Postgres : La magie du stockage des données sur disque !
I remember when I first started on server-side applications – the kind that need to persist data – and not getting what the big deal about databases was. Why are databases such a big thing? Can’t we just store some data on disk and read / write from it when we need to? (Spoiler: no.)
Comprendre les Bases de Données : Une Exploration de PostgreSQL
Introduction aux Bases de Données
Lorsque j’ai commencé à travailler sur des applications côté serveur nécessitant la persistance des données, je ne comprenais pas vraiment l’importance des bases de données. Pourquoi sont-elles si essentielles ? Ne peut-on pas simplement enregistrer des données sur un disque et y accéder au besoin ? (Réponse : non.)
En m’immergeant dans des projets concrets plutôt que de simples expériences, j’ai réalisé que les bases de données sont en quelque sorte magiques, et que SQL est le langage qui permet d’exploiter cette magie. On pourrait facilement considérer les bases de données comme une boîte noire où il suffit de s’assurer que les tables sont correctement indexées et que les requêtes sont optimisées, et le reste se déroule sans effort.
Cependant, les bases de données ne sont pas aussi complexes qu’elles en ont l’air. Bien qu’elles présentent une certaine complexité, en explorant un peu le moteur de la base de données, on découvre qu’il s’agit principalement d’abstractions puissantes et intelligentes. Comme pour la plupart des logiciels, la complexité réside souvent dans les cas particuliers, notamment en ce qui concerne la concurrence.
Plongée dans PostgreSQL
Je vais examiner de plus près les moteurs de bases de données, en me concentrant sur PostgreSQL, qui est le système de gestion de bases de données le plus utilisé par les développeurs, selon les enquêtes de Stack Overflow de 2023 et 2024.
Installation de PostgreSQL
PostgreSQL stocke toutes ses données dans un répertoire nommé de manière appropriée : /var/lib/postgresql/data. Pour explorer cela, nous allons créer une installation vide de PostgreSQL à l’aide de Docker et monter le répertoire de données dans un dossier local afin de voir ce qui s’y trouve. (N’hésitez pas à suivre ces étapes et à explorer les fichiers par vous-même !)
docker run --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:16
Vous devriez voir une série de messages intéressants, tels que selecting dynamic shared memory implementation ... posix et performing post-bootstrap initialization ... ok, suivis de LOG: database system is ready to accept connections. Une fois cela fait, arrêtez le serveur avec ctrl-C pour examiner les fichiers créés.
$ ls -l pg-data
Vous constaterez qu’il y a de nombreux dossiers, mais la plupart d’entre eux sont vides.
Terminologie Essentielle
Avant d’approfondir, voici un aperçu rapide de quelques termes clés :
Terme
Signification
Cluster de bases de données
Le terme « cluster » désigne ici une instance unique d’un serveur PostgreSQL exécutant plusieurs bases de données sur la même machine.
Conclusion
En explorant les bases de données, en particulier PostgreSQL, nous découvrons un monde fascinant d’abstractions et de mécanismes qui, bien que complexes, sont accessibles à ceux qui prennent le temps de les comprendre. Les bases de données ne sont pas seulement des outils de stockage, mais des systèmes dynamiques qui permettent de gérer efficacement les données dans des applications modernes.
Comprendre la Structure et le Fonctionnement de PostgreSQL
Introduction à PostgreSQL
PostgreSQL est un système de gestion de bases de données relationnelles puissant et open-source. Il est largement utilisé pour sa robustesse et sa capacité à gérer des volumes de données importants. Cet article explore les concepts fondamentaux de PostgreSQL, y compris la connexion à la base de données, les transactions, et la structure des données.
Connexion à la Base de Données
Lorsqu’un client établit une connexion avec le serveur PostgreSQL, un processus secondaire est créé pour gérer cette connexion. Ce mécanisme permet de gérer efficacement les requêtes des utilisateurs tout en maintenant la performance du serveur.
Sessions de Base de Données
Une fois la connexion authentifiée, une session est établie. Cette session permet au client d’exécuter des requêtes SQL. Les sessions sont essentielles pour interagir avec la base de données et effectuer des opérations sur les données.
Transactions : Unité de Travail
Les requêtes SQL sont exécutées dans le cadre de transactions, qui représentent des unités de travail. Chaque transaction est traitée comme un tout : elle peut être validée (commit) ou annulée (rollback) en cas d’échec. Cela garantit l’intégrité des données, car toutes les modifications apportées dans une transaction sont soit entièrement appliquées, soit complètement annulées.
Instantanés de Transaction
Chaque transaction a sa propre vue de la base de données, connue sous le nom d’instantané. Dans un environnement où plusieurs sessions accèdent simultanément aux mêmes données, chaque session peut voir un instantané différent, ce qui permet d’éviter les conflits de lecture et d’écriture. Il est également possible de synchroniser et d’exporter ces instantanés.
Schémas et Organisation des Données
Une base de données est composée de plusieurs schémas, qui sont des espaces de noms logiques pour les tables, les fonctions et autres objets de la base de données. Le schéma par défaut est appelé « public ». Si aucun schéma n’est spécifié lors de la création d’une table, le schéma public est utilisé par défaut.
Tables et Espaces de Tables
Les bases de données contiennent plusieurs tables, chacune représentant une collection non ordonnée d’éléments avec un nombre défini de colonnes, chacune ayant un type spécifique. Un espace de tables, quant à lui, représente une séparation physique des données, contrairement aux schémas qui sont une séparation logique.
Lignes et Tuples
Une table est constituée de plusieurs lignes, chaque ligne étant une collection de points de données définissant un élément spécifique. Un tuple est similaire à une ligne, mais il est immuable. Il représente l’état d’une ligne à un moment donné et est un terme plus général pour désigner une collection de données.
Exploration des Dossiers et Fichiers de PostgreSQL
Il est intéressant de comprendre la structure des fichiers et des dossiers dans PostgreSQL, même si tous ne sont pas nécessaires pour une utilisation de base. Voici un aperçu des principaux répertoires :
Répertoire de Base
Le répertoire de base contient un sous-répertoire pour chaque base de données, où sont stockés les fichiers de données.
Fichiers Globaux
Le dossier global contient des fichiers pour des tables accessibles à l’ensemble du cluster, comme pg_database.
Timestamps de Transactions
Le répertoire pg_commit_ts stocke les horodatages des validations de transactions, bien qu’il soit vide si aucune transaction n’a encore été effectuée.
Mémoire Partagée Dynamique
PostgreSQL utilise un sous-système de mémoire partagée dynamique pour permettre le partage de mémoire entre plusieurs processus. Les fichiers d’objets de mémoire partagée sont stockés dans le dossier pg_dynshmem.
Configuration de l’Authentification
Le fichier pg_hba.conf permet de configurer l’accès au cluster en fonction du nom d’hôte. Par exemple, la configuration par défaut permet aux connexions locales sans mot de passe.
