OpenAI a enfin présenté son modèle linguistique tant attendu, surnommé « Fraise« , affirmant des améliorations notables en matière de raisonnement et de résolution de problèmes par rapport aux modèles linguistiques précédents. Officiellement nommé « OpenAI o1« , cette nouvelle famille de modèles sera d’abord disponible en deux versions : o1-preview et o1-mini, accessibles dès aujourd’hui pour les utilisateurs de ChatGPT Plus et certains utilisateurs d’API.
Selon OpenAI, le modèle o1-preview surpasse son prédécesseur, le GPT-4o, sur plusieurs critères, notamment la programmation compétitive, les mathématiques et le raisonnement scientifique. Cependant, certains utilisateurs rapportent que le modèle ne surpasse pas encore le GPT-4o dans tous les domaines. D’autres critiques portent sur le temps de réponse, qui peut être long en raison du traitement multi-étapes effectué avant de répondre à une requête.
Dans un rare effort de clarification, la responsable produit d’OpenAI, Joanne Jang, a tweeté : « Il y a beaucoup de battage autour de o1 sur mon fil, et je crains que cela ne crée de fausses attentes. Ce que o1 est : le premier modèle de raisonnement qui excelle dans des tâches vraiment difficiles, et il ne fera que s’améliorer. (Je suis personnellement enthousiaste quant au potentiel et à l’évolution du modèle !) Ce que o1 n’est pas (encore !) : un modèle miracle qui fait tout mieux que les modèles précédents. Vous pourriez être déçu si c’est votre attente pour le lancement d’aujourd’hui, mais nous travaillons pour y parvenir ! »
OpenAI indique que o1-preview a atteint le 89e percentile sur des questions de programmation compétitive sur Codeforces. En mathématiques, il a obtenu 83 % à un examen de qualification pour l’Olympiade internationale de mathématiques, contre seulement 13 % pour le GPT-4o. De plus, OpenAI affirme que o1 se comporte de manière comparable à des étudiants en doctorat sur des tâches spécifiques en physique, chimie et biologie. Le modèle plus petit, o1-mini, est conçu spécifiquement pour les tâches de codage et est proposé à un prix 80 % inférieur à celui de o1-preview.
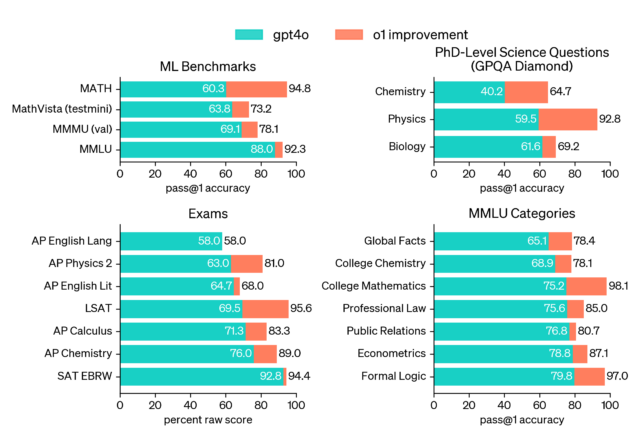
Agrandir / Un graphique de référence fourni par OpenAI. Ils écrivent : « o1 améliore GPT-4o sur une large gamme de critères, y compris 54/57 sous-catégories MMLU. Sept sont montrées à titre d’illustration. »
OpenAI attribue les avancées de o1 à une nouvelle approche d’apprentissage par renforcement (RL) qui enseigne au modèle à passer plus de temps à « réfléchir » aux problèmes avant de répondre, similaire à la méthode de « réfléchissons étape par étape » qui peut améliorer les résultats dans d’autres LLM. Ce nouveau processus permet à o1 d’essayer différentes stratégies et de « reconnaître » ses propres erreurs.
Les benchmarks en IA sont souvent peu fiables et faciles à manipuler ; cependant, la vérification indépendante et les expérimentations des utilisateurs révéleront l’étendue des avancées de o1 au fil du temps. Il est à noter qu’une recherche du MIT a montré plus tôt cette année que certaines des affirmations de référence qu’OpenAI avait mises en avant avec GPT-4 l’année dernière étaient erronées ou exagérées.
Technologie : Un éventail de capacités
Démonstration de OpenAI « o1 » comptant correctement le nombre de R dans le mot « fraise. »
Parmi les nombreuses vidéos de démonstration montrant o1 accomplissant des tâches de programmation et résolvant des énigmes logiques, une démonstration s’est démarquée comme étant peut-être la moins significative, mais elle pourrait devenir la plus discutée en raison d’un mème récurrent où les gens demandent aux LLM de compter le nombre de R dans le mot « fraise ».
En raison de la tokenisation, où le LLM traite les mots par morceaux appelés tokens, la plupart des LLM ne perçoivent généralement pas les différences caractère par caractère dans les mots. Apparemment, o1 possède des capacités d’auto-réflexion lui permettant de compter les lettres et de fournir une réponse précise sans assistance de l’utilisateur.
