Technologie
Analyse des sentiments des publications Hacker News : Plongée dans l’évolution entre janvier 2020 et juin 2023 !
Découvrez notre analyse fascinante des publications sur Hacker News ! Entre janvier 2020 et juin 2023, nous avons exploré 100 000 posts et leurs commentaires grâce à LLama3 70B LLM. Quels sujets suscitent le plus d’engagement ? Notre outil interactif vous permet d’explorer les émotions derrière chaque thème, révélant ainsi les passions et les controverses de la communauté. Plongez dans les données et découvrez ce que la communauté adore ou déteste. Les résultats pourraient vous surprendre !

Technologie
Résumé
Nous avons examiné tous les articles de Hacker News ayant reçu plus de cinq commentaires entre janvier 2020 et juin 2023. En utilisant le modèle de langage LLama3 70B, nous avons analysé les publications et leurs commentaires associés pour mieux comprendre comment la communauté de Hacker News interagit avec divers sujets. Vous pouvez télécharger les ensembles de données que nous avons produits à la fin de cet article.
Utilisez l’outil ci-dessous pour explorer différents sujets et les sentiments qu’ils suscitent. La colonne des sentiments indique le score médian, où 0 représente le sentiment le plus négatif et 9 le plus positif. Cliquez sur les en-têtes de colonne pour découvrir les sujets qui provoquent des réactions fortes, qu’elles soient positives ou négatives, et pour identifier les thèmes controversés qui tendent à générer des commentaires polarisés.
Motivation
Si vous suivez Hacker News depuis un certain temps, vous avez probablement développé une intuition sur les sujets que la communauté apprécie et ceux qu’elle déteste. Par exemple, si vous parvenez à porter Factorio sur ZX Spectrum en utilisant Rust, vous serez inondé d’amour et de karma. En revanche, si vous vendez votre startup à une société de capital-investissement au lieu de lever des fonds, vous risquez de devoir enfiler un costume en asbestos, car cela pourrait susciter des réactions négatives.
Cependant, cette intuition reste floue ! Étant donné que la communauté valorise la rationalité et la science des données (bien que cette expression soit elle-même sujette à controverse), il serait plus judicieux de soutenir nos impressions par une analyse de données rigoureuse.
De plus, cela nous donnerait l’occasion d’expérimenter avec des modèles de langage avancés, qui, malgré tout le battage médiatique autour de l’IA, se révèlent incroyablement efficaces pour des tâches pratiques comme celle-ci. Nous sommes également les développeurs d’un outil open source, Metaflow, écrit en Python, ce qui rend le processus d’exploration de projets comme celui-ci à la fois amusant et éducatif.
Quels sujets sont populaires sur Hacker News ?
Comme expliqué dans la section de mise en œuvre ci-dessous, nous avons téléchargé environ 100 000 pages publiées sur Hacker News pour comprendre quel contenu résonne avec la communauté. Nous nous concentrons sur les publications ayant obtenu au moins 20 votes positifs et 5 commentaires, en demandant à un modèle de langage de générer dix phrases décrivant le mieux chaque page.
Voici les 20 sujets les plus populaires, agrégés à partir des 100 000 pages, ainsi que le nombre de publications traitant de chaque sujet :
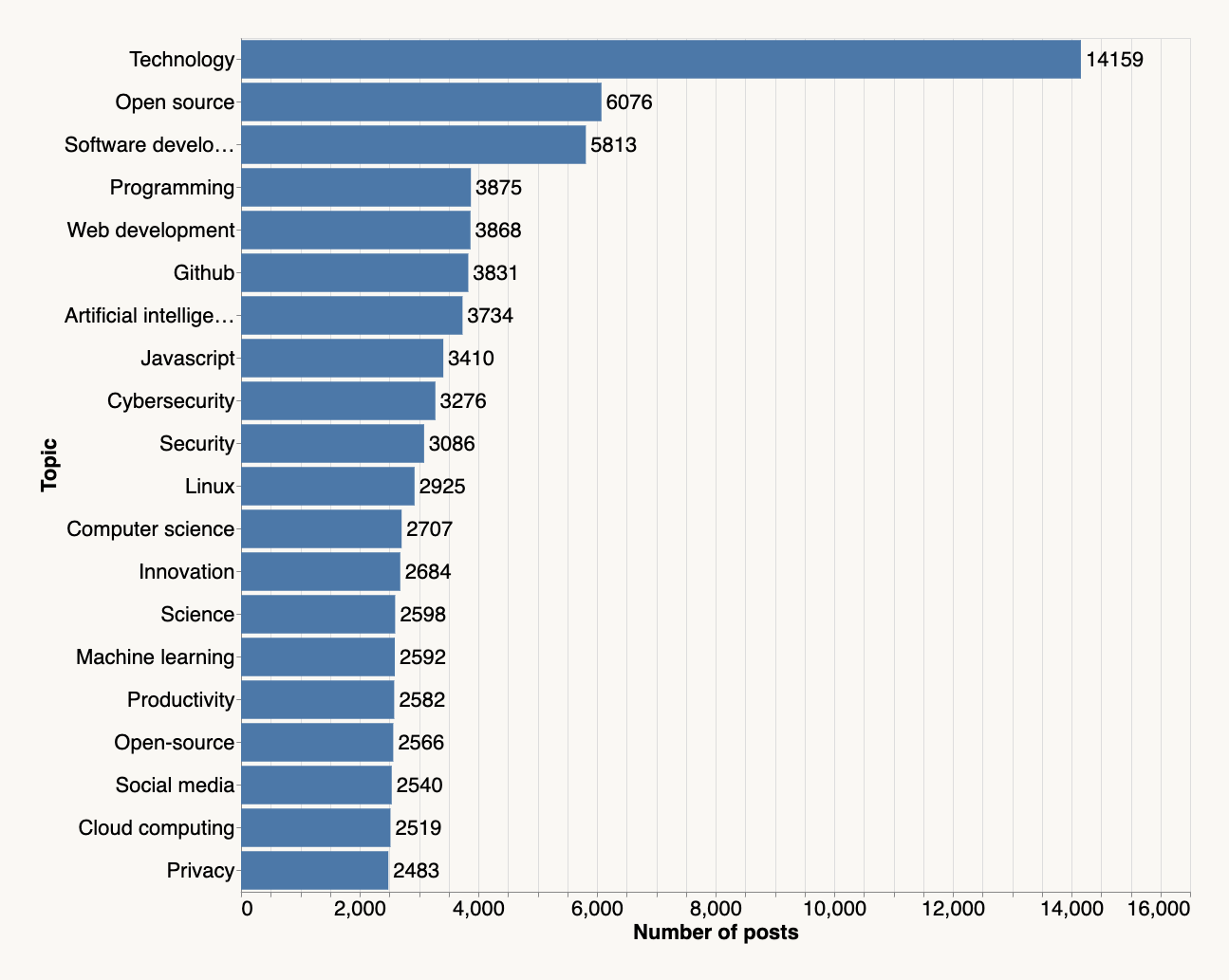
Les sujets les plus en vogue ne sont guère surprenants. Cependant, la communauté est connue pour ses intérêts intellectuels variés. Les 20 sujets principaux ne représentent que 10 % des thèmes abordés dans les publications. Vous pouvez le constater par vous-même en utilisant l’outil ci-dessus, qui couvre tous les 14 000 sujets associés à au moins cinq publications.