Décodage Logique
Le dossier pg_logical contient des données de statut pour le décodage logique, un processus qui permet de récupérer l’état attendu de la base de données à partir du journal des écritures.
Réplication
La réplication est essentielle pour la synchronisation des données entre plusieurs instances de serveur. Le dossier pg_replslot contient des données pour les différents slots de réplication, garantissant que les entrées du journal des écritures sont conservées pour des répliques spécifiques.
Transactions Sérialisables
Le dossier pg_serial contient des informations sur les transactions sérialisables, qui représentent le niveau le plus strict d’isolation des transactions.
Instantanés Exportés
Le répertoire pg_snapshots contient des instantanés exportés, utilisés par des outils comme pg_dump pour sauvegarder les données.
Conclusion
Comprendre la structure et le fonctionnement de PostgreSQL est essentiel pour tirer le meilleur parti de ce système de gestion de bases de données. En maîtrisant les concepts de connexion, de transactions et d’organisation des données, les utilisateurs peuvent gérer efficacement leurs bases de données et garantir l’intégrité des données.
Comprendre la Structure des Dossiers de PostgreSQL
Lorsqu’on explore PostgreSQL, il est essentiel de se familiariser avec la structure des dossiers qui composent cette base de données. Chaque dossier joue un rôle spécifique dans le fonctionnement et la gestion des données. Voici un aperçu des principaux dossiers que vous rencontrerez.
Dossiers de Statistiques
Le dossier pg_stat/ est crucial, car il contient des fichiers de statistiques permanents. PostgreSQL utilise ces statistiques pour optimiser les plans de requêtes. Par exemple, si le planificateur de requêtes doit effectuer un scan séquentiel sur une table, il peut estimer le nombre de lignes présentes pour déterminer la mémoire à allouer. Une bonne compréhension de ces statistiques est indispensable pour analyser et améliorer les performances des requêtes.
En revanche, le dossier pg_stat_tmp/ contient des fichiers temporaires relatifs aux statistiques, contrairement à pg_stat/ qui conserve des fichiers permanents.
Transactions et Sous-Transactions
Le dossier pg_subtrans/ est dédié aux sous-transactions, qui permettent de diviser une transaction unique en plusieurs sous-transactions. Ce dossier stocke les données d’état de ces sous-transactions.
Espaces de Table
Le dossier pg_tblspc/ contient des références symboliques vers différents espaces de table. Un espace de table est un emplacement physique utilisé pour stocker certains objets de la base de données, configuré par l’administrateur de la base de données. Par exemple, un index fréquemment utilisé peut être placé sur un disque SSD rapide, tandis que le reste de la table peut être stocké sur un disque moins coûteux et plus lent.
Transactions Préparées
Le dossier pg_twophase/ est utilisé pour les transactions préparées, permettant de dissocier une transaction de la session actuelle et de la stocker sur le disque. Cela est particulièrement utile pour les engagements en deux phases, garantissant que les modifications sont soit toutes validées, soit toutes annulées.
Configuration du Serveur
Le fichier postgresql.auto.conf contient des paramètres de configuration du serveur, automatiquement mis à jour par les commandes alter system. En revanche, postgresql.conf regroupe tous les paramètres configurables pour une instance PostgreSQL, allant de autovacuum_naptime à zero_damaged_pages. Pour une compréhension approfondie de ces paramètres, il est conseillé de consulter des ressources spécialisées.
Exploration des Dossiers de Base de Données
Le dossier base/ contient un sous-dossier pour chaque base de données de votre cluster. À la création d’un nouveau serveur PostgreSQL, trois bases de données sont automatiquement générées :
postgres – Cette base de données par défaut permet de se connecter au serveur et de gérer d’autres bases de données.
template0 et template1 – Ces bases servent de modèles pour la création de nouvelles bases de données.
Les sous-dossiers sont identifiés par des numéros, correspondant aux Identifiants d’Objet (OID) des bases de données, comme 1 pour postgres, 4 pour template0, et 5 pour template1.
Création et Manipulation de Données
Les bases de données par défaut étant vides, il est intéressant de créer une nouvelle base de données pour explorer les fichiers de données. Pour cela, nous allons exécuter un conteneur PostgreSQL :
docker run -d --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:16
Nous pouvons utiliser n’importe quel ensemble de données pour nos expérimentations.
Création d’une Base de Données de Pays avec PostgreSQL
Introduction à la Gestion des Données Géographiques
Dans cet article, nous allons explorer comment télécharger des données sur les pays et les intégrer dans une base de données PostgreSQL. Ce processus est essentiel pour quiconque souhaite gérer des informations géographiques de manière efficace.
Téléchargement des Données des Pays
Pour commencer, nous allons récupérer des données sur les pays à partir d’une source en ligne. Nous utiliserons la commande curl pour télécharger un fichier CSV contenant ces informations.
Cette commande télécharge le fichier CSV et le sauvegarde dans le répertoire spécifié.
Accès à la Base de Données
Pour examiner notre base de données, nous pouvons utiliser des outils locaux comme psql ou TablePlus. Cependant, pour simplifier le processus, nous allons accéder directement à notre conteneur Docker exécutant PostgreSQL.
Ici, nous récupérons l’ID du conteneur PostgreSQL en filtrant par le port exposé, puis nous exécutons une commande pour ouvrir un shell interactif psql.
Création de la Base de Données
Une fois que nous avons accès à psql, nous pouvons créer notre nouvelle base de données et y importer les données des pays.
create database blogdb;
c blogdb;
create table countries (
id integer primary key generated always as identity,
name text not null unique,
alpha_2 char(2) not null,
alpha_3 char(3) not null,
numeric_3 char(3) not null,
iso_3166_2 text not null,
region text,
sub_region text,
intermediate_region text,
region_code char(3),
sub_region_code char(3),
intermediate_region_code char(3)
);
Cette série de commandes crée une base de données nommée blogdb et une table countries avec des colonnes pour stocker diverses informations sur chaque pays.
Importation des Données
Pour charger les données dans notre table, nous utiliserons la commande COPY qui permet d’importer des données à partir d’un fichier CSV.
copy countries (name, alpha_2, alpha_3, numeric_3, iso_3166_2, region, sub_region, intermediate_region, region_code, sub_region_code, intermediate_region_code) from './pg-data/countries.csv' with (format csv, header);
Cette commande importe les données du fichier CSV dans la table countries, en tenant compte des en-têtes du fichier.
Conclusion
En suivant ces étapes, vous pouvez facilement créer une base de données PostgreSQL pour gérer des informations sur les pays. Ce processus est non seulement utile pour les développeurs, mais également pour les chercheurs et les analystes de données qui ont besoin d’accéder à des données géographiques précises.
