

Dans le domaine de l’intelligence artificielle, une nouvelle excitation entoure le lancement du modèle de langage Meta AI est désormais disponible en espagnol, portugais, français et bien plus encore ! »>Llama 3.1 405B par Meta, annoncé mardi. Pour la première fois, il est possible de télécharger gratuitement un modèle de langage de classe GPT-4 et de l’exécuter sur son propre matériel. Bien que cela nécessite un équipement puissant, Meta précise qu’il peut fonctionner sur un « nœud de serveur unique », ce qui n’est pas à la portée d’un PC de bureau classique. Cela représente un défi significatif pour les fournisseurs de modèles d’IA « fermés » comme OpenAI et Anthropic.
Meta affirme que « Llama 3.1 405B est le premier modèle ouvert qui rivalise avec les meilleurs modèles d’IA en matière de capacités de pointe en connaissances générales, d’orientabilité, de mathématiques, d’utilisation d’outils et de traduction multilingue. » Le PDG de l’entreprise, Mark Zuckerberg, qualifie le 405B de « premier modèle d’IA open source de niveau frontière. »
Dans le secteur de l’IA, le terme « modèle de frontière » désigne un système d’IA conçu pour repousser les limites des capacités actuelles. Meta positionne ainsi le 405B aux côtés des modèles d’IA les plus performants, tels que GPT-4o d’OpenAI, Claude 3.5 Sonnet et Google Gemini 1.5 Pro.
Un graphique publié par Meta indique que le 405B se rapproche des performances de GPT-4 Turbo, GPT-4o et Claude 3.5 Sonnet dans des benchmarks tels que MMLU (connaissances de niveau universitaire), GSM8K (mathématiques de l’école primaire) et HumanEval (programmation).
Cependant, comme nous l’avons souligné à plusieurs reprises depuis mars, ces benchmarks ne sont pas nécessairement scientifiquement valables et ne reflètent pas l’expérience subjective d’interaction avec les modèles de langage IA. En fait, cette série traditionnelle de benchmarks est si peu utile pour le grand public que même le département de communication de Meta a simplement publié quelques images de graphiques numériques sans tenter d’expliquer leur signification en détail.
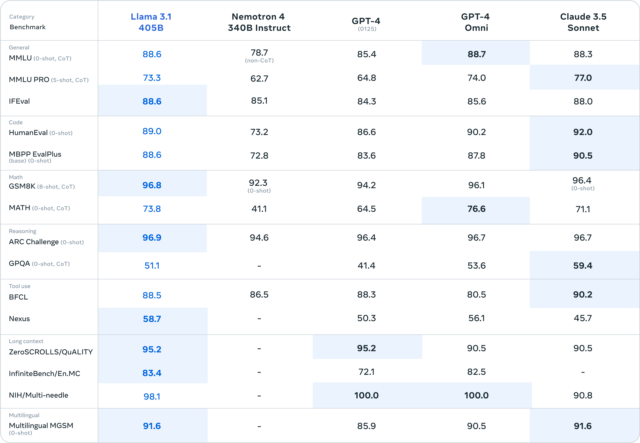
Agrandir / Un graphique fourni par Meta montrant les résultats de benchmark de Llama 3.1 405B par rapport à d’autres modèles d’IA majeurs.
Nous avons plutôt constaté que mesurer l’expérience subjective d’utilisation d’un modèle d’IA conversationnelle (ce que l’on pourrait appeler « vibemarking ») sur des classements A/B comme Chatbot Arena est une meilleure méthode pour évaluer les nouveaux LLM. En l’absence de données de Chatbot Arena, Meta a fourni les résultats de ses propres évaluations humaines des sorties du 405B, qui semblent montrer que le nouveau modèle de Meta se défend bien face à GPT-4 Turbo et Claude 3.5 Sonnet.
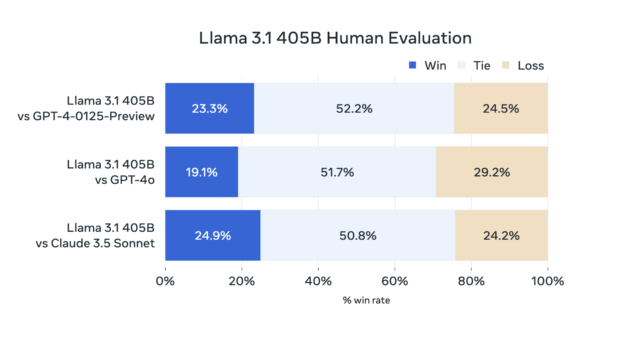
Agrandir / Un graphique fourni par Meta montrant comment les humains ont évalué les sorties de Llama 3.1 405B par rapport à GPT-4 Turbo, GPT-4o et Claude 3.5 Sonnet dans ses propres études.
Quoi qu’il en soit, les premières impressions (après que le modèle ait fuité sur 4chan hier) semblent corroborer l’affirmation selon laquelle le 405B est à peu près équivalent à GPT-4. Cela a nécessité beaucoup de temps d’entraînement informatique coûteux pour y parvenir, et Meta a investi massivement dans ce projet. Le modèle 405B a été formé sur plus de 15 trillions de tokens de données d’entraînement extraites du web (puis analysées, filtrées et annotées par Llama 2), en utilisant plus de 16 000 GPU H100.