Les sujets populaires ont-ils évolué au fil du temps ? Absolument. Voici les 10 sujets en forte croissance :
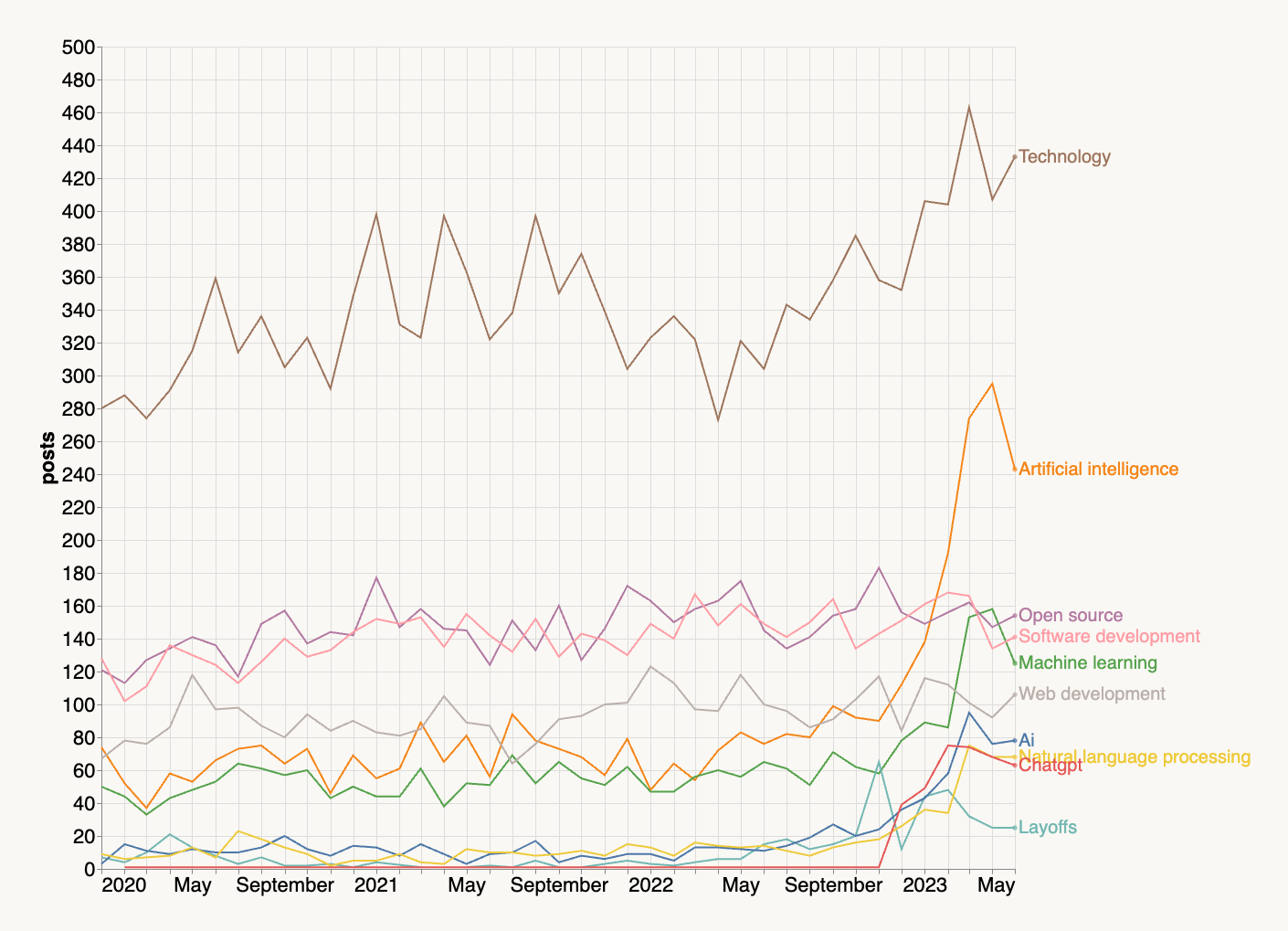
Bien que l’ensemble de données ne s’étende que jusqu’en juin 2023, nous observons une montée en puissance des articles sur l’IA, le traitement du langage naturel et des sujets connexes. Malheureusement, les licenciements ont également commencé à devenir un sujet tendance à partir de la mi-2022. L’essor des articles sur l’IA explique probablement la croissance du sujet Technologie.
Sujets en déclin
Entre 2020 et 2022, une tendance macro-économique majeure était tout ce qui concernait la pandémie de COVID, qui, heureusement, n’est plus un problème pressant. De manière fascinante, août 2021 a été un mois tumultueux, notamment avec la proposition d’Apple concernant le scannage CSAM, qui a provoqué une tempête de réactions sur les sujets liés à la vie privée et à Apple.