Exploration des Fichiers de Base de Données
Nous avons réussi à créer une table contenant 249 enregistrements, avec un index unique associé à la colonne name.
Vérification des Fichiers
Jetons un coup d’œil à notre dossier base/ :
1
$ ls -l pg-data/base
2
drwx------ - 16388/
Il est évident que notre base de données blogdb a pour identifiant 16388. Si vous travaillez avec plusieurs bases de données sur le même cluster, il se peut que vous ne connaissiez pas ce numéro. Si vous suivez cet exemple chez vous, le numéro pourrait être différent. Pour le découvrir, exécutez la commande suivante :
1
postgres=# selectoid, datname from pg_database;
2
oid | datname
3
-------+-----------
4
5 | postgres
5
16388 | blogdb
6
1 | template1
7
4 | template0
8
(4rows)
Examinons maintenant le contenu de ce dossier :
1
$ cd pg-data/base/16388
2
$ ls -l .
3
.rw------- 8.2k 112
4
.rw------- 8.2k 113
5
.rw------- 8.2k 174
6
.rw------- 8.2k 175
7
.rw------- 8.2k 548
8
.rw------- 8.2k 549
9
.rw------- 0 826
10
.rw------- 8.2k 827
11
.rw------- 8.2k 828
12
.rw------- 123k 1247
13
.rw------- 25k 1247_fsm
14
.rw------- 8.2k 1247_vm
15
.rw------- 475k 1249
Exploration des Fichiers dans une Base de Données
Une Surprenante Abondance de Fichiers
Il est étonnant de constater qu’il existe un nombre considérable de fichiers, même si nous n’avons que 249 lignes. Qu’est-ce qui se passe réellement ?
Utilisation des Catalogues Systèmes
Pour mieux comprendre cette situation, nous pouvons nous appuyer sur plusieurs catalogues systèmes utiles :
Identification de l’Espace de Noms
Tout d’abord, il est essentiel de déterminer l’OID de l’espace de noms ‘public’ dans lequel se trouve notre table. Pour cela, il est nécessaire d’exécuter la commande dans la base de données ‘blogdb’, sinon vous obtiendrez l’OID de l’espace de noms ‘public’ de la base de données à laquelle vous êtes actuellement connecté.
SELECT to_regnamespace('public')::oid;
Cette commande renverra l’OID correspondant, qui est crucial pour les étapes suivantes.
Listing des Tables et Index
Ensuite, nous allons lister toutes les tables, index, et autres objets qui résident dans cet espace de noms. Voici la commande à exécuter :
SELECT * FROM pg_class WHERE relnamespace = to_regnamespace('public')::oid;
Cette requête nous fournira une vue d’ensemble des objets présents dans l’espace de noms ‘public’, incluant des informations telles que le nom de la relation, le type, le propriétaire, et bien d’autres attributs.
Analyse des Résultats
Les résultats de cette requête peuvent révéler des détails intéressants sur la structure de la base de données. Par exemple, vous pourriez découvrir des séquences, des tables, et des index qui sont tous essentiels pour le bon fonctionnement de votre base de données.
Conclusion
