse n’est pas évidente. Nous avons réfléchi aux compromis, et pour notre profil de risque, le hyperviseur AWS est la limite avec laquelle nous sommes le plus à l’aise. Nos clients préfèrent que leurs données restent privées plutôt que de savoir si nous utilisons divers outils Cloud. Nous choisissons systématiquement la sécurité sur la commodité.
Nous sommes conscients que cela entraîne des coûts, tant en termes de produit que d’opérations. Nous sommes prêts à assumer ces coûts, car cela nous permet de dormir sur nos deux oreilles.
Le choix dépend de votre capacité à supporter les coûts liés à des systèmes souvent inactifs, de votre capacité à gérer des milliers d’instances et de votre volonté de réimplémenter des outils pour votre propre infrastructure. L’avantage est une barrière de sécurité très robuste. Nous sommes satisfaits de cette voie.




Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Technologie
Ne manquez pas cette offre incroyable : le Air Fryer Moulinex Easy Fry Max à -42% sur Amazon !
Les soldes d’hiver sont là ! Ne ratez pas l’incroyable offre d’Amazon sur le Moulinex Easy Fry Max, à seulement 69 euros au lieu de 119 euros, soit une réduction sensationnelle de -42% ! Avec sa capacité généreuse de 5 L, cette friteuse sans huile est idéale pour régaler jusqu’à 6 convives. Grâce à ses 10 programmes de cuisson et son interface tactile intuitive, préparez des plats sains et savoureux en un clin d’œil. Dépêchez-vous, les stocks s’épuisent vite et cette offre est limitée dans le temps !

Technologie
Les soldes d’hiver sont en cours, et Amazon en profite pour offrir des promotions intéressantes, notamment sur les friteuses à air. Actuellement, le Moulinex Easy Fry Max est proposé à un prix attractif de 69 euros au lieu de 119 euros, ce qui représente une réduction immédiate de 42 %. C’est une occasion parfaite pour acquérir une friteuse sans huile XL d’une capacité généreuse de 5 L, idéale pour préparer des repas pour jusqu’à six personnes à un tarif très compétitif.
Étant donné que cette offre est limitée dans le temps,il est conseillé d’agir rapidement si vous souhaitez en bénéficier. De plus, avec un tel prix, les stocks pourraient s’épuiser rapidement. Ce modèle se classe parmi les meilleures ventes sur Amazon avec plus de 1000 unités écoulées le mois dernier.
Profitez des offres sur Amazon
Amazon propose également la livraison gratuite et rapide pour cet article qui bénéficie d’une garantie de deux ans. En outre, il existe une option de paiement échelonné en quatre fois sans frais sur ce modèle. Enfin, sachez que vous avez la possibilité de changer d’avis et retourner le produit gratuitement dans un délai de 30 jours afin d’obtenir un remboursement intégral.
Moulinex Easy Fry Max : cuisinez sainement pour toute la famille
Le moulinex Easy Fry Max fonctionne comme un four à air chaud permettant la préparation de plats savoureux tout en utilisant peu ou pas du tout d’huile. En plus des frites croustillantes qu’il réalise parfaitement, cet appareil se révèle très polyvalent et peut cuisiner une multitude d’autres recettes.
avec ses dix programmes prédéfinis adaptés à divers ingrédients tels que poulet,steak,poisson ou légumes ainsi que des options pour bacon et desserts comme les pizzas ,cet appareil répond aux besoins variés des familles modernes. De plus, Moulinex met à disposition un livre numérique rempli de recettes accessible via QR Code afin que vous puissiez facilement trouver l’inspiration culinaire lorsque nécessaire.
Sa capacité généreuse permet non seulement la préparation rapide mais aussi économique : jusqu’à 70 % moins énergivore et presque deux fois plus rapide qu’un four traditionnel ! Son interface intuitive avec écran tactile facilite son utilisation quotidienne.
en outre, le panier antiadhésif compatible lave-vaisselle simplifie grandement l’entretien après chaque utilisation. N’oubliez pas qu’il s’agit là encore d’une offre temporaire ; ne tardez donc pas si vous souhaitez profiter du meilleur prix possible sur cette friteuse innovante !
Pour accéder à cette remise exceptionnelle :
Technologie
TikTok revient en force aux États-Unis, mais pas sur l’App Store !
Le suspense autour de TikTok est à son comble ! En avril 2024, le Congrès américain a voté une loi obligeant l’application à changer de propriétaire avant le 19 janvier. Les utilisateurs ont anxieusement attendu la décision finale. Bien que TikTok ait brièvement cessé ses activités, elle est revenue en ligne, mais absente de l’App Store. Apple justifie cette décision par des obligations légales. Cependant, les utilisateurs peuvent toujours accéder à leur compte… sans mises à jour. L’avenir de TikTok pourrait prendre un tournant décisif avec les promesses du nouveau président.

Technologie
En avril 2024, le Congrès américain a adopté une législation obligeant TikTok à trouver un nouvel acquéreur, ByteDance étant accusé d’activités d’espionnage. Les utilisateurs de l’submission aux États-Unis ont donc attendu avec impatience le week-end précédent la date limite du 19 janvier pour savoir si TikTok serait interdit dans le pays.
Bien que TikTok n’ait pas réussi à dénicher un repreneur avant cette échéance, l’application a temporairement suspendu ses activités… mais seulement pour quelques heures. le réseau social est désormais de retour en ligne, mais il n’est plus accessible sur l’App Store.
Retour de TikTok : Une Absence Persistante sur l’App Store
Apple a expliqué sa décision de retirer TikTok de son App store par un communiqué officiel. « Apple doit respecter les lois en vigueur dans les régions où elle opère. Selon la loi Protecting Americans from Foreign Adversary Controlled Applications act, les applications développées par ByteDance ltd., y compris TikTok et ses filiales comme CapCut et Lemon8, ne pourront plus être téléchargées ou mises à jour sur l’App Store pour les utilisateurs américains après le 19 janvier 2025 », précise la société.
Il est crucial de souligner que les utilisateurs américains ayant déjà installé TikTok peuvent toujours accéder au service. Cependant, ils ne recevront plus aucune mise à jour future de l’application. L’avenir du réseau social pourrait dépendre des décisions du nouveau président des États-Unis.
DÉCLARATION DE TIKTOK :
>
En collaboration avec nos partenaires techniques, nous travaillons activement à rétablir notre service. Nous remercions le président Trump pour avoir clarifié la situation et rassuré nos partenaires qu’ils ne subiront aucune sanction en continuant d’offrir TikTok aux plus de 170 millions d’utilisateurs…
Le successeur de Joe Biden sera investi comme président ce lundi 20 janvier et prévoit d’émettre un décret afin d’accorder un délai supplémentaire à TikTok pour trouver un acquéreur potentiel.Donald Trump propose même que les États-Unis détiennent une participation significative dans cette application.
« Je souhaite que les États-Unis possèdent une part importante dans une coentreprise avec cet outil numérique afin que nous puissions préserver son intégrité tout en lui permettant d’évoluer […]. Ainsi,notre pays détiendrait la moitié des parts dans une coentreprise établie entre nous et tout acheteur sélectionné »,a déclaré Donald Trump.
L’avenir immédiat de TikTok pourrait donc connaître des évolutions majeures très prochainement. Il convient également de noter qu’une rumeur circulait selon laquelle Elon Musk envisagerait d’acquérir des parts dans la plateforme,mais celle-ci a été rapidement démentie par un porte-parole officiel.
-
 Business2 ans ago
Business2 ans agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoLes meilleures offres du MacBook Pro ce mois-ci !