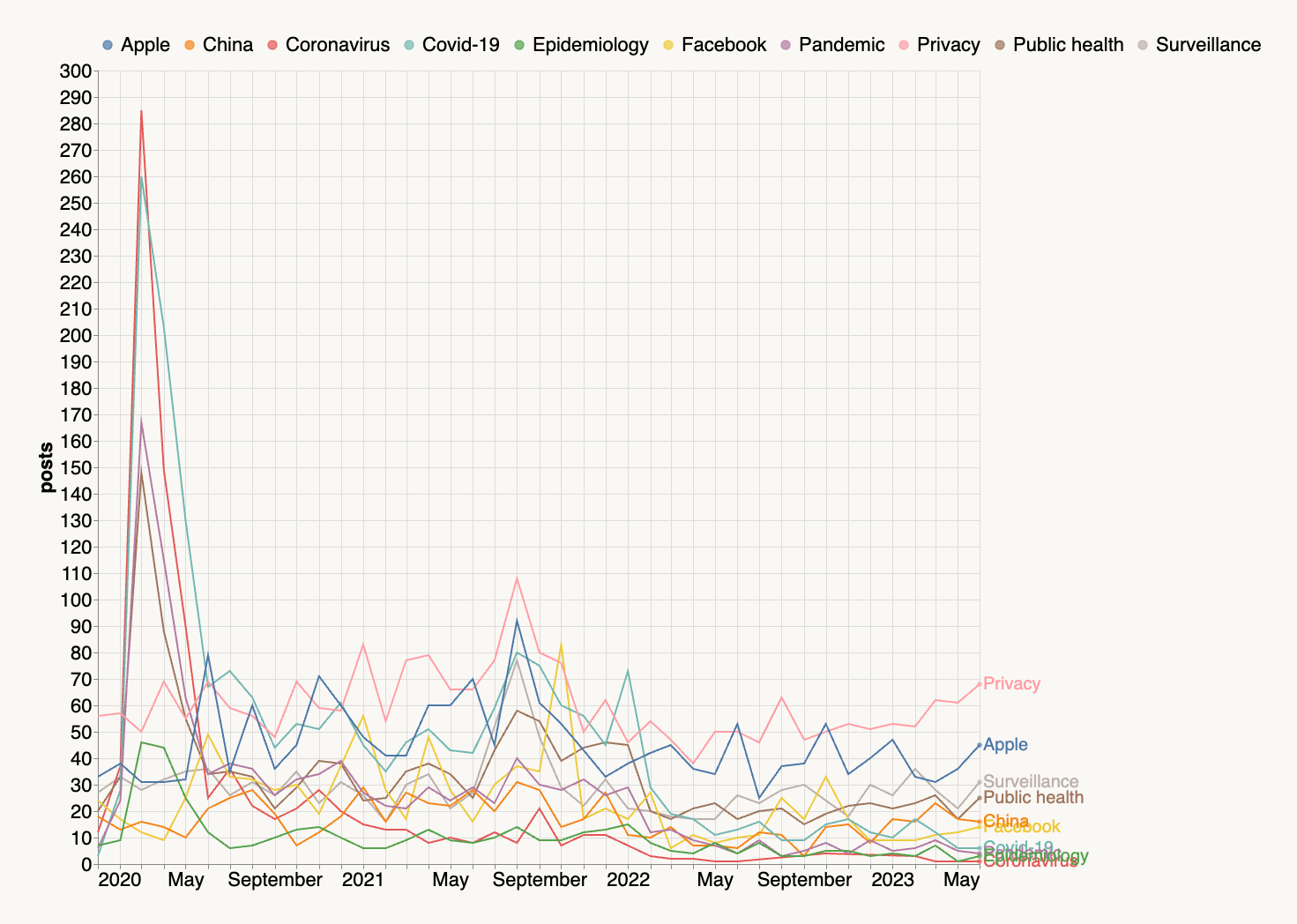
Pour un retour en arrière, considérez les sujets passés à gauche qui n’ont pas été abordés depuis janvier 2022 :
| Avant janvier 2022 | Après janvier 2022 |
|---|---|
| George Floyd | GPT-4 |
| Immunité collective | Diffusion stable |
| Anticorps | Guerre Russie-Ukraine |
| iOS 14 | Ventura |
| Freenode | Échec bancaire |
| Canal de Suez | Midjourney |
| Wallstreetbets | Gel des embauches |
| Hydroxychloroquine | Alliance FIDO |
| Taux d’infection | Crise du coût de la vie |
Les sujets à droite n’existaient pas avant janvier 2022. Il n’est pas nécessaire d’être économiste pour comprendre comment Wallstreetbets a été remplacé par la crise du coût de la vie, le gel des embauches et l’échec bancaire.
Mais comment les gens se sentent-ils à propos de ces sujets ?
Il est essentiel de noter que partager ou voter pour un article ne signifie pas nécessairement l’approuver – souvent, c’est même l’inverse. Pour vraiment comprendre la dynamique d’une communauté, nous devons analyser comment les gens réagissent aux publications, comme l’expriment leurs commentaires.
Pour ce faire, nous avons reconstruit les fils de commentaires associés aux publications de l’ensemble de données et demandé à un modèle de langage de classer le sentiment des échanges sur une échelle de 0 à 9, où zéro représente une guerre de flammes totale et neuf indique une harmonie parfaite et un sentiment positif.
Notre modèle de langage a agi comme un modérateur virtuel de la communauté et a parcouru 100 000 fils de commentaires en environ 9 heures, lisant 230 millions de mots reflétant toute la gamme émotionnelle, de l’amertume à la passion, en passant par la sagesse, l’humour et l’amour.
Voici ce que le modèle a révélé en termes de distribution des sentiments :
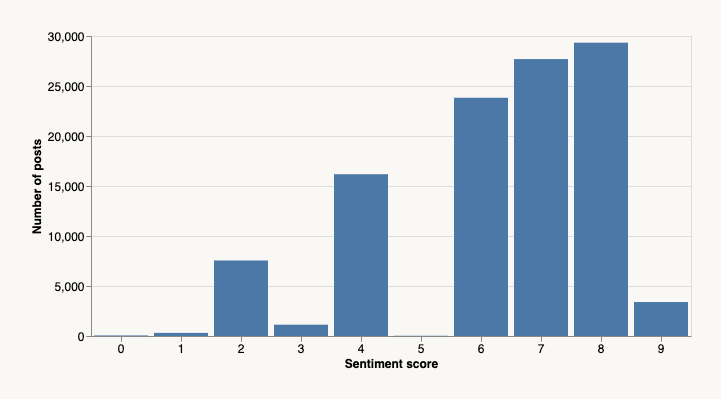
Premièrement, le modèle semble totalement perplexe quant à ce qu’est une discussion neutre – il n’y a pas de score de 5 dans les résultats. Ou peut-être est-ce une note sarcastique du modèle, soulignant que les humains sont incapables de discours émotionnellement neutres et impartiaux.
Deuxièmement, les sentiments sont clairement biaisés vers le positif, ce qui correspond à notre expérience personnelle avec le site. Ce penchant pour la positivité et l’optimisme est une des raisons pour lesquelles nous consultons Hacker News chaque jour. Il y a suffisamment de vitriol ailleurs.
Il convient également de noter que certains des scores attribués par la machine semblent douteux. Par exemple, cette publication de BentoML a reçu un score de un, bien que le sentiment semble majoritairement positif et encourageant. Toutes les réserves habituelles concernant les modèles de langage s’appliquent.
Avec les sujets et les scores de sentiment à notre disposition, nous pouvons enfin apporter une réponse scientifique à la question de ce que la communauté apprécie et ce qu’elle déteste :
| Aimer 😍 | Détester 😠 |
|---|---|
| Programmation | FTX |
| Informatique | Conduite policière abusive |
| Open Source | Sam Bankman-Fried |
| Python | Xinjiang |
| Développement de jeux | Torture |
| Rust | Surveillance des employés |
| Électronique | Réduction des coûts |
| Mathématiques | Profilage racial |
| Programmation fonctionnelle | Projet de loi sur la sécurité en ligne |
| Langage de programmation | Guerre contre le terrorisme |
| Physique | Atlassian |
| Systèmes embarqués | CSAM |
| Amélioration personnelle | NYPD |
| Base de données | Alameda Research |
| Unix | Étudiants internationaux |
| Astronomie | TSA |
| Informatique rétro | Earn It Act |
| Nostalgie | Fonctionnalités des voitures |
| Débogage | Bloatware |
Les passionnés de technologie, les geeks et les hackers devraient se sentir chez eux ! Il est intéressant de noter que, bien que la communauté soit généralement visionnaire et tournée vers l’avenir (en ce qui concerne les questions techniques, du moins), elle a indéniablement un faible pour la nostalgie technique. Bien que le monde moderne soit incroyable, nous avons une certaine nostalgie pour des éléments comme le ZX Spectrum, l’assemblage Z80 et l’8086. Au moins, nous trouvons un certain réconfort dans le PICO-8.