bien que le nombre de lignes puisse sembler limité, la richesse des fichiers et des objets dans une base de données peut être surprenante. En utilisant les catalogues systèmes, nous pouvons obtenir une compréhension approfondie de la structure et des composants de notre base de données, ce qui est essentiel pour une gestion efficace et une optimisation des performances.
Dans cette analyse, nous constatons que nous avons en réalité seulement quatre objets de type table ; le reste des fichiers dans ce dossier est constitué de modèles standards. Si vous examinez les dossiers de la base de données tels que template0, template1 ou postgres (c’est-à-dire 1/, 2/ ou 5/), vous remarquerez que presque tous les fichiers sont identiques à ceux de notre base de données blogdb.
Alors, que sont ces objets pg_class et quel est leur lien avec tous ces fichiers ?
Nous pouvons identifier que countries est présent avec des valeurs oid et relfilenode de 16390, ce qui correspond à notre table réelle. De plus, il y a countries_pkey avec des valeurs oid et relfilenode de 16395, qui représente l’index de notre clé primaire. Enfin, nous avons countries_name_key avec 16397, qui est l’index pour notre nom unique.
La contrainte ici est que countries_id_seq a une valeur de 16389, ce qui correspond à la séquence utilisée pour générer de nouveaux identifiants (nous utilisons primary key generated always as identity, qui, tout comme serial, produit de nouvelles valeurs dans une séquence numérique croissante).
Le relfilenode fait référence au « filenode » de l’objet, qui représente le nom du fichier sur le disque. Commençons par examiner notre table countries.
1
$ ls -l 16390*
2
.rw-------@ 33k 16390
3
.rw-------@ 25k 16390_fsm
Pour un objet général, vous êtes susceptible de voir trois fichiers ou plus : 3
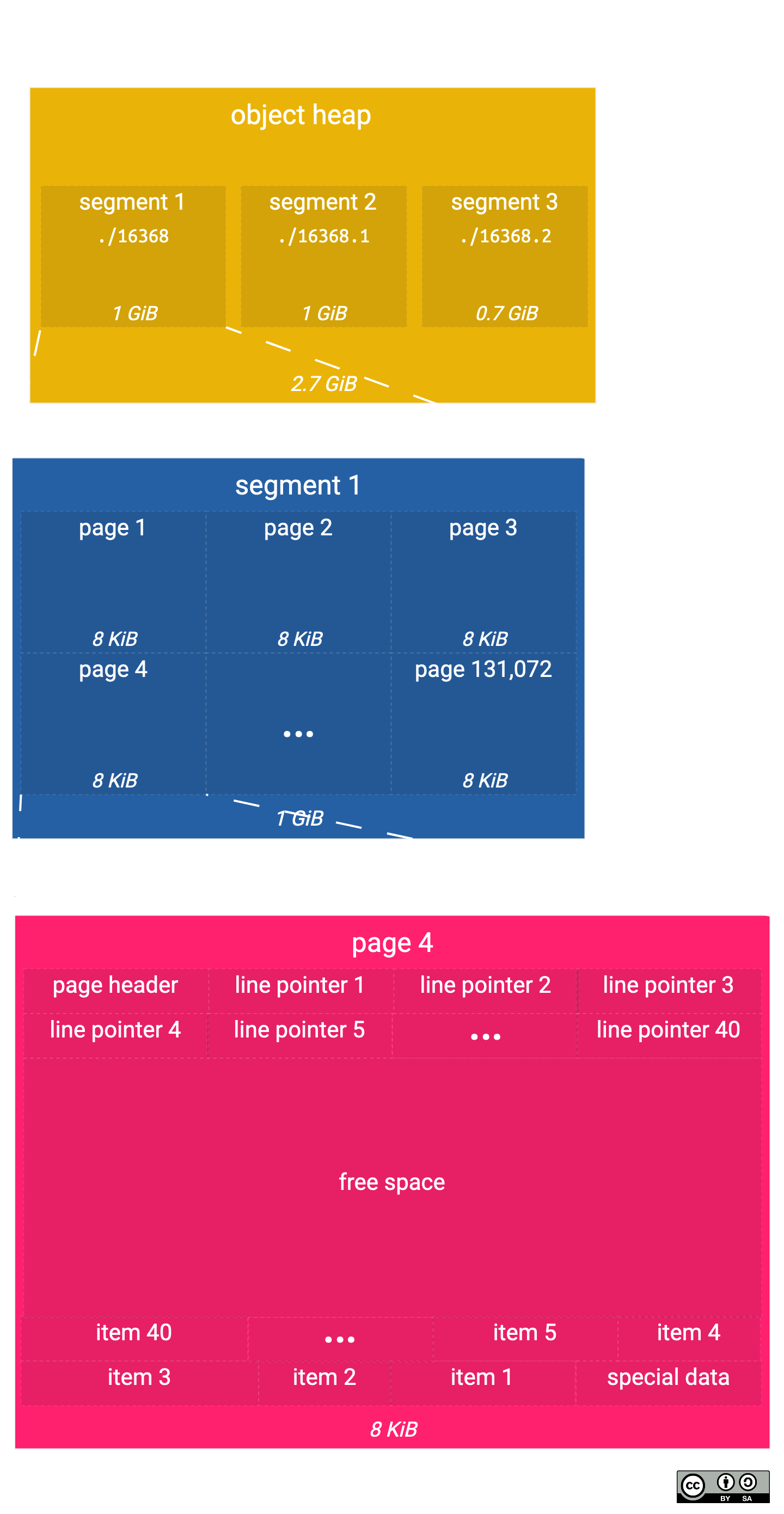
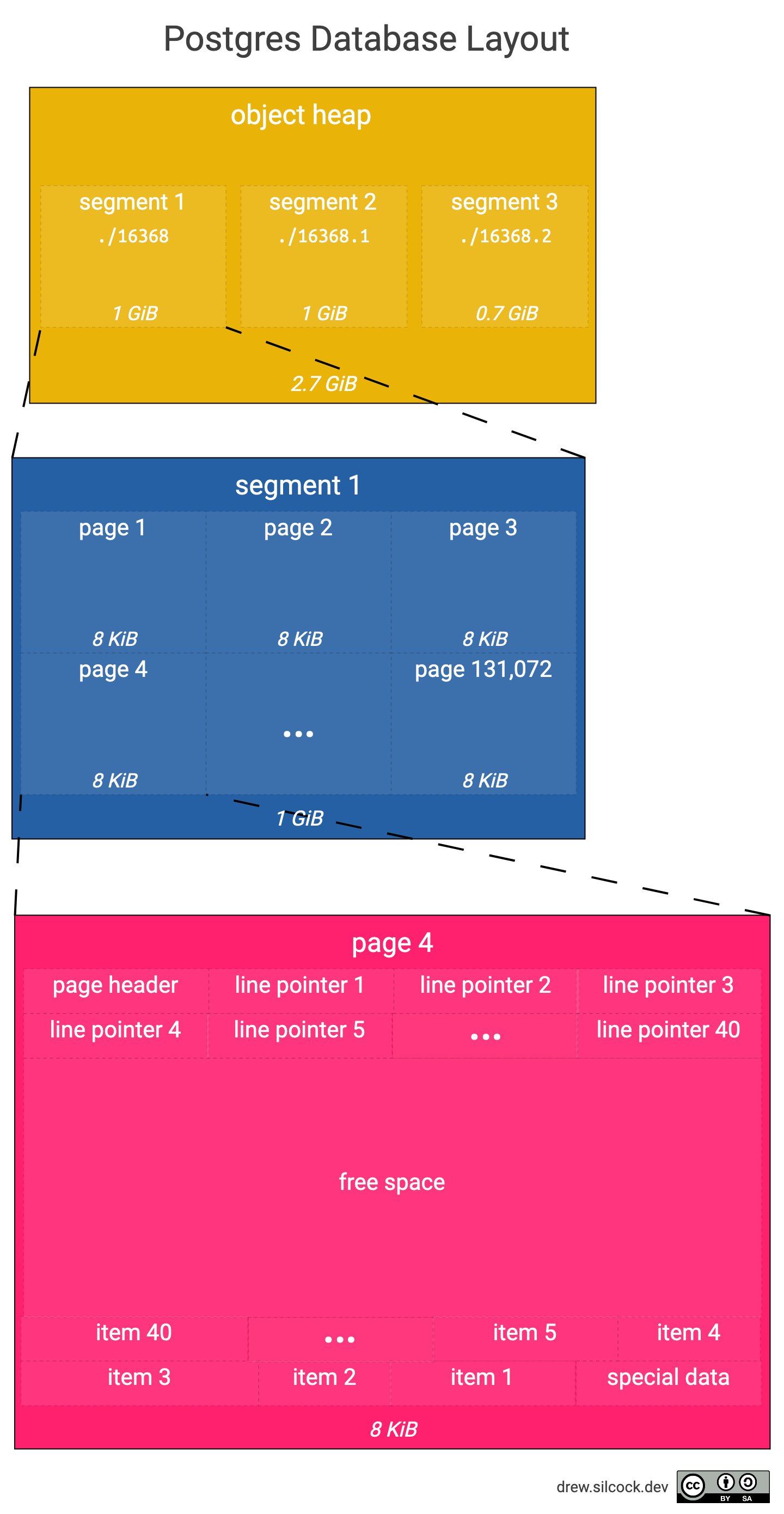
{filenode} – Postgres divise les grands objets en plusieurs fichiers appelés segments, afin d’éviter des problèmes que certains systèmes d’exploitation rencontrent avec les fichiers volumineux (principalement pour des raisons historiques). Par défaut, ces fichiers mesurent 1 Go, bien que cela soit configurable. C’est le premier fichier de segment.
{filenode}.1, {filenode}.2 – ce sont les fichiers de segment suivants. Nous n’avons pas encore plus de 1 Go de données, donc nous n’avons pas ces fichiers.
{filenode}_fsm – il s’agit du fichier de la carte d’espace libre (FSM) pour l’objet, qui contient un arbre binaire indiquant combien d’espace libre est disponible dans chaque page du tas. Ne vous inquiétez pas, nous allons expliquer exactement ce qu’est le tas et les pages dans un instant.
{filenode}_vm – c’est le fichier de la carte de visibilité (VM) pour l’objet, qui vous informe sur la visibilité des tuples dans vos pages. Nous aborderons cela plus en détail plus tard.
Qu’est-ce que le tas ?
Tous ces fichiers de données principaux (à l’exception des fichiers FSM et VM) sont appelés le tas.