Au-delà des démonstrations d’OpenAI, des rapports prudents mais optimistes sur o1-preview circulent en ligne. Le professeur de Wharton, Ethan Mollick, a écrit sur X : « J’utilise GPT-4o1 depuis un mois. C’est fascinant — il ne fait pas tout mieux, mais il résout certains problèmes très difficiles pour les LLM. Cela indique également de nombreux gains futurs. »
Mollick a partagé un article détaillant ses expériences avec le nouveau modèle sur son blog « One Useful Thing ». « Pour être clair, o1-preview ne fait pas tout mieux. Ce n’est pas un meilleur écrivain que GPT-4o, par exemple. Mais pour les tâches nécessitant de la planification, les changements sont assez importants. »
Il a donné l’exemple de demander à o1-preview de construire un simulateur d’enseignement « utilisant plusieurs agents et de l’IA générative, inspiré par l’article ci-dessous et en tenant compte des points de vue des enseignants et des étudiants », puis de lui demander de produire le code complet, et le résultat a impressionné Mollick.
Mollick a également donné à o1-preview huit indices de mots croisés, traduits en texte, et le modèle a mis 108 secondes pour les résoudre en plusieurs étapes, obtenant toutes les réponses correctes mais confondant un indice que Mollick ne lui avait pas donné. Nous recommandons de lire l’intégralité du post de Mollick pour une bonne première impression. D’après son expérience avec le nouveau modèle, il semble que o1 fonctionne de manière très similaire à GPT-4o, mais de manière itérative, ce qui est quelque chose que les projets « agentic » AutoGPT et BabyAGI ont expérimenté au début de 2023.
Technologie : Est-ce ce qui pourrait « menacer l’humanité » ?
En parlant de modèles agentiques qui fonctionnent en boucle, le modèle Fraise a été sujet à un battage médiatique depuis novembre dernier, lorsqu’il était initialement connu sous le nom de Q* (Q-star). À l’époque, The Information et Reuters avaient rapporté qu’avant le bref renvoi de Sam Altman en tant que PDG, des employés d’OpenAI avaient averti en interne le conseil d’administration d’OpenAI au sujet d’un nouveau modèle qui pourrait « menacer l’humanité ».
En août, le battage médiatique a continué lorsque The Information a rapporté qu’OpenAI avait présenté Fraise à des responsables de la sécurité nationale américaine.
Nous avons été sceptiques quant à l’engouement autour de Q* et de Fraise depuis le début des rumeurs, comme l’a noté cet auteur en novembre dernier, et Timothy B. Lee a couvert en profondeur ce sujet dans un excellent article sur Q* en décembre dernier.
Ainsi, même si o1 est désormais disponible, les observateurs de l’industrie de l’IA devraient noter comment le lancement imminent de ce modèle a été amplifié dans la presse comme une avancée dangereuse, sans être minimisé publiquement par OpenAI. Pour un modèle d’IA qui met 108 secondes à résoudre huit indices dans un mot croisé et qui hallucine une réponse, nous pouvons dire que son potentiel danger était probablement exagéré (pour l’instant).
Technologie : Controverse autour de la terminologie du « raisonnement »
Il n’est pas surprenant que certaines personnes dans le secteur technologique aient des problèmes avec l’anthropomorphisme des modèles d’IA et l’utilisation de termes comme « penser » ou « raisonner » pour décrire les opérations de synthèse et de traitement que ces systèmes de réseaux neuronaux effectuent.
Juste après l’annonce de OpenAI o1, le PDG de Hugging Face, Clement Delangue, a écrit : « Encore une fois, un système d’IA ne ‘pense’ pas, il ‘traite’, ‘exécute des prédictions’,… tout comme Google ou les ordinateurs. Donner l’impression erronée que les systèmes technologiques sont humains est juste une arnaque bon marché et un marketing pour vous tromper en pensant qu’ils sont plus intelligents qu’ils ne le sont. »
Le terme « raisonnement » est également quelque peu nébuleux, car même chez les humains, il est difficile de définir exactement ce que cela signifie. Quelques heures avant l’annonce, le chercheur indépendant en IA Simon Willison a tweeté en réponse à un article de Bloomberg sur Fraise : « J’ai encore du mal à définir ‘raisonnement’ en termes de capacités des LLM. Je serais intéressé de trouver une invite qui échoue sur les modèles actuels mais réussit sur fraise, ce qui aiderait à démontrer la signification de ce terme. »
Qu’il s’agisse de raisonnement ou non, o1-preview manque actuellement de certaines fonctionnalités présentes dans les modèles antérieurs, telles que la navigation sur le web, la génération d’images et le téléchargement de fichiers. OpenAI prévoit d’ajouter ces capacités dans de futures mises à jour, tout en continuant le développement des séries de modèles o1 et GPT.
Bien qu’OpenAI affirme que les modèles o1-preview et o1-mini sont en cours de déploiement aujourd’hui, aucun des deux modèles n’est encore disponible dans notre interface ChatGPT Plus, nous n’avons donc pas pu les évaluer. Nous rapporterons nos impressions sur la manière dont ce modèle diffère des autres LLM que nous avons précédemment couverts.