Du côté des sujets qui suscitent la colère, la plupart n’ont pas besoin d’explication. Il convient de préciser que Hacker News ne déteste pas les étudiants internationaux, mais que les publications les concernant tendent à être largement négatives, reflétant la sympathie de la communauté pour les défis rencontrés par ceux qui étudient à l’étranger.
De manière comique, Hacker News n’est pas une communauté de passionnés de voitures. Lorsque nous parlons de voitures, c’est généralement parce qu’il y a un problème. Pour plus d’analyses de ce type, utilisez l’outil en haut de la page pour explorer en détail le paysage diversifié des sujets de HN.
Certains sujets sont simplement divisifs
En plus des sujets qui suscitent uniquement l’amour ou la haine, certains sont bimodaux : parfois, une publication sur le sujet génère une réponse très positive, d’autres fois, elle déclenche une guerre de flammes. Voici quelques exemples :
- GNOME – La rivalité KDE contre GNOME dure depuis 25 ans.
- Google – Une force dominante sur Internet, tant pour le meilleur que pour le pire.
- Réglementations gouvernementales – Damné si vous le faites, damné si vous ne le faites pas.
- Capital-risque – Le nerf de la guerre de la Silicon Valley et une source de potins sans fin.
Pour en voir plus, triez par la colonne divisif dans l’outil ci-dessus. Pour qu’un sujet soit bien classé selon le score de divisivité, il doit être associé à des publications à la fois négatives et positives, et peu de publications neutres.
L’humeur s’améliore-t-elle ?
À l’écoute de la loi de Betteridge.
Nous pouvons tracer le sentiment moyen au fil du temps, tel qu’il est exprimé dans les fils de commentaires quotidiens :
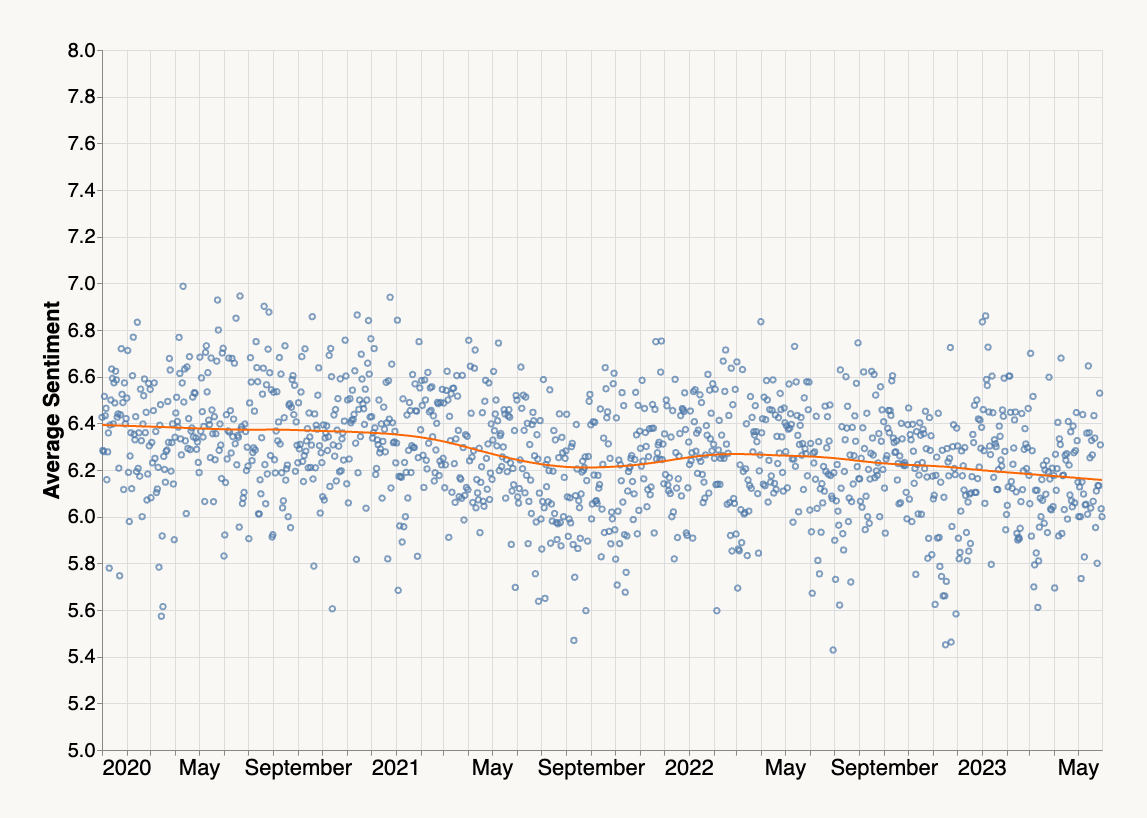
Les données montrent que les choses étaient difficiles en août 2021 (ou peut-être était-ce juste le fiasco d’Apple mis en avant dans le graphique ci-dessus). Dans l’ensemble, il existe une tendance claire mais modeste à la baisse du sentiment moyen.
Une analyse plus approfondie serait nécessaire pour comprendre pourquoi cela est le cas. En mettant de côté l’hypothèse évidente selon laquelle la vie devient simplement plus difficile (ce qui pourrait ne pas être vrai), une autre hypothèse pourrait être une variante de l’Eternal September. Il faut un effort conscient et inlassable pour maintenir une humeur positive dans une communauté en croissance. Bravo aux modérateurs de HN pour avoir maintenu la communauté dynamique et positive au fil des ans !
Mise en œuvre
Une raison d’être enthousiaste et optimiste pour l’avenir est l’existence même de cet article. Bien que le traitement du langage naturel et l’analyse de sentiment existent depuis des décennies, la qualité, la polyvalence et la facilité d’utilisation offertes par les LLMs sont sans précédent.
Atteindre la qualité des sujets et des scores de sentiment avec un ensemble de données désordonné comme celui-ci aurait nécessité un effort équivalent à une thèse de doctorat il y a quelques années – et les résultats auraient très probablement été moins bons. En revanche, nous avons développé tout le code pour cet article en environ sept heures. Traiter 350 millions de tokens avec un modèle de taille décente aurait nécessité un superordinateur il y a une décennie, alors que dans notre cas, cela a pris environ 16 heures avec du matériel largement disponible.
Le plus incroyable, c’est que tous les éléments de base, y compris les LLMs, sont disponibles en open source ! Faisons un rapide aperçu (avec code et données), montrant comment vous pouvez répéter l’expérience chez vous.