Un aspect crucial des tables qui n’est pas évident au premier abord est que, même si elles peuvent avoir des clés primaires séquentielles, les tables ne sont pas ordonnées. (C’est pourquoi nous avons besoin d’un objet de séquence distinct pour produire les valeurs d’identifiant séquentielles.) Pour cette raison, les tables sont parfois appelées un sac de lignes. Postgres les désigne comme un tas. Pour toute table réelle qui est ajoutée, mise à jour et nettoyée, les lignes dans le tas ne seront pas dans l’ordre séquentiel de leur clé primaire.
Il est important de noter que le tas dans Postgres est très différent du tas en mémoire système (par opposition à la pile). Ce sont des concepts liés et si vous êtes familier avec la structure de la pile par rapport au tas en mémoire, vous pourriez trouver le diagramme de page dans la section suivante très familier, mais il est essentiel de se rappeler qu’il s’agit de concepts très distincts.
Le tas d’objet se compose de nombreuses pages différentes (également appelées blocs) stockées séquentiellement dans le fichier.
Alors, qu’est-ce qu’une page ?
Dans un fichier de segment unique, vous trouverez plusieurs pages de taille fixe assemblées. Par défaut, une page mesure 8 Ko, donc nous nous attendrions à ce que tous nos fichiers d’objet soient des multiples de 8 Ko. Dans ce cas, notre fichier de table fait 32 Ko, ce qui signifie qu’il doit contenir 4 pages.
Vous vous demandez peut-être – pourquoi utiliser des pages ? Pourquoi ne pas avoir une seule page par segment ? La réponse est que chaque page est écrite en une seule opération atomique et plus la taille de la page est grande, plus il y a de chances qu’il y ait un échec d’écriture pendant l’opération. Plus la taille de la page est élevée, plus la base de données sera performante, mais plus la probabilité d’échecs d’écriture sera élevée. Les responsables de Postgres ont choisi 8 Ko comme valeur par défaut, et ils savent ce qu’ils font, donc il n’y a généralement pas de raison de modifier cela.
Ce diagramme montre la structure d’une page et comment elle se rapporte au segment et à l’objet entier.
Dans notre exemple, notre table principale fait 2,7 GiB, ce qui nécessite 3 segments distincts de 1 GiB chacun. Cela représente 131 072 pages de 8 KiB dans 1 GiB, chaque page contenant environ 40 éléments (en supposant que chaque élément occupe environ 200 octets).
Mise en page des pages
Examinons de plus près la mise en page de notre page.
Vous pouvez voir qu’il y a trois zones dans la page :
Les en-têtes et pointeurs de ligne, qui croissent « vers le haut », ce qui signifie que le pointeur de ligne n + 1 a un décalage initial plus élevé dans la page que le pointeur de ligne n – la fin du dernier pointeur de ligne est appelée « inférieur ».
Les données spéciales et les éléments qui croissent « vers le bas », ce qui signifie que l’élément n + 1 a un décalage initial plus bas dans la page que l’élément n – la fin du dernier élément est appelée « supérieur ».
L’espace libre, qui se trouve entre le dernier pointeur de ligne et le dernier élément, c’est-à-dire qui va de « inférieur » à « supérieur » – vous pouvez calculer l’espace libre restant dans la page en faisant « supérieur » – « inférieur ».
L’en-tête de la page contient des informations telles que :
Un contrôle de somme de la page
Le décalage vers la fin des pointeurs de ligne (a.k.a. « inférieur »)
Le décalage vers la fin de l’espace libre (c’est-à-dire vers le début des éléments, a.k.a. « supérieur »)
Le décalage vers le début de l’espace spécial
Des informations de version
Il existe en fait une extension intégrée appelée pageinspect que nous pouvons utiliser pour examiner les informations de l’en-tête de notre page :
Analyse des Pages de Base de Données : Comprendre l'Espace Libre
Introduction à l'Espace Libre dans les Pages
Lors de l'examen des pages d'une base de données, un aspect crucial à considérer est l'espace libre disponible. Cet espace peut avoir un impact significatif sur la performance et l'efficacité des opérations de la base de données. Dans cet article, nous allons explorer les valeurs d'espace libre dans différentes pages et ce qu'elles révèlent sur la structure des données.
Détails des Pages et de l'Espace Libre
En analysant les pages, nous remarquons que la valeur de special est identique à celle de pagesize, ce qui indique qu'il n'existe pas de section de données spéciale pour cette page. Cette section est généralement réservée à d'autres types de pages, comme les index, où elle stocke des informations sur la structure de l'arbre binaire.
Comparaison des Valeurs d'Espace Libre
En examinant les valeurs lower et upper pour chaque page, nous pouvons tirer des conclusions sur l'espace libre :
Page 0 : 376 - 292 = 84 octets d'espace libre
Page 1 : 408 - 308 = 100 octets d'espace libre
Page 2 : 416 - 296 = 120 octets d'espace libre
Page 3 : 3288 - 196 = 3092 octets d'espace libre
Interprétation des Résultats
Ces résultats nous permettent de faire certaines déductions :
La taille moyenne des lignes dans notre table des pays est d'environ 100 octets, ce qui correspond à l'espace libre disponible dans les pages complètes.
L'espace libre dans la page 3 est particulièrement élevé, ce qui pourrait indiquer une faible utilisation de cette page ou une possibilité d'optimisation pour des insertions futures.
Conclusion
L'analyse de l'espace libre dans les pages d'une base de données est essentielle pour comprendre la structure et l'efficacité des données. En surveillant ces valeurs, les administrateurs de bases de données peuvent mieux gérer l'espace et optimiser les performances. Une gestion proactive de l'espace libre peut également aider à anticiper les besoins futurs en matière de stockage et à améliorer la réactivité des systèmes de gestion de bases de données.
Analyse des Données de Pages dans une Base de Données
Introduction à l'Inspection des Pages
L'examen des pages d'une base de données est essentiel pour comprendre la structure et l'efficacité des données stockées. En utilisant des fonctions spécifiques, nous pouvons obtenir des informations précieuses sur la taille des lignes et la disposition des données.
Vérification de la Taille des Lignes
Pour confirmer la taille des lignes dans une page de données, nous pouvons utiliser la fonction heap_page_items() fournie par l'extension pageinspect. Cette fonction permet d'extraire des informations détaillées sur les éléments présents dans une page spécifique d'une table.
Exemple de Requête SQL
Voici un exemple de requête SQL qui illustre comment utiliser cette fonction :
Les résultats de cette requête peuvent ressembler à ceci :
lp
lp_off
lp_len
t_ctid
t_data
1
8064
123
(1,1)
x440000002545...
2
7944
114
(1,2)
x450000001145...
3
7840
97
(1,3)
x460000001145...
4
7720
116
(1,4)
x470000001345...
5
7600
115
(1,5)
x480000001345...