Mais que signifie le nom 405B ? Dans ce cas, « 405B » fait référence à 405 milliards de paramètres, qui sont des valeurs numériques stockant des informations entraînées dans un réseau de neurones. Plus il y a de paramètres, plus le réseau de neurones qui alimente le modèle d’IA est grand, ce qui signifie généralement (mais pas toujours) une meilleure capacité à établir des connexions contextuelles entre les concepts. Cependant, les modèles avec un plus grand nombre de paramètres nécessitent également plus de puissance de calcul pour fonctionner.
Nous attendions la sortie d’un modèle de plus de 400 milliards de paramètres de la famille Llama 3 depuis que Meta a annoncé qu’il en formait un en avril. L’annonce d’aujourd’hui ne concerne pas seulement le plus grand membre de la famille Llama 3 : il y a également une toute nouvelle itération de modèles Llama améliorés désignée « Llama 3.1. » Cela inclut des versions mises à jour de ses modèles plus petits de 8B et 70B, qui disposent désormais d’un support multilingue et d’une longueur de contexte étendue de 128 000 tokens (la « longueur de contexte » correspond à la capacité de mémoire de travail du modèle, et les « tokens » sont des morceaux de données utilisés par les LLM pour traiter l’information).
Meta indique que le 405B est utile pour la synthèse de textes longs, les agents conversationnels multilingues, les assistants de codage et pour créer des données synthétiques utilisées pour former de futurs modèles de langage IA. Notamment, ce dernier cas d’utilisation — permettant aux développeurs d’utiliser les sorties des modèles Llama pour améliorer d’autres modèles d’IA — est désormais officiellement soutenu par la licence Llama 3.1 de Meta pour la première fois.
Une utilisation abusive du terme « open source »
Llama 3.1 405B est un modèle à poids ouverts, ce qui signifie que tout le monde peut télécharger les fichiers du réseau de neurones entraîné et les exécuter ou les affiner. Cela remet directement en question un modèle commercial où des entreprises comme OpenAI conservent les poids pour elles-mêmes et monétisent plutôt le modèle via des abonnements comme ChatGPT ou facturent l’accès par token via une API.
Pour Mark Zuckerberg, combattre les modèles d’IA « fermés » est crucial. Il a également publié aujourd’hui un manifeste de 2 300 mots expliquant pourquoi l’entreprise croit en la libération ouverte des modèles d’IA, intitulé « L’IA Open Source est l’Avenir. » Plus de détails sur la terminologie dans un instant. Mais brièvement, il évoque la nécessité de modèles d’IA personnalisables qui offrent un contrôle aux utilisateurs et favorisent une meilleure sécurité des données, une plus grande rentabilité et une meilleure pérennité, contrairement aux solutions verrouillées par les fournisseurs.
Tout cela semble raisonnable, mais perturber vos concurrents avec un modèle subventionné par un budget de médias sociaux est également une manière efficace de jouer les trouble-fêtes sur un marché où vous ne pouvez pas toujours gagner avec la technologie la plus avancée. Les libérations ouvertes de modèles d’IA profitent à Meta, selon Zuckerberg, car il ne veut pas être enfermé dans un système où des entreprises comme la sienne doivent payer un péage pour accéder aux capacités d’IA, comparant cela à des « taxes » qu’Apple impose aux développeurs via son App Store.
Agrandir / Une capture d’écran de l’essai de Mark Zuckerberg, « L’IA Open Source est l’Avenir, » publié le 23 juillet 2024.
Concernant le terme « open source », comme nous l’avons d’abord mentionné dans une mise à jour de notre article sur le lancement de Llama 2 l’année dernière, « open source » a une signification très précise qui a été traditionnellement définie par l’Open Source Initiative. L’industrie de l’IA n’a pas encore établi de terminologie pour les libérations de modèles d’IA qui expédient soit du code, soit des poids avec des restrictions (comme Llama 3.1) ou qui expédient sans fournir de données d’entraînement. Nous avons commencé à appeler ces libérations « poids ouverts » à la place.
Malheureusement pour les puristes de la terminologie, Zuckerberg a maintenant intégré l’étiquette erronée « open source » dans le titre de son essai potentiellement historique mentionné précédemment sur les libérations d’IA ouvertes, donc se battre pour le terme correct dans l’IA pourrait être une bataille perdue. Néanmoins, son utilisation agace des personnes comme le chercheur indépendant en IA Simon Willison, qui apprécie par ailleurs l’essai de Zuckerberg.
« Je considère l’utilisation abusive du terme ‘open source’ par Zuck comme un acte de vandalisme culturel à petite échelle, » a déclaré Willison à Ars Technica. « L’open source devrait avoir une signification convenue. L’abus de ce terme en affaiblit le sens, ce qui le rend moins utile en général, car si quelqu’un dit ‘c’est open source’, cela ne me dit plus rien d’utile. Je dois alors creuser pour comprendre de quoi il s’agit réellement. »
Les modèles Llama 3.1 sont disponibles en téléchargement sur le site de Meta et sur Hugging Face. Les deux nécessitent de fournir des informations de contact et d’accepter une licence ainsi qu’une politique d’utilisation acceptable, ce qui signifie que Meta peut techniquement retirer votre accès à Llama 3.1 ou à ses sorties à tout moment.

