Voici ce que nous avons fait à un niveau élevé :
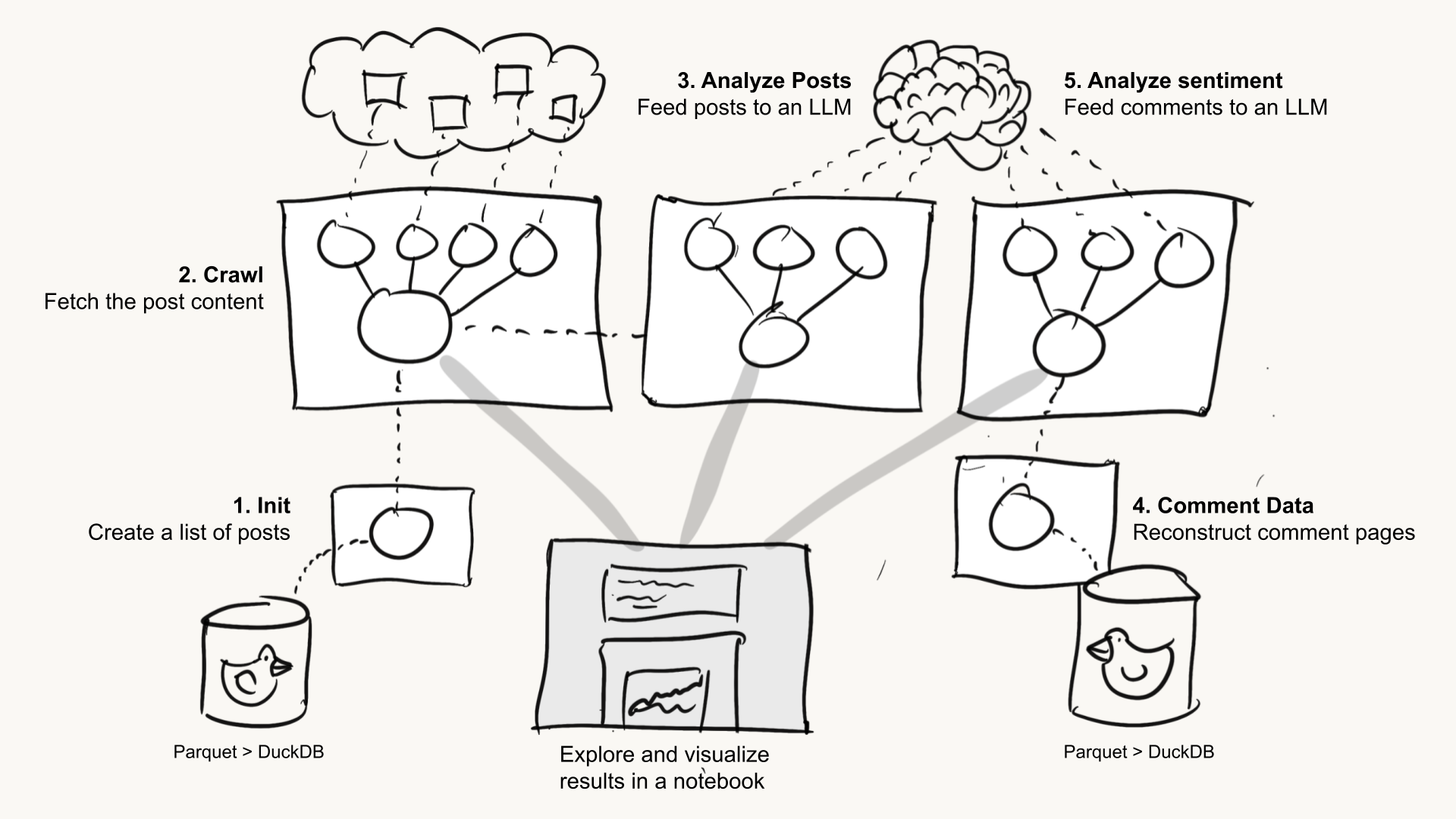
Chaque boîte blanche sur l’image représente un flux Metaflow, lié ci-dessous :
HNSentimentInitcrée une liste de publications à analyser.HNSentimentCrawltélécharge les publications.HNSentimentAnalyzePostsanalyse les publications et les traite avec un LLM.HNSentimentCommentDatareconstruit les fils de commentaires à partir d’un ensemble de données Hacker News dans Google BigQuery. Nous aurions dû/pourrions avoir utilisé cela dans l’étape (1) aussi. La prochaine fois !HNSentimentAnalyzeCommentstraite les fils de commentaires avec un LLM.- Les analyses de données et les graphiques présentés ci-dessus sont produits dans des notebooks (la boîte grise sur l’image).
Voici ce que font les flux :
Téléchargement des publications
Tout d’abord, nous voulions analyser les sujets abordés par les publications de Hacker News qui ont généré des discussions. En utilisant un ensemble de données de publications HN disponible publiquement (merci Julien !), nous avons interrogé toutes les publications entre janvier 2020 et juin 2023 (la date la plus récente disponible dans cet ensemble de données) qui avaient au moins 20 votes positifs et plus de cinq commentaires, ce qui a donné environ 100 000 publications. Voici le flux Metaflow simple qui a fait le travail, grâce à DuckDB.
Étant donné que les 100 000 publications proviennent principalement de différents domaines, nous pouvons les télécharger en parallèle sans surcharger les serveurs. Cela n’a pris qu’environ 25 minutes pour télécharger les pages avec 100 travailleurs parallèles (voir ici comment).
Compréhension documentaire à grande échelle avec les LLMs
Analyser le contenu textuel de pages HTML aléatoires était autrefois un véritable casse-tête, mais BeautifulSoup rend cela remarquablement simple.
À ce stade, nous avons un ensemble de données relativement propre d’environ 100 000 documents textuels avec plus de 500 millions de tokens au total. Traiter l’ensemble de données une fois avec un LLM à la pointe de la technologie, par exemple, GPT-4o ou Llama3 70b sur AWS Bedrock.
Le coût d’utilisation de l’API ChatGPT en mode batch s’élève à environ 1 300 dollars, sans compter les tokens de sortie. Au-delà des coûts, la rapidité est essentielle ; nous souhaitons traiter le jeu de données le plus rapidement possible afin d’évaluer les résultats et de procéder à des ajustements si nécessaire. Par conséquent, nous voulons éviter d’être limités par le taux d’utilisation ou d’autres goulets d’étranglement liés aux API.
Nous avons précédemment partagé notre expérience positive avec les microservices NVIDIA NIM, qui offrent une bibliothèque en pleine expansion de modèles LLM et d’autres modèles GenAI sous forme d’images préemballées, entièrement optimisées pour tirer parti de vLLM, TensorRT-LLM et Triton Inference Server. Cela nous évite de perdre du temps à rechercher les dernières astuces en matière d’inférence LLM.
Étant donné que nous avions intégré les NIM dans notre déploiement Outerbounds, nous avons simplement ajouté @nim à notre flux pour accéder à un point de terminaison LLM à haut débit, dont le coût est uniquement lié aux GPU auto-scalables sur lesquels il fonctionne, dans ce cas, quatre GPU H100. Bien sûr, vous pouvez choisir n’importe quel point de terminaison LLM selon vos préférences, les options étant nombreuses aujourd’hui.