6
7448
148
(1,6)
x490000003946...
7
7344
103
(1,7)
x4a0000001d46...
8
7248
89
(1,8)
x4b0000000b46...
9
7144
97
(1,9)
...
Ces données fournissent un aperçu de la manière dont les informations sont organisées dans la page de la table countries.
Conclusion
L'utilisation de la fonction heap_page_items() est un moyen efficace d'analyser la structure des données dans une base de données. En comprenant la taille et la disposition des lignes, les administrateurs de bases de données peuvent optimiser les performances et la gestion des données.
Comprendre les Détails des Données dans PostgreSQL
Introduction aux Identifiants de Tuple
Dans PostgreSQL, chaque élément de données est associé à un identifiant unique, connu sous le nom de ctid (Current Tuple ID). Ce dernier permet de localiser précisément un élément dans la base de données, en utilisant un format spécifique qui indique la page et l'index de l'élément au sein de cette page. Par exemple, un ctid de (1, 1) désigne le premier élément de la première page, bien que les pages soient indexées à partir de zéro.
Exploration des Données Stockées
Il est fascinant de constater que l'on peut accéder aux données brutes stockées dans PostgreSQL. Ces données sont représentées sous forme de chaînes hexadécimales, qui correspondent exactement aux octets enregistrés sur le disque. Pour illustrer cela, nous pouvons utiliser un script Python afin d'extraire et de visualiser ces données.
Extraction des Données avec Python
Voici un exemple de commande pour récupérer les données d'une table spécifique, en l'occurrence "countries", à partir de la première page :
Pour visualiser le contenu extrait, nous pouvons utiliser la commande suivante :
cat row_data.bin
Cela nous permet de voir les données sous une forme plus compréhensible, par exemple :
D%Guinée équatorialeGQ GNQ 226 ISO 3166-2:GQ Afrique 'Afrique subsaharienne' Afrique centrale
Conclusion
L'exploration des données dans PostgreSQL offre une perspective fascinante sur la manière dont les informations sont stockées et récupérées. Grâce à des outils comme Python et des commandes simples, il est possible d'accéder à des données brutes et de les interpréter, ce qui peut s'avérer extrêmement utile pour les développeurs et les analystes de données.
Exploration des Données de la Guinée Équatoriale
Introduction à la Guinée Équatoriale
La Guinée Équatoriale, un petit pays situé en Afrique centrale, est souvent méconnue. Avec une population d'environ 1,4 million d'habitants, elle se distingue par sa diversité culturelle et ses ressources naturelles abondantes, notamment le pétrole et le gaz. Ce pays insulaire, composé de plusieurs îles et d'une partie continentale, est un exemple fascinant de l'interaction entre l'environnement et le développement économique.
Données Démographiques et Géographiques
La Guinée Équatoriale est divisée en plusieurs régions, chacune ayant ses propres caractéristiques géographiques et culturelles. Le pays est principalement composé de deux grandes îles, Bioko et Annobón, ainsi que d'une partie continentale. En termes de classification régionale, la Guinée Équatoriale fait partie de l'Afrique subsaharienne, plus précisément de l'Afrique centrale.
Ressources Naturelles et Économie
L'économie de la Guinée Équatoriale repose largement sur l'exploitation de ses ressources naturelles. En effet, le pays est l'un des plus grands producteurs de pétrole d'Afrique, ce qui a considérablement influencé son développement économique. Selon les dernières statistiques, le secteur pétrolier représente environ 90 % des exportations du pays. Cependant, cette dépendance à l'égard des hydrocarbures pose des défis en matière de diversification économique.
Culture et Société
La culture de la Guinée Équatoriale est un mélange riche d'influences africaines et espagnoles, reflet de son histoire coloniale. Les langues officielles sont l'espagnol, le français et le portugais, ce qui témoigne de cette diversité. Les traditions locales, telles que la musique et la danse, jouent un rôle essentiel dans la vie quotidienne des habitants.
Défis Sociaux et Environnementaux
Malgré ses richesses, la Guinée Équatoriale fait face à des défis importants, notamment en matière de gouvernance et de droits de l'homme. Les inégalités économiques sont marquées, et une grande partie de la population vit dans la pauvreté. De plus, la déforestation et la dégradation de l'environnement sont des préoccupations croissantes, exacerbées par l'exploitation des ressources naturelles.
Conclusion
La Guinée Équatoriale est un pays aux multiples facettes, riche en ressources et en culture, mais confronté à des défis significatifs. Pour assurer un avenir durable, il est crucial que le pays diversifie son économie et améliore les conditions de vie de sa population. En mettant l'accent sur la durabilité et l'inclusion sociale, la Guinée Équatoriale peut aspirer à un développement équilibré et prospère.
0x 44 00 00 00 équivaut à 68 (doit être en little endian), donc les quatre premiers octets représentent l'ID de la ligne.
Ensuite, il y a un octet aléatoire comme 0x25 ou 0x07, suivi des données des colonnes – le reste des colonnes étant de type chaîne, elles sont toutes stockées en UTF-8. Si vous avez des informations sur la signification de ces octets inter-colonnes, n'hésitez pas à laisser un commentaire ! Je n'ai pas réussi à le déterminer.
Nous n'avons pas encore abordé le sujet de TOAST – ce sera un thème pour un prochain article 🍞.
Que se passe-t-il lorsqu'une ligne est modifiée ou supprimée ?
Postgres utilise le MVCC (Contrôle de Concurrence Multi-Version) pour gérer l'accès simultané aux données. Le terme "multi-version" signifie que lorsqu'une transaction modifie une ligne, elle ne touche pas du tout le tuple existant sur le disque. Au lieu de cela, elle crée un nouveau tuple à la fin de la dernière page avec la ligne modifiée. Lorsqu'elle valide la mise à jour, elle remplace la version des données que la nouvelle transaction verra, passant de l'ancien tuple au nouveau.
Illustrons cela avec un exemple :
1
blogdb=# select ctid from countries wherename='Antarctica';
2
ctid
3
-------
4
(0,9)
5
(1ligne)
6
7
blogdb=# update countries set region ='Le Pôle Sud'wherename='Antarctica';
8
MISE À JOUR1
9
10
blogdb=# select ctid from countries wherename='Antarctica';
blogdb-# from heap_page_items(get_raw_page('countries', 0))
18
blogdb-# offset 8limit1;
19
lp | lp_off | lp_len | t_ctid | t_data
20
----+--------+--------+--------+--------
21
9 | 0 | 0 | |
22
(1ligne)
Nous pouvons constater qu'après la mise à jour de la ligne, son ctid change de (0,9) à (3,44) (probablement à la fin de la dernière page). Les anciennes données et le ctid sont également supprimés de l'emplacement de l'ancien élément.