Génération de sujets pour chaque article avec un LLM
Notre demande est simple :
Attribuez 10 étiquettes qui décrivent le mieux l'article suivant.
Répondez uniquement avec les étiquettes dans le format suivant :
1. première étiquette
2. deuxième étiquette
N. N-ième étiquette
---
[Premiers 5000 tokens d'une page web]Le modèle llama3 70b que nous avons utilisé dispose d’une fenêtre de contexte de 8 000 tokens, mais nous avons décidé de limiter le nombre de tokens à 5 000 pour tenir compte des différences de comportement du tokenizer, afin de ne pas dépasser la limite.
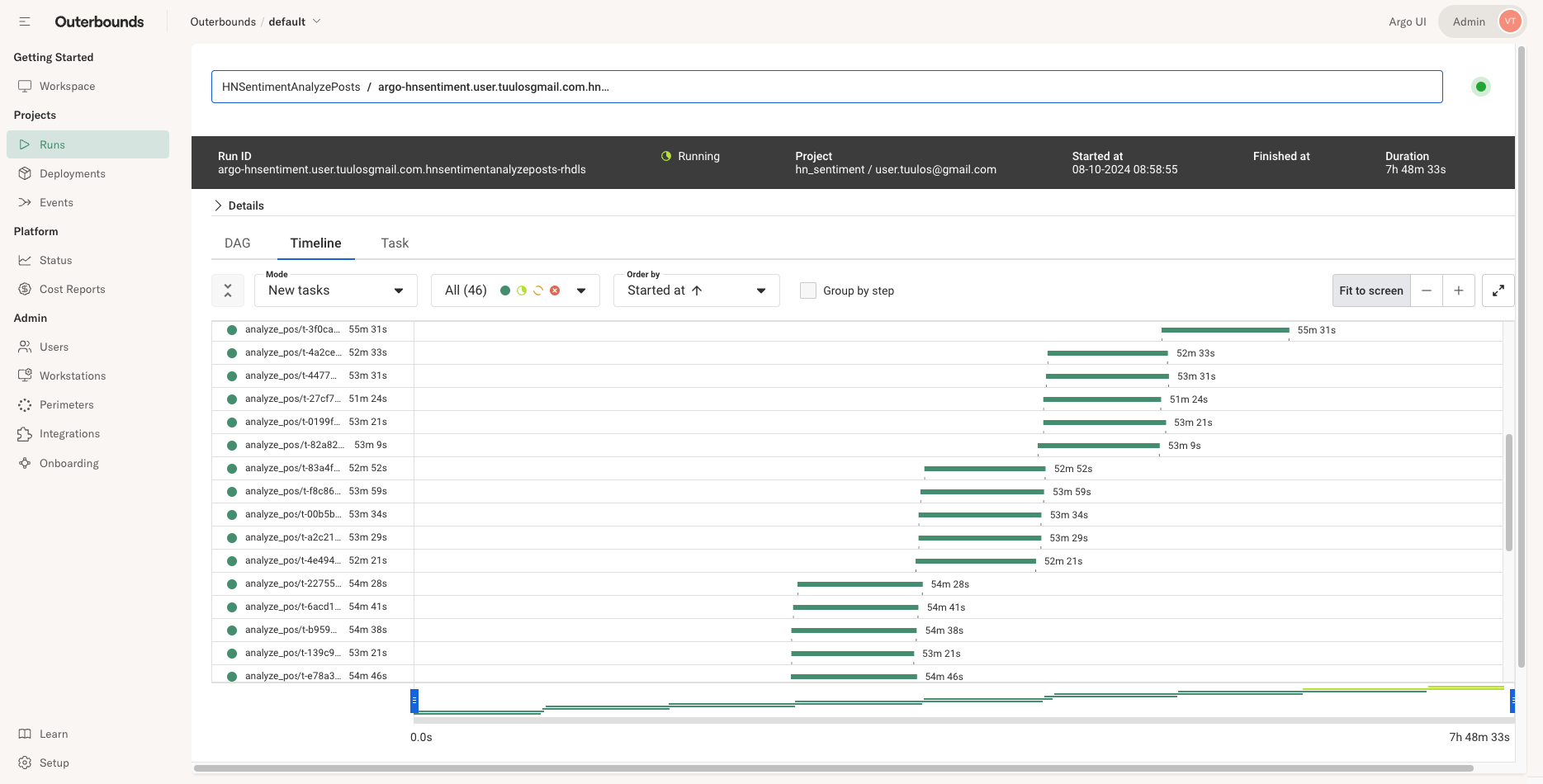
Le traitement d’environ 140 millions de tokens d’entrée de cette manière a pris environ 9 heures. Nous avons réussi à augmenter le débit à environ 4 300 tokens d’entrée par seconde en interrogeant le modèle simultanément avec cinq travailleurs, comme le montre notre interface utilisateur ci-dessous, afin de profiter du batching dynamique et d’autres optimisations.
Au lieu de tenter de télécharger directement 100 000 pages de commentaires depuis Hacker News, nous avons utilisé un ensemble de données Hacker News dans Google BigQuery. Malheureusement, les commentaires dans la base de données ne sont pas directement associés à leur article parent, ce qui nous a obligés à mettre en œuvre une petite fonction pour reconstruire les fils de commentaires.
Nous ne pouvons pas exécuter la fonction directement avec BigQuery, mais heureusement, nous pouvons facilement exporter les données au format Parquet. Charger les 16 millions de lignes résultantes dans DuckDB et les parcourir a été un jeu d’enfant, facilité par le fait que Metaflow sait comment charger les données rapidement. Nous avons simplement ajouté @resources(disk=10000, cpu=8, memory=32000) pour exécuter la fonction sur une instance suffisamment puissante.
Analyse de sentiment avec un LLM
Avec les fils de commentaires à notre disposition, nous avons pu les traiter avec notre LLM en utilisant cette demande :
Sur une échelle de 0 à 10 où 0 représente le sentiment le plus négatif et 10 le plus positif, classez la discussion suivante.
Répondez dans ce format :
SENTIMENT X
où X est la note de sentiment
---
[Premiers 3000 tokens d'un fil de commentaires]Obtenir une sortie structurée simple comme celle-ci semble fonctionner sans problème. Nous avons traité environ 230 millions de tokens d’entrée de cette manière, ce qui n’a pris qu’environ 7 heures, car nous n’avions besoin que de deux tokens de sortie.
Vous pouvez reproduire toutes les étapes ci-dessus en utilisant votre chaîne d’outils préférée. Voici quelques raisons clés pour lesquelles nous avons choisi Metaflow et pourquoi vous pourriez également envisager de l’utiliser :
-
Organisation sans effort : Un avantage majeur par rapport aux scripts Python aléatoires ou aux notebooks est que Metaflow conserve automatiquement tous les artefacts, suit toutes les exécutions et garde tout organisé. Nous avons utilisé les espaces de noms de Metaflow pour exécuter des runs coûteux et importants aux côtés de prototypes, sachant que les deux ne peuvent pas interférer l’un avec l’autre. Nous avons utilisé des étiquettes Metaflow pour organiser le partage de données entre les flux pendant leur développement indépendant.
-
Scalabilité facile dans le cloud : Le crawling nécessitait une scalabilité horizontale, DuckDB nécessitait une scalabilité verticale, et les LLM nécessitaient un backend GPU. Metaflow a géré tous ces cas sans effort.
-
Orchestrateur hautement disponible : Exécuter un grand ensemble de données à travers un LLM peut coûter des milliers de dollars. Vous ne voulez pas que l’exécution échoue à cause de problèmes aléatoires. Nous avons compté sur un orchestrateur Argo Workflows hautement disponible que Metaflow prend en charge par défaut pour maintenir l’exécution pendant des heures.
Vous pouvez réaliser tout cela en utilisant Metaflow en open-source, mais nous avons bénéficié de quelques avantages supplémentaires en exécutant les flux sur la plateforme Outerbounds : il est tout simplement agréable de développer du code comme celui-ci, y compris des notebooks, avec VSCode fonctionnant sur des stations de travail cloud, la montée en charge vers le cloud est fluide, et @nim nous a permis d’accéder aux LLM sans nous soucier des coûts ou des limitations de taux.
Explorez davantage à domicile
Il y a beaucoup plus à analyser et à visualiser avec cet ensemble de données. Au lieu de dépenser quelques milliers de dollars à utiliser les API d’OpenAI, vous pouvez télécharger les sujets et les sentiments que nous avons créés :
post-sentiment.jsoncontient une correspondancepost_id -> sentiment_scorepost-topics.jsoncontient une correspondancepost_id -> [sujets]topics-data.jsoncontient un ensemble de données nettoyé et joint basé sur les JSON ci-dessus, alimentant l’outil au début de cet article.
Vous pouvez trouver des métadonnées liées aux ID de post dans cet ensemble de données HuggingFace et dans l’ensemble de données Google BigQuery Hacker News. Pour voir les posts, ouvrez simplement https://news.ycombinator.com/item?id=[post_id[post_id].
Par exemple, il serait intéressant d’explorer la corrélation entre les domaines des posts et les sentiments et sujets. Nous avons l’intuition que certains domaines produisent des sentiments majoritairement positifs et vice versa. Ou, les sujets divisifs obtiennent-ils plus de points ?
Si vous créez quelque chose d’intéressant avec ces données, n’hésitez pas à faire un lien vers cet article de blog et à nous le faire savoir ! Rejoignez Metaflow Slack et laissez un message sur #ask-metaflow.
Pour soutenir nos efforts open-source, n’hésitez pas à donner une étoile à Metaflow !






Général
Anker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
Découvrez le Solarbank 2 AC, une véritable révolution dans le domaine de l’énergie solaire ! Grâce à ses batteries au phosphate de fer lithium, ce système s’adapte parfaitement à vos besoins. Avec une puissance impressionnante de 2400 watts et la possibilité d’ajouter jusqu’à cinq batteries supplémentaires, il assure un stockage optimal. Sa compatibilité avec le compteur Anker SOLIX Smart favorise une gestion intelligente de votre consommation énergétique. Ne ratez pas l’offre spéciale « early bird », disponible dès maintenant pour seulement 999 euros ! Saisissez cette chance unique !

Le Solarbank 2 AC : Une Révolution dans le Stockage Énergétique
Batteries au Lithium Fer Phosphate
Le Solarbank 2 AC se démarque par l’utilisation de batteries au lithium fer phosphate (LFP), reconnues pour leur sécurité et leur efficacité. Ce modèle est particulièrement innovant grâce à son système de couplage alternatif, qui lui permet de s’adapter facilement à divers systèmes solaires déjà en place.Que ce soit pour des installations sur toiture, des systèmes solaires compacts pour balcons ou d’autres configurations réduites, il peut fonctionner avec un micro-onduleur de 800 Watts.
Capacité et flexibilité Énergétique
Avec une capacité maximale d’injection dans le réseau domestique atteignant 1200 watts,le Solarbank 2 AC peut être associé à deux régulateurs solaires MPPT. Cela ouvre la possibilité d’ajouter jusqu’à 1200 watts supplémentaires via des panneaux solaires additionnels, portant ainsi la puissance totale à un impressionnant 2400 watts. Pour les utilisateurs nécessitant davantage de stockage énergétique, il est possible d’intégrer jusqu’à cinq batteries supplémentaires de 1,6 kilowattheure chacune, augmentant la capacité totale à 9,6 kilowattheures.
Intégration dans un Écosystème Intelligent
Le Solarbank 2 AC s’intègre parfaitement dans un écosystème énergétique intelligent grâce à sa compatibilité avec le compteur Anker SOLIX Smart et les prises intelligentes proposées par Anker. cette fonctionnalité permet une gestion optimisée de la consommation électrique tout en réduisant les pertes énergétiques inutiles. De plus, Anker SOLIX prévoit d’étendre cette compatibilité aux dispositifs Shelly.
Durabilité et Résistance aux Intempéries
Anker SOLIX met également l’accent sur la longévité du Solarbank 2 AC. Conçu pour supporter au moins 6000 cycles de charge, cet appareil a une durée de vie estimée dépassant quinze ans. Il est accompagné d’une garantie fabricant décennale et possède une certification IP65 qui assure sa résistance face aux intempéries tout en étant capable de fonctionner dans des températures variant entre -20 °C et +55 °C.
Disponibilité et Offres Promotionnelles
Le solarbank 2 AC est disponible sur le site officiel d’Anker SOLIX ainsi que sur Amazon au prix standard de 1299 euros. Cependant, une offre promotionnelle « early bird » sera active du 20 janvier au 23 février 2025, permettant aux acheteurs intéressés d’acquérir cet appareil dès 999 euros ! Cette promotion inclut également un compteur Anker SOLIX Smart offert pour chaque commande passée durant cette période spéciale.
le Solarbank 2 AC représente une avancée significative dans le domaine du stockage énergétique domestique grâce à ses caractéristiques techniques avancées et son engagement envers la durabilité environnementale.
Technologie
Ne manquez pas cette offre incroyable : le Air Fryer Moulinex Easy Fry Max à -42% sur Amazon !
Les soldes d’hiver sont là ! Ne ratez pas l’incroyable offre d’Amazon sur le Moulinex Easy Fry Max, à seulement 69 euros au lieu de 119 euros, soit une réduction sensationnelle de -42% ! Avec sa capacité généreuse de 5 L, cette friteuse sans huile est idéale pour régaler jusqu’à 6 convives. Grâce à ses 10 programmes de cuisson et son interface tactile intuitive, préparez des plats sains et savoureux en un clin d’œil. Dépêchez-vous, les stocks s’épuisent vite et cette offre est limitée dans le temps !