Qu'en est-il des suppressions ? Examinons cela :
1
blogdb=# deletefrom countries wherename='Guinée équatoriale';
blogdb-# from heap_page_items(get_raw_page('countries', 1))
6
Les données demeurent présentes ! Cela s'explique par le fait que Postgres ne supprime pas réellement les données, mais les marque simplement comme supprimées. Vous pourriez vous demander, si des lignes sont constamment supprimées et ajoutées, comment éviter l'accumulation de fichiers de segments remplis de données supprimées (appelées "tuples morts" dans le jargon de Postgres). C'est ici qu'intervient le processus de nettoyage, connu sous le nom de "vacuum". Voyons comment effectuer un nettoyage manuel et observer les résultats.
1. Exécutez la commande suivante :
VACUUM FULL;
Après avoir lancé le nettoyage, nous pouvons vérifier l'état des données. Utilisons la commande suivante pour examiner les éléments de la page de la table 'countries'.
2. Sélectionnez les informations pertinentes :
SELECT lp, lp_off, lp_len, t_ctid, t_data
FROM heap_page_items(get_raw_page('countries', 1))
LIMIT 1;
-- Cela correspondait auparavant au tuple mort où se trouvait 'Guinée équatoriale'.
Nous pouvons également vérifier d'autres données en utilisant une autre commande :
3. Pour explorer davantage, exécutez :
SELECT lp, lp_off, lp_len, t_ctid, t_data
FROM heap_page_items(get_raw_page('countries', 0))
OFFSET 8 LIMIT 1;
-- Cela correspondait auparavant au tuple mort de l'ancienne version de 'Antarctique'.
Les résultats de cette requête sont les suivants :
le processus de nettoyage est essentiel pour maintenir l'efficacité de la base de données en éliminant les tuples morts et en optimisant l'espace de stockage. Cela permet non seulement d'améliorer les performances, mais aussi de garantir l'intégrité des données au fil du temps.
Après avoir effectué un nettoyage, plusieurs changements se sont produits :
La ligne obsolète contenant l'ancienne version de l'entrée pour l'Antarctique a été remplacée par Antigua-et-Barbuda, le pays suivant dans l'ordre.
La ligne obsolète pour la Guinée équatoriale a été remplacée par l'Estonie, le pays suivant également.
L'Antarctique a été déplacé de (3,44) à (3,42) car les deux lignes obsolètes ont été supprimées, permettant ainsi à l'entrée de l'Antarctique de descendre de deux positions.
Les Indexes : Comment ça fonctionne ?
Les indexes fonctionnent de la même manière que les tables ! La seule différence réside dans le fait que les tuples stockés en tant qu'éléments dans chaque page contiennent les données indexées au lieu des données complètes de la ligne, et les données spéciales contiennent des informations sur les nœuds frères pour l'arbre binaire.
Exercice pour le lecteur : Trouvez le fichier de segment pour l'index unique de la colonne name et examinez les valeurs de t_data dans chaque élément ainsi que les "données spéciales" pour chaque page. Partagez vos découvertes dans les commentaires !
Pourquoi est-il important de connaître tout cela ?
Il y a plusieurs raisons à cela :
C'est fascinant !
Comprendre comment Postgres interroge vos données sur le disque, comment fonctionne le MVCC, et bien d'autres aspects utiles pour optimiser les performances de votre base de données.
Dans certaines situations rares, cela peut s'avérer utile pour la récupération de données. Voici quelques exemples :
Imaginons qu'une personne, par incompétence ou malveillance, décide de corrompre votre base de données en supprimant ou en altérant quelques fichiers sur le disque. Postgres ne peut plus comprendre la base de données, et son démarrage entraînera un état corrompu. Vous pourriez alors utiliser vos connaissances pour récupérer manuellement les données. Bien que cela soit une tâche complexe, dans un scénario hypothétique où votre entreprise ne peut pas se permettre un spécialiste de la récupération de données, vous pourriez être contraint de le faire vous-même.
Supposons qu'une table cruciale pour les clients ait été définie comme non journalisée dans la base de données de production, puis que le serveur plante. Étant donné que les modifications dans une table non journalisée ne sont pas écrites dans le WAL, une récupération via décodage logique n'inclura pas les données de cette table. Si vous redémarrez le serveur, Postgres effacera complètement la table non journalisée. Cependant, si vous copiez les fichiers bruts de la base de données, vous pourriez utiliser vos connaissances pour récupérer le contenu des données.
C'est un excellent sujet de conversation lors des soirées !
Lectures complémentaires
Ketan Singh – Comment Postgres stocke les lignes
Documentation PostgreSQL – Chapitre 73. Stockage physique de la base de données
SQL Avancé (Été 2020), U Tübingen – DB2 – Chapitre 03 – Vidéo #09 – Stockage des lignes dans PostgreSQL, disposition des pages de fichiers de tas
15-445/645 Introduction aux systèmes de bases de données (Automne 2019), Carnegie Mellon University – 03 - Stockage de base de données I
Structure de la table de tas dans PostgreSQL
pgPedia – Répertoire des données
Sujets futurs
Les moteurs de bases de données sont un sujet d'une grande richesse, et j'aimerais aborder encore beaucoup d'autres thèmes dans cette série. Voici quelques idées :
Comment Postgres gère les valeurs surdimensionnées – levons un TOAST
Comment Postgres gère la concurrence – le MVCC est le véritable MVP
Comment Postgres transforme une chaîne SQL en données
Comment Postgres garantit l'intégrité des données – où est le WAL ?
Si vous souhaitez que j'écrive sur l'un de ces sujets, n'hésitez pas à laisser un commentaire ci-dessous !
Comprendre l'Utilisation des Identifiants Numériques
Pourquoi Stocker des Identifiants en Tant qu'Entiers ?
Il est légitime de se demander pourquoi il est nécessaire de conserver un identifiant sous forme d'entier. En réalité, cet identifiant reste un code de trois caractères, mais il limite les caractères disponibles à ceux compris entre 0 et 9, contrairement aux codes de pays alpha-2 et alpha-3 qui utilisent des lettres de a à z.
Informations d'Initialisation pour les Tables Non Connectées
Un autre élément à considérer est le champ nommé {filenode}_init, qui sert à conserver des informations d'initialisation pour les tables non connectées. Toutefois, ces informations ne seront visibles que si vous travaillez avec des tables non connectées.
Signification du "C"
Il est probable que la lettre "C" ait une signification particulière, bien que son interprétation exacte puisse varier.
Erreurs Courantes en Développement
Il est facile de prétendre que l'on n'a jamais exécuté par inadvertance une requête sur la base de données de production au lieu de celle de développement locale. Cependant, cette situation arrive à tout le monde à un moment ou à un autre.
Comportements à Éviter en Réunions
Il est fortement déconseillé d'adopter certains comportements lors de réunions ou de rassemblements professionnels, car cela pourrait nuire à votre réputation et à vos futures invitations.
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !
Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Ne manquez pas cette offre incroyable : le Air Fryer Moulinex Easy Fry Max à -42% sur Amazon !
Les soldes d’hiver sont là ! Ne ratez pas l’incroyable offre d’Amazon sur le Moulinex Easy Fry Max, à seulement 69 euros au lieu de 119 euros, soit une réduction sensationnelle de -42% ! Avec sa capacité généreuse de 5 L, cette friteuse sans huile est idéale pour régaler jusqu’à 6 convives. Grâce à ses 10 programmes de cuisson et son interface tactile intuitive, préparez des plats sains et savoureux en un clin d’œil. Dépêchez-vous, les stocks s’épuisent vite et cette offre est limitée dans le temps !
Les soldes d’hiver sont en cours, et Amazon en profite pour offrir des promotions intéressantes, notamment sur les friteuses à air. Actuellement, le Moulinex Easy Fry Max est proposé à un prix attractif de 69 euros au lieu de 119 euros, ce qui représente une réduction immédiate de 42 %. C’est une occasion parfaite pour acquérir une friteuse sans huile XL d’une capacité généreuse de 5 L, idéale pour préparer des repas pour jusqu’à six personnes à un tarif très compétitif.
Étant donné que cette offre est limitée dans le temps,il est conseillé d’agir rapidement si vous souhaitez en bénéficier. De plus, avec un tel prix, les stocks pourraient s’épuiser rapidement. Ce modèle se classe parmi les meilleures ventes sur Amazon avec plus de 1000 unités écoulées le mois dernier.
Profitez des offres sur Amazon
Amazon propose également la livraison gratuite et rapide pour cet article qui bénéficie d’une garantie de deux ans. En outre, il existe une option de paiement échelonné en quatre fois sans frais sur ce modèle. Enfin, sachez que vous avez la possibilité de changer d’avis et retourner le produit gratuitement dans un délai de 30 jours afin d’obtenir un remboursement intégral.
Moulinex Easy Fry Max : cuisinez sainement pour toute la famille
Le moulinex Easy Fry Max fonctionne comme un four à air chaud permettant la préparation de plats savoureux tout en utilisant peu ou pas du tout d’huile. En plus des frites croustillantes qu’il réalise parfaitement, cet appareil se révèle très polyvalent et peut cuisiner une multitude d’autres recettes.
avec ses dix programmes prédéfinis adaptés à divers ingrédients tels que poulet,steak,poisson ou légumes ainsi que des options pour bacon et desserts comme les pizzas ,cet appareil répond aux besoins variés des familles modernes. De plus, Moulinex met à disposition un livre numérique rempli de recettes accessible via QR Code afin que vous puissiez facilement trouver l’inspiration culinaire lorsque nécessaire.
Sa capacité généreuse permet non seulement la préparation rapide mais aussi économique : jusqu’à 70 % moins énergivore et presque deux fois plus rapide qu’un four traditionnel ! Son interface intuitive avec écran tactile facilite son utilisation quotidienne.
en outre, le panier antiadhésif compatible lave-vaisselle simplifie grandement l’entretien après chaque utilisation. N’oubliez pas qu’il s’agit là encore d’une offre temporaire ; ne tardez donc pas si vous souhaitez profiter du meilleur prix possible sur cette friteuse innovante !
TikTok revient en force aux États-Unis, mais pas sur l’App Store !
Le suspense autour de TikTok est à son comble ! En avril 2024, le Congrès américain a voté une loi obligeant l’application à changer de propriétaire avant le 19 janvier. Les utilisateurs ont anxieusement attendu la décision finale. Bien que TikTok ait brièvement cessé ses activités, elle est revenue en ligne, mais absente de l’App Store. Apple justifie cette décision par des obligations légales. Cependant, les utilisateurs peuvent toujours accéder à leur compte… sans mises à jour. L’avenir de TikTok pourrait prendre un tournant décisif avec les promesses du nouveau président.
En avril 2024, le Congrès américain a adopté une législation obligeant TikTok à trouver un nouvel acquéreur, ByteDance étant accusé d’activités d’espionnage. Les utilisateurs de l’submission aux États-Unis ont donc attendu avec impatience le week-end précédent la date limite du 19 janvier pour savoir si TikTok serait interdit dans le pays.
Bien que TikTok n’ait pas réussi à dénicher un repreneur avant cette échéance, l’application a temporairement suspendu ses activités… mais seulement pour quelques heures. le réseau social est désormais de retour en ligne, mais il n’est plus accessible sur l’App Store.
Retour de TikTok : Une Absence Persistante sur l’App Store
Apple a expliqué sa décision de retirer TikTok de son App store par un communiqué officiel. « Apple doit respecter les lois en vigueur dans les régions où elle opère. Selon la loi Protecting Americans from Foreign Adversary Controlled Applications act, les applications développées par ByteDance ltd., y compris TikTok et ses filiales comme CapCut et Lemon8, ne pourront plus être téléchargées ou mises à jour sur l’App Store pour les utilisateurs américains après le 19 janvier 2025 », précise la société.
Il est crucial de souligner que les utilisateurs américains ayant déjà installé TikTok peuvent toujours accéder au service. Cependant, ils ne recevront plus aucune mise à jour future de l’application. L’avenir du réseau social pourrait dépendre des décisions du nouveau président des États-Unis.
DÉCLARATION DE TIKTOK :
>
En collaboration avec nos partenaires techniques, nous travaillons activement à rétablir notre service. Nous remercions le président Trump pour avoir clarifié la situation et rassuré nos partenaires qu’ils ne subiront aucune sanction en continuant d’offrir TikTok aux plus de 170 millions d’utilisateurs…
Le successeur de Joe Biden sera investi comme président ce lundi 20 janvier et prévoit d’émettre un décret afin d’accorder un délai supplémentaire à TikTok pour trouver un acquéreur potentiel.Donald Trump propose même que les États-Unis détiennent une participation significative dans cette application.
« Je souhaite que les États-Unis possèdent une part importante dans une coentreprise avec cet outil numérique afin que nous puissions préserver son intégrité tout en lui permettant d’évoluer […]. Ainsi,notre pays détiendrait la moitié des parts dans une coentreprise établie entre nous et tout acheteur sélectionné »,a déclaré Donald Trump.
L’avenir immédiat de TikTok pourrait donc connaître des évolutions majeures très prochainement. Il convient également de noter qu’une rumeur circulait selon laquelle Elon Musk envisagerait d’acquérir des parts dans la plateforme,mais celle-ci a été rapidement démentie par un porte-parole officiel.













 Technologie1 an ago
Technologie1 an ago
 Général1 an ago
Général1 an ago


 Business1 an ago
Business1 an ago
 Science et nature1 an ago
Science et nature1 an ago