Technologie
Les soldes d’hiver sont en cours, et Amazon en profite pour offrir des promotions intéressantes, notamment sur les friteuses à air. Actuellement, le Moulinex Easy Fry Max est proposé à un prix attractif de 69 euros au lieu de 119 euros, ce qui représente une réduction immédiate de 42 %. C’est une occasion parfaite pour acquérir une friteuse sans huile XL d’une capacité généreuse de 5 L, idéale pour préparer des repas pour jusqu’à six personnes à un tarif très compétitif.
Étant donné que cette offre est limitée dans le temps,il est conseillé d’agir rapidement si vous souhaitez en bénéficier. De plus, avec un tel prix, les stocks pourraient s’épuiser rapidement. Ce modèle se classe parmi les meilleures ventes sur Amazon avec plus de 1000 unités écoulées le mois dernier.
Profitez des offres sur Amazon
Amazon propose également la livraison gratuite et rapide pour cet article qui bénéficie d’une garantie de deux ans. En outre, il existe une option de paiement échelonné en quatre fois sans frais sur ce modèle. Enfin, sachez que vous avez la possibilité de changer d’avis et retourner le produit gratuitement dans un délai de 30 jours afin d’obtenir un remboursement intégral.
Moulinex Easy Fry Max : cuisinez sainement pour toute la famille
Le moulinex Easy Fry Max fonctionne comme un four à air chaud permettant la préparation de plats savoureux tout en utilisant peu ou pas du tout d’huile. En plus des frites croustillantes qu’il réalise parfaitement, cet appareil se révèle très polyvalent et peut cuisiner une multitude d’autres recettes.
avec ses dix programmes prédéfinis adaptés à divers ingrédients tels que poulet,steak,poisson ou légumes ainsi que des options pour bacon et desserts comme les pizzas ,cet appareil répond aux besoins variés des familles modernes. De plus, Moulinex met à disposition un livre numérique rempli de recettes accessible via QR Code afin que vous puissiez facilement trouver l’inspiration culinaire lorsque nécessaire.
Sa capacité généreuse permet non seulement la préparation rapide mais aussi économique : jusqu’à 70 % moins énergivore et presque deux fois plus rapide qu’un four traditionnel ! Son interface intuitive avec écran tactile facilite son utilisation quotidienne.
en outre, le panier antiadhésif compatible lave-vaisselle simplifie grandement l’entretien après chaque utilisation. N’oubliez pas qu’il s’agit là encore d’une offre temporaire ; ne tardez donc pas si vous souhaitez profiter du meilleur prix possible sur cette friteuse innovante !
Pour accéder à cette remise exceptionnelle :
Technologie
TikTok revient en force aux États-Unis, mais pas sur l’App Store !
Le suspense autour de TikTok est à son comble ! En avril 2024, le Congrès américain a voté une loi obligeant l’application à changer de propriétaire avant le 19 janvier. Les utilisateurs ont anxieusement attendu la décision finale. Bien que TikTok ait brièvement cessé ses activités, elle est revenue en ligne, mais absente de l’App Store. Apple justifie cette décision par des obligations légales. Cependant, les utilisateurs peuvent toujours accéder à leur compte… sans mises à jour. L’avenir de TikTok pourrait prendre un tournant décisif avec les promesses du nouveau président.

Technologie
En avril 2024, le Congrès américain a adopté une législation obligeant TikTok à trouver un nouvel acquéreur, ByteDance étant accusé d’activités d’espionnage. Les utilisateurs de l’submission aux États-Unis ont donc attendu avec impatience le week-end précédent la date limite du 19 janvier pour savoir si TikTok serait interdit dans le pays.
Bien que TikTok n’ait pas réussi à dénicher un repreneur avant cette échéance, l’application a temporairement suspendu ses activités… mais seulement pour quelques heures. le réseau social est désormais de retour en ligne, mais il n’est plus accessible sur l’App Store.
Retour de TikTok : Une Absence Persistante sur l’App Store
Apple a expliqué sa décision de retirer TikTok de son App store par un communiqué officiel. « Apple doit respecter les lois en vigueur dans les régions où elle opère. Selon la loi Protecting Americans from Foreign Adversary Controlled Applications act, les applications développées par ByteDance ltd., y compris TikTok et ses filiales comme CapCut et Lemon8, ne pourront plus être téléchargées ou mises à jour sur l’App Store pour les utilisateurs américains après le 19 janvier 2025 », précise la société.
Il est crucial de souligner que les utilisateurs américains ayant déjà installé TikTok peuvent toujours accéder au service. Cependant, ils ne recevront plus aucune mise à jour future de l’application. L’avenir du réseau social pourrait dépendre des décisions du nouveau président des États-Unis.
DÉCLARATION DE TIKTOK :
>
En collaboration avec nos partenaires techniques, nous travaillons activement à rétablir notre service. Nous remercions le président Trump pour avoir clarifié la situation et rassuré nos partenaires qu’ils ne subiront aucune sanction en continuant d’offrir TikTok aux plus de 170 millions d’utilisateurs…
Le successeur de Joe Biden sera investi comme président ce lundi 20 janvier et prévoit d’émettre un décret afin d’accorder un délai supplémentaire à TikTok pour trouver un acquéreur potentiel.Donald Trump propose même que les États-Unis détiennent une participation significative dans cette application.
« Je souhaite que les États-Unis possèdent une part importante dans une coentreprise avec cet outil numérique afin que nous puissions préserver son intégrité tout en lui permettant d’évoluer […]. Ainsi,notre pays détiendrait la moitié des parts dans une coentreprise établie entre nous et tout acheteur sélectionné »,a déclaré Donald Trump.
L’avenir immédiat de TikTok pourrait donc connaître des évolutions majeures très prochainement. Il convient également de noter qu’une rumeur circulait selon laquelle Elon Musk envisagerait d’acquérir des parts dans la plateforme,mais celle-ci a été rapidement démentie par un porte-parole officiel.
-
 Business2 ans ago
Business2 ans agoComment lutter efficacement contre le financement du terrorisme au Nigeria : le point de vue du directeur de la NFIU
-
 Général2 ans ago
Général2 ans agoX (anciennement Twitter) permet enfin de trier les réponses sur iPhone !
-

 Technologie1 an ago
Technologie1 an agoTikTok revient en force aux États-Unis, mais pas sur l’App Store !
-

 Général1 an ago
Général1 an agoAnker SOLIX dévoile la Solarbank 2 AC : la nouvelle ère du stockage d’énergie ultra-compatible !
-
 Général1 an ago
Général1 an agoLa Gazelle de Val (405) : La Star Incontournable du Quinté d’Aujourd’hui !
-
 Sport1 an ago
Sport1 an agoSaisissez les opportunités en or ce lundi 20 janvier 2025 !
-

 Business1 an ago
Business1 an agoUne formidable nouvelle pour les conducteurs de voitures électriques !
-

 Science et nature1 an ago
Science et nature1 an agoLes meilleures offres du MacBook Pro ce mois-